 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransLight: Image-Guided Customized Lighting Control with Generative Decoupling
Aug 20, 2025Most existing illumination-editing approaches fail to simultaneously provide customized control of light effects and preserve content integrity. This makes them less effective for practical lighting stylization requirements, especially in the challenging task of transferring complex light effects from a reference image to a user-specified target image. To address this problem, we propose TransLight, a novel framework that enables high-fidelity and high-freedom transfer of light effects. Extracting the light effect from the reference image is the most critical and challenging step in our method. The difficulty lies in the complex geometric structure features embedded in light effects that are highly coupled with content in real-world scenarios. To achieve this, we first present Generative Decoupling, where two fine-tuned diffusion models are used to accurately separate image content and light effects, generating a newly curated, million-scale dataset of image-content-light triplets. Then, we employ IC-Light as the generative model and train our model with our triplets, injecting the reference lighting image as an additional conditioning signal. The resulting TransLight model enables customized and natural transfer of diverse light effects. Notably, by thoroughly disentangling light effects from reference images, our generative decoupling strategy endows TransLight with highly flexible illumination control. Experimental results establish TransLight as the first method to successfully transfer light effects across disparate images, delivering more customized illumination control than existing techniques and charting new directions for research in illumination harmonization and editing.
LENS: Learning to Segment Anything with Unified Reinforced Reasoning
Aug 19, 2025Text-prompted image segmentation enables fine-grained visual understanding and is critical for applications such as human-computer interaction and robotics. However, existing supervised fine-tuning methods typically ignore explicit chain-of-thought (CoT) reasoning at test time, which limits their ability to generalize to unseen prompts and domains. To address this issue, we introduce LENS, a scalable reinforcement-learning framework that jointly optimizes the reasoning process and segmentation in an end-to-end manner. We propose unified reinforcement-learning rewards that span sentence-, box-, and segment-level cues, encouraging the model to generate informative CoT rationales while refining mask quality. Using a publicly available 3-billion-parameter vision-language model, i.e., Qwen2.5-VL-3B-Instruct, LENS achieves an average cIoU of 81.2% on the RefCOCO, RefCOCO+, and RefCOCOg benchmarks, outperforming the strong fine-tuned method, i.e., GLaMM, by up to 5.6%. These results demonstrate that RL-driven CoT reasoning serves as a robust prior for text-prompted segmentation and offers a practical path toward more generalizable Segment Anything models. Code is available at https://github.com/hustvl/LENS.
ControlAR: Controllable Image Generation with Autoregressive Models
Oct 03, 2024



Autoregressive (AR) models have reformulated image generation as next-token prediction, demonstrating remarkable potential and emerging as strong competitors to diffusion models. However, control-to-image generation, akin to ControlNet, remains largely unexplored within AR models. Although a natural approach, inspired by advancements in Large Language Models, is to tokenize control images into tokens and prefill them into the autoregressive model before decoding image tokens, it still falls short in generation quality compared to ControlNet and suffers from inefficiency. To this end, we introduce ControlAR, an efficient and effective framework for integrating spatial controls into autoregressive image generation models. Firstly, we explore control encoding for AR models and propose a lightweight control encoder to transform spatial inputs (e.g., canny edges or depth maps) into control tokens. Then ControlAR exploits the conditional decoding method to generate the next image token conditioned on the per-token fusion between control and image tokens, similar to positional encodings. Compared to prefilling tokens, using conditional decoding significantly strengthens the control capability of AR models but also maintains the model's efficiency. Furthermore, the proposed ControlAR surprisingly empowers AR models with arbitrary-resolution image generation via conditional decoding and specific controls. Extensive experiments can demonstrate the controllability of the proposed ControlAR for the autoregressive control-to-image generation across diverse inputs, including edges, depths, and segmentation masks. Furthermore, both quantitative and qualitative results indicate that ControlAR surpasses previous state-of-the-art controllable diffusion models, e.g., ControlNet++. Code, models, and demo will soon be available at https://github.com/hustvl/ControlAR.
