 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Visual Prompt Learning with Contrastive Feature Re-formation
Paper and Code
Apr 17, 2023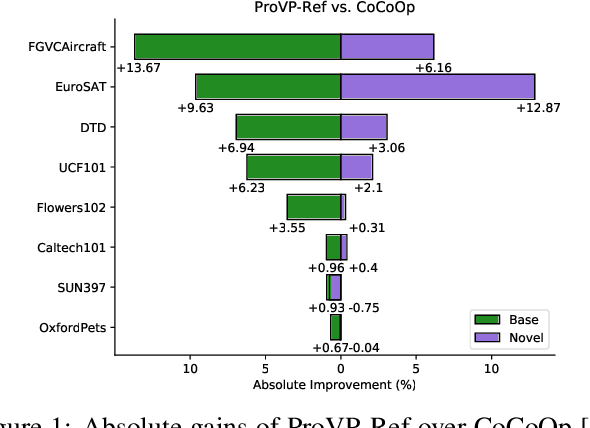
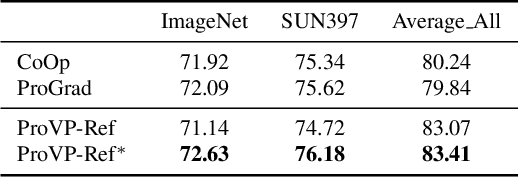
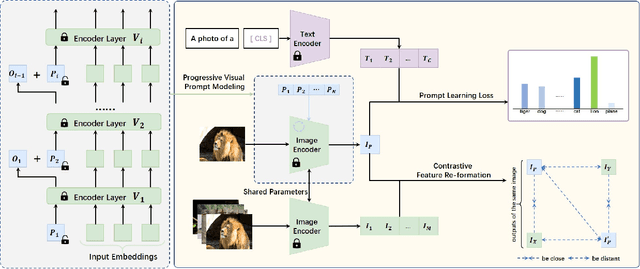
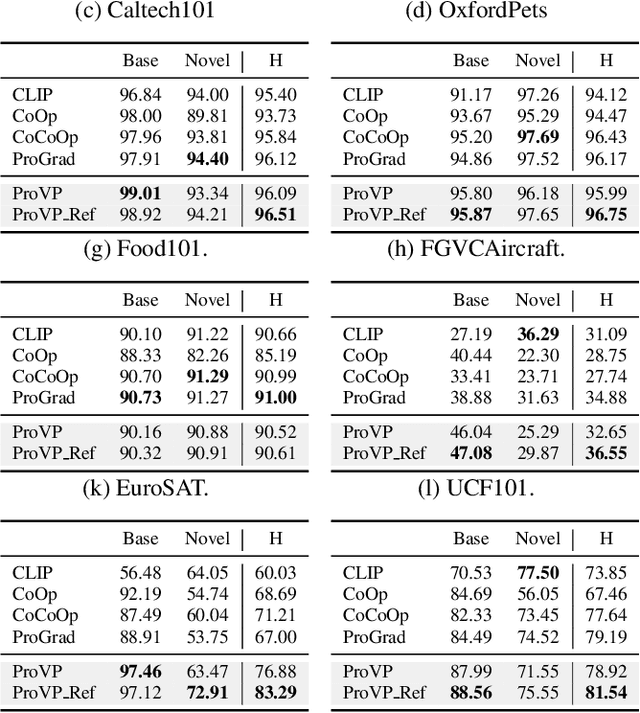
Prompt learning has been designed as an alternative to fine-tuning for adapting Vision-language (V-L) models to the downstream tasks. Previous works mainly focus on text prompt while visual prompt works are limited for V-L models. The existing visual prompt methods endure either mediocre performance or unstable training process, indicating the difficulty of visual prompt learning. In this paper, we propose a new Progressive Visual Prompt (ProVP) structure to strengthen the interactions among prompts of different layers. More importantly, our ProVP could effectively propagate the image embeddings to deep layers and behave partially similar to an instance adaptive prompt method. To alleviate generalization deterioration, we further propose a new contrastive feature re-formation, which prevents the serious deviation of the prompted visual feature from the fixed CLIP visual feature distribution. Combining both, our method (ProVP-Ref) is evaluated on 11 image benchmark datasets and achieves 7/11 state-of-theart results on both few-shot and base-to-novel settings. To the best of our knowledge, we are the first to demonstrate the superior performance of visual prompts in V-L models to previous prompt-based methods in downstream tasks. Meanwhile, it implies that our ProVP-Ref shows the best capability to adapt and to generalize.