 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlueLM-V-3B: Algorithm and System Co-Design for Multimodal Large Language Models on Mobile Devices
Nov 16, 2024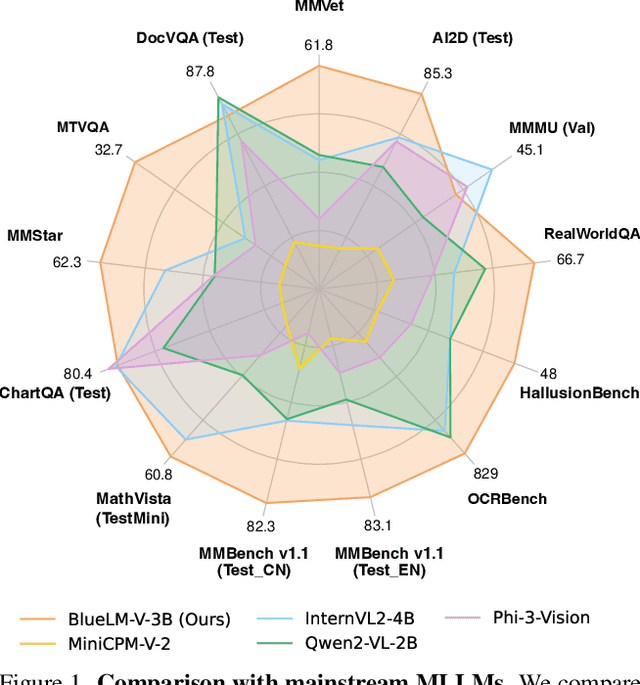
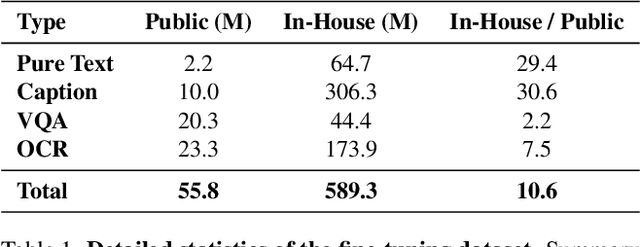
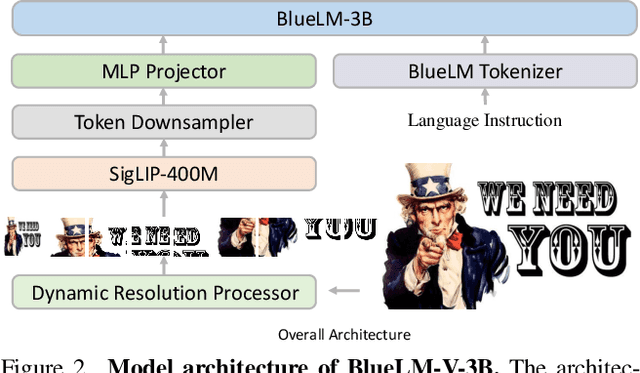

The emergence and growing popularity of multimodal large language models (MLLMs) have significant potential to enhance various aspects of daily life, from improving communication to facilitating learning and problem-solving. Mobile phones, as essential daily companions, represent the most effective and accessible deployment platform for MLLMs, enabling seamless integration into everyday tasks. However, deploying MLLMs on mobile phones presents challenges due to limitations in memory size and computational capability, making it difficult to achieve smooth and real-time processing without extensive optimization. In this paper, we present BlueLM-V-3B, an algorithm and system co-design approach specifically tailored for the efficient deployment of MLLMs on mobile platforms. To be specific, we redesign the dynamic resolution scheme adopted by mainstream MLLMs and implement system optimization for hardware-aware deployment to optimize model inference on mobile phones. BlueLM-V-3B boasts the following key highlights: (1) Small Size: BlueLM-V-3B features a language model with 2.7B parameters and a vision encoder with 400M parameters. (2) Fast Speed: BlueLM-V-3B achieves a generation speed of 24.4 token/s on the MediaTek Dimensity 9300 processor with 4-bit LLM weight quantization. (3) Strong Performance: BlueLM-V-3B has attained the highest average score of 66.1 on the OpenCompass benchmark among models with $\leq$ 4B parameters and surpassed a series of models with much larger parameter sizes (e.g., MiniCPM-V-2.6, InternVL2-8B).