Efficient Test-Time Prompt Tuning for Vision-Language Models
Aug 11, 2024



Vision-language models have showcased impressive zero-shot classification capabilities when equipped with suitable text prompts. Previous studies have shown the effectiveness of test-time prompt tuning; however, these methods typically require per-image prompt adaptation during inference, which incurs high computational budgets and limits scalability and practical deployment. To overcome this issue, we introduce Self-TPT, a novel framework leveraging Self-supervised learning for efficient Test-time Prompt Tuning. The key aspect of Self-TPT is that it turns to efficient predefined class adaptation via self-supervised learning, thus avoiding computation-heavy per-image adaptation at inference. Self-TPT begins by co-training the self-supervised and the classification task using source data, then applies the self-supervised task exclusively for test-time new class adaptation. Specifically, we propose Contrastive Prompt Learning (CPT) as the key task for self-supervision. CPT is designed to minimize the intra-class distances while enhancing inter-class distinguishability via contrastive learning. Furthermore, empirical evidence suggests that CPT could closely mimic back-propagated gradients of the classification task, offering a plausible explanation for its effectiveness. Motivated by this finding, we further introduce a gradient matching loss to explicitly enhance the gradient similarity. We evaluated Self-TPT across three challenging zero-shot benchmarks. The results consistently demonstrate that Self-TPT not only significantly reduces inference costs but also achieves state-of-the-art performance, effectively balancing the efficiency-efficacy trade-off.
DPL: Decoupled Prompt Learning for Vision-Language Models
Aug 19, 2023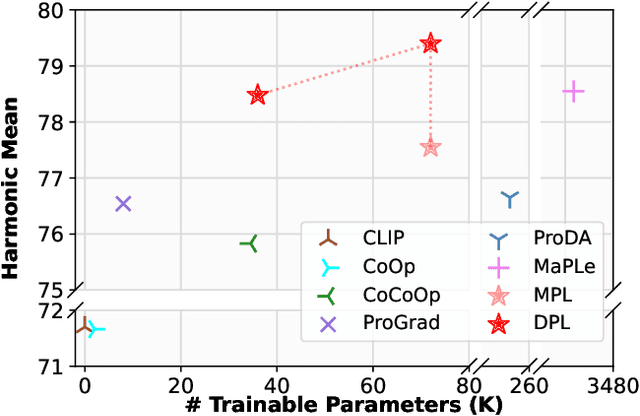
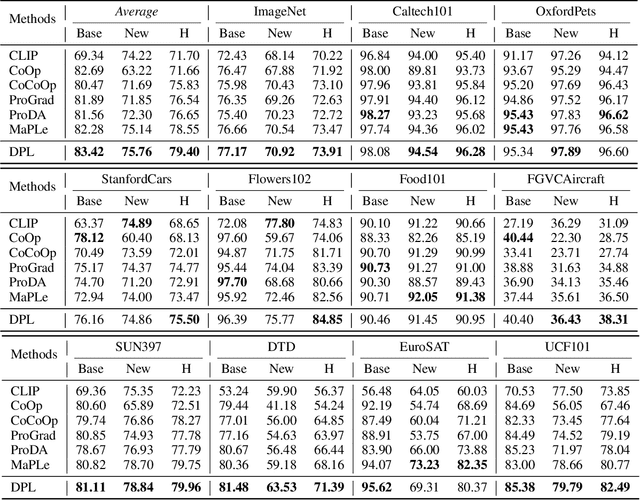
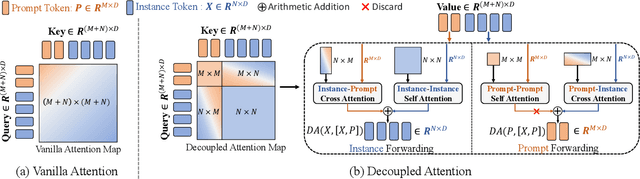
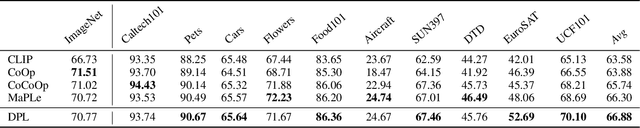
Prompt learning has emerged as an efficient and effective approach for transferring foundational Vision-Language Models (e.g., CLIP) to downstream tasks. However, current methods tend to overfit to seen categories, thereby limiting their generalization ability for unseen classes. In this paper, we propose a new method, Decoupled Prompt Learning (DPL), which reformulates the attention in prompt learning to alleviate this problem. Specifically, we theoretically investigate the collaborative process between prompts and instances (i.e., image patches/text tokens) by reformulating the original self-attention into four separate sub-processes. Through detailed analysis, we observe that certain sub-processes can be strengthened to bolster robustness and generalizability by some approximation techniques. Furthermore, we introduce language-conditioned textual prompting based on decoupled attention to naturally preserve the generalization of text input. Our approach is flexible for both visual and textual modalities, making it easily extendable to multi-modal prompt learning. By combining the proposed techniques, our approach achieves state-of-the-art performance on three representative benchmarks encompassing 15 image recognition datasets, while maintaining parameter-efficient. Moreover, our DPL does not rely on any auxiliary regularization task or extra training data, further demonstrating its remarkable generalization ability.