Progressive Visual Prompt Learning with Contrastive Feature Re-formation
Apr 17, 2023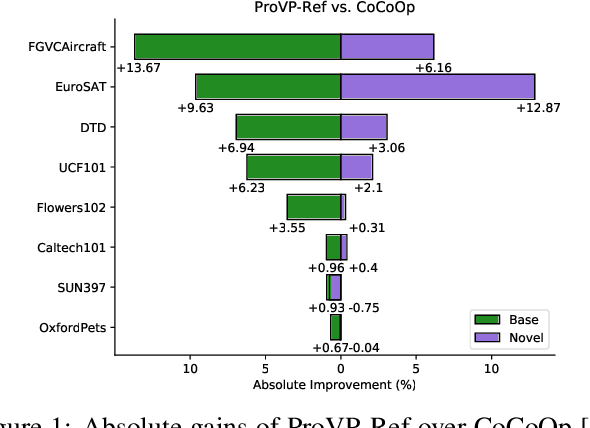
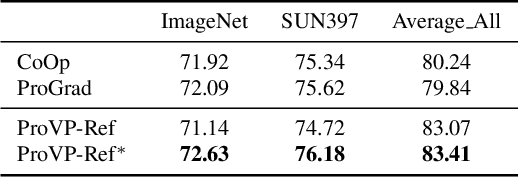
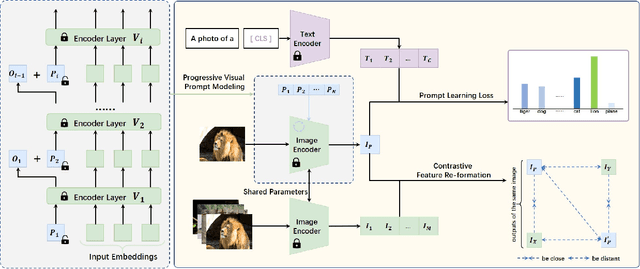
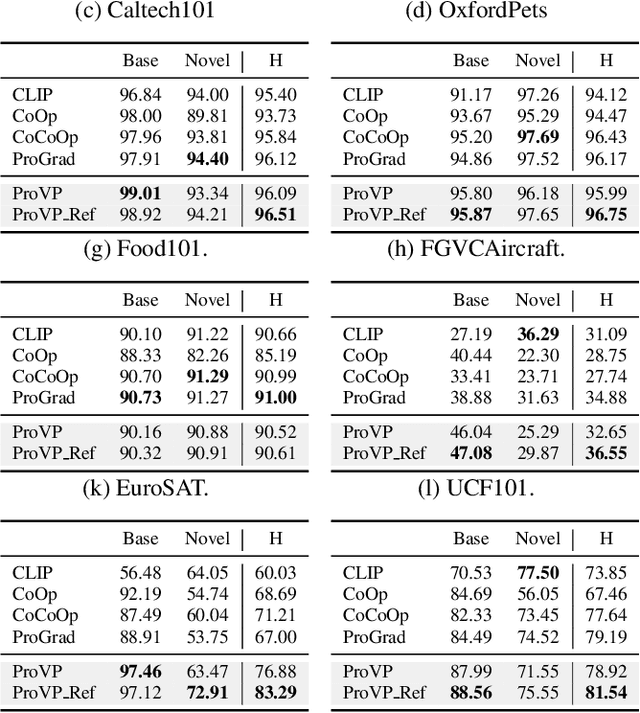
Prompt learning has been designed as an alternative to fine-tuning for adapting Vision-language (V-L) models to the downstream tasks. Previous works mainly focus on text prompt while visual prompt works are limited for V-L models. The existing visual prompt methods endure either mediocre performance or unstable training process, indicating the difficulty of visual prompt learning. In this paper, we propose a new Progressive Visual Prompt (ProVP) structure to strengthen the interactions among prompts of different layers. More importantly, our ProVP could effectively propagate the image embeddings to deep layers and behave partially similar to an instance adaptive prompt method. To alleviate generalization deterioration, we further propose a new contrastive feature re-formation, which prevents the serious deviation of the prompted visual feature from the fixed CLIP visual feature distribution. Combining both, our method (ProVP-Ref) is evaluated on 11 image benchmark datasets and achieves 7/11 state-of-theart results on both few-shot and base-to-novel settings. To the best of our knowledge, we are the first to demonstrate the superior performance of visual prompts in V-L models to previous prompt-based methods in downstream tasks. Meanwhile, it implies that our ProVP-Ref shows the best capability to adapt and to generalize.
Benchmarking Deep Deblurring Algorithms: A Large-Scale Multi-Cause Dataset and A New Baseline Model
Dec 01, 2021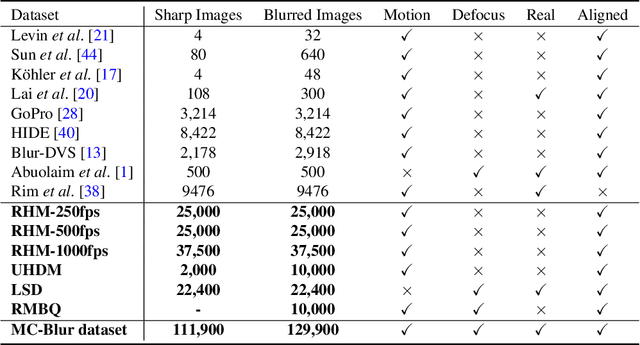
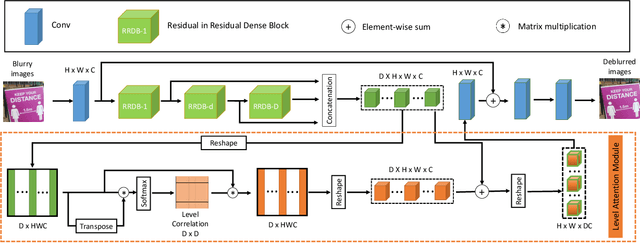

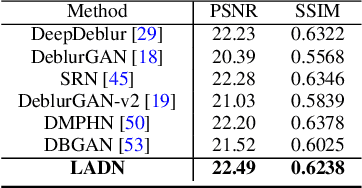
Blur artifacts can seriously degrade the visual quality of images, and numerous deblurring methods have been proposed for specific scenarios. However, in most real-world images, blur is caused by different factors, e.g., motion and defocus. In this paper, we address how different deblurring methods perform on general types of blur. For in-depth performance evaluation, we construct a new large-scale multi-cause image deblurring dataset called (MC-Blur) including real-world and synthesized blurry images with mixed factors of blurs. The images in the proposed MC-Blur dataset are collected using different techniques: convolving Ultra-High-Definition (UHD) sharp images with large kernels, averaging sharp images captured by a 1000 fps high-speed camera, adding defocus to images, and real-world blurred images captured by various camera models. These results provide a comprehensive overview of the advantages and limitations of current deblurring methods. Further, we propose a new baseline model, level-attention deblurring network, to adapt to multiple causes of blurs. By including different weights of attention to the different levels of features, the proposed network derives more powerful features with larger weights assigned to more important levels, thereby enhancing the feature representation. Extensive experimental results on the new dataset demonstrate the effectiveness of the proposed model for the multi-cause blur scenarios.