Progressive Visual Prompt Learning with Contrastive Feature Re-formation
Apr 17, 2023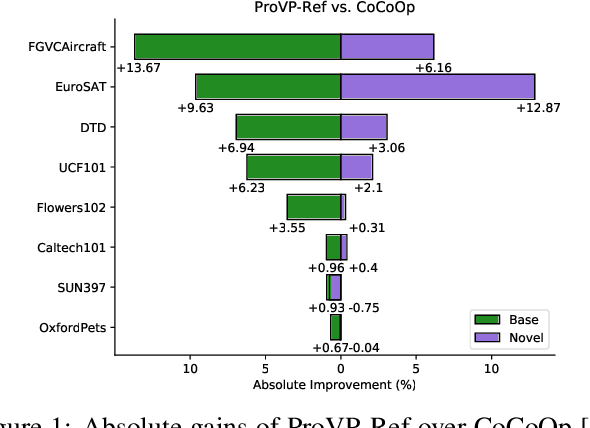
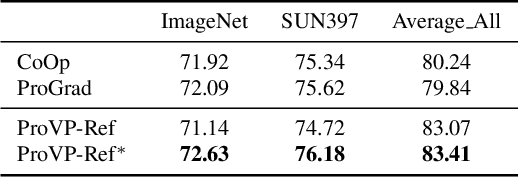
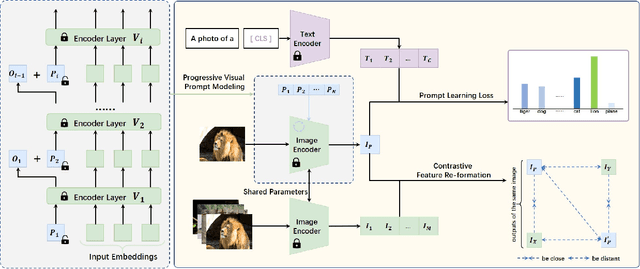
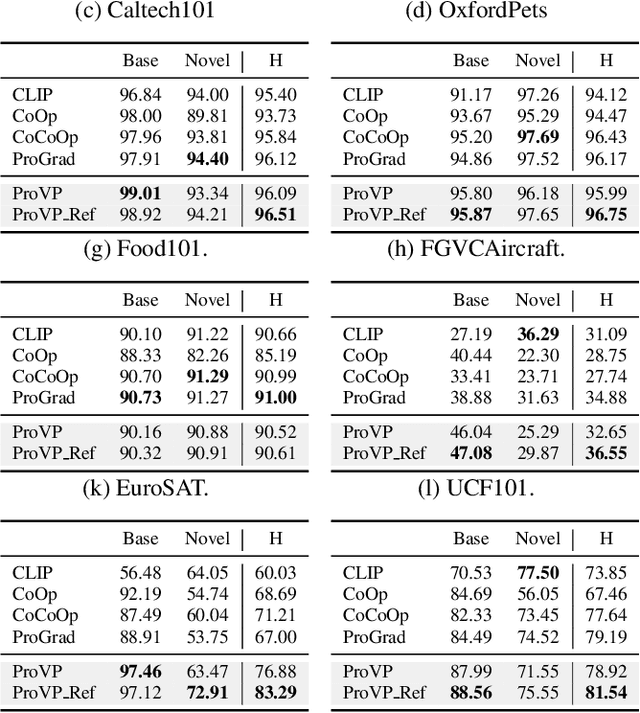
Prompt learning has been designed as an alternative to fine-tuning for adapting Vision-language (V-L) models to the downstream tasks. Previous works mainly focus on text prompt while visual prompt works are limited for V-L models. The existing visual prompt methods endure either mediocre performance or unstable training process, indicating the difficulty of visual prompt learning. In this paper, we propose a new Progressive Visual Prompt (ProVP) structure to strengthen the interactions among prompts of different layers. More importantly, our ProVP could effectively propagate the image embeddings to deep layers and behave partially similar to an instance adaptive prompt method. To alleviate generalization deterioration, we further propose a new contrastive feature re-formation, which prevents the serious deviation of the prompted visual feature from the fixed CLIP visual feature distribution. Combining both, our method (ProVP-Ref) is evaluated on 11 image benchmark datasets and achieves 7/11 state-of-theart results on both few-shot and base-to-novel settings. To the best of our knowledge, we are the first to demonstrate the superior performance of visual prompts in V-L models to previous prompt-based methods in downstream tasks. Meanwhile, it implies that our ProVP-Ref shows the best capability to adapt and to generalize.
Microscope Based HER2 Scoring System
Sep 15, 2020

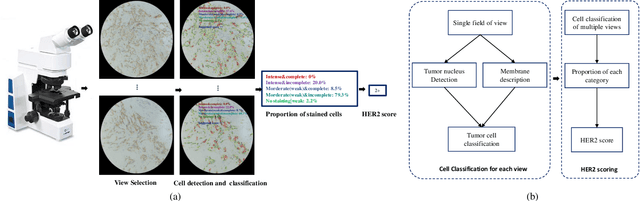
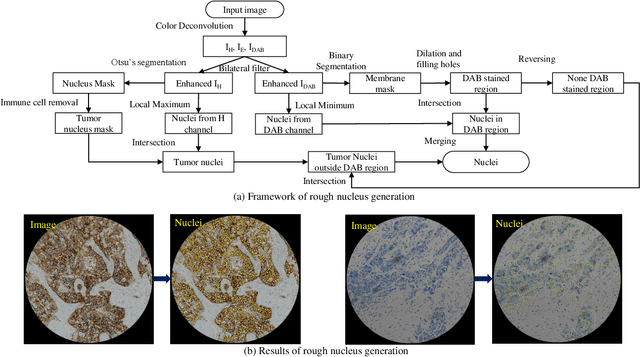
The overexpression of human epidermal growth factor receptor 2 (HER2) has been established as a therapeutic target in multiple types of cancers, such as breast and gastric cancers. Immunohistochemistry (IHC) is employed as a basic HER2 test to identify the HER2-positive, borderline, and HER2-negative patients. However, the reliability and accuracy of HER2 scoring are affected by many factors, such as pathologists' experience. Recently, artificial intelligence (AI) has been used in various disease diagnosis to improve diagnostic accuracy and reliability, but the interpretation of diagnosis results is still an open problem. In this paper, we propose a real-time HER2 scoring system, which follows the HER2 scoring guidelines to complete the diagnosis, and thus each step is explainable. Unlike the previous scoring systems based on whole-slide imaging, our HER2 scoring system is integrated into an augmented reality (AR) microscope that can feedback AI results to the pathologists while reading the slide. The pathologists can help select informative fields of view (FOVs), avoiding the confounding regions, such as DCIS. Importantly, we illustrate the intermediate results with membrane staining condition and cell classification results, making it possible to evaluate the reliability of the diagnostic results. Also, we support the interactive modification of selecting regions-of-interest, making our system more flexible in clinical practice. The collaboration of AI and pathologists can significantly improve the robustness of our system. We evaluate our system with 285 breast IHC HER2 slides, and the classification accuracy of 95\% shows the effectiveness of our HER2 scoring system.