 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
Taming Scalable Visual Tokenizer for Autoregressive Image Generation
Dec 03, 2024



Existing vector quantization (VQ) methods struggle with scalability, largely attributed to the instability of the codebook that undergoes partial updates during training. The codebook is prone to collapse as utilization decreases, due to the progressively widening distribution gap between non-activated codes and visual features. To solve the problem, we propose Index Backpropagation Quantization (IBQ), a new VQ method for the joint optimization of all codebook embeddings and the visual encoder. Applying a straight-through estimator on the one-hot categorical distribution between the encoded feature and codebook, all codes are differentiable and maintain a consistent latent space with the visual encoder. IBQ enables scalable training of visual tokenizers and, for the first time, achieves a large-scale codebook ($2^{18}$) with high dimension ($256$) and high utilization. Experiments on the standard ImageNet benchmark demonstrate the scalability and superiority of IBQ, achieving competitive results on both reconstruction ($1.00$ rFID) and autoregressive visual generation ($2.05$ gFID). The code and models are available at https://github.com/TencentARC/SEED-Voken.
Open-MAGVIT2: An Open-Source Project Toward Democratizing Auto-regressive Visual Generation
Sep 06, 2024We present Open-MAGVIT2, a family of auto-regressive image generation models ranging from 300M to 1.5B. The Open-MAGVIT2 project produces an open-source replication of Google's MAGVIT-v2 tokenizer, a tokenizer with a super-large codebook (i.e., $2^{18}$ codes), and achieves the state-of-the-art reconstruction performance (1.17 rFID) on ImageNet $256 \times 256$. Furthermore, we explore its application in plain auto-regressive models and validate scalability properties. To assist auto-regressive models in predicting with a super-large vocabulary, we factorize it into two sub-vocabulary of different sizes by asymmetric token factorization, and further introduce "next sub-token prediction" to enhance sub-token interaction for better generation quality. We release all models and codes to foster innovation and creativity in the field of auto-regressive visual generation.
BIVDiff: A Training-Free Framework for General-Purpose Video Synthesis via Bridging Image and Video Diffusion Models
Dec 05, 2023Diffusion models have made tremendous progress in text-driven image and video generation. Now text-to-image foundation models are widely applied to various downstream image synthesis tasks, such as controllable image generation and image editing, while downstream video synthesis tasks are less explored for several reasons. First, it requires huge memory and compute overhead to train a video generation foundation model. Even with video foundation models, additional costly training is still required for downstream video synthesis tasks. Second, although some works extend image diffusion models into videos in a training-free manner, temporal consistency cannot be well kept. Finally, these adaption methods are specifically designed for one task and fail to generalize to different downstream video synthesis tasks. To mitigate these issues, we propose a training-free general-purpose video synthesis framework, coined as BIVDiff, via bridging specific image diffusion models and general text-to-video foundation diffusion models. Specifically, we first use an image diffusion model (like ControlNet, Instruct Pix2Pix) for frame-wise video generation, then perform Mixed Inversion on the generated video, and finally input the inverted latents into the video diffusion model for temporal smoothing. Decoupling image and video models enables flexible image model selection for different purposes, which endows the framework with strong task generalization and high efficiency. To validate the effectiveness and general use of BIVDiff, we perform a wide range of video generation tasks, including controllable video generation video editing, video inpainting and outpainting. Our project page is available at https://bivdiff.github.io.
Bridging The Gaps Between Token Pruning and Full Pre-training via Masked Fine-tuning
Oct 26, 2023Despite the success of transformers on various computer vision tasks, they suffer from excessive memory and computational cost. Some works present dynamic vision transformers to accelerate inference by pruning redundant tokens. A key to improving token pruning is using well-trained models as initialization for faster convergence and better performance. However, current base models usually adopt full image training, i.e., using full images as inputs and keeping the whole feature maps through the forward process, which causes inconsistencies with dynamic models that gradually reduce tokens, including calculation pattern, information amount and token selection strategy inconsistencies. Inspired by MAE which performs masking and reconstruction self-supervised task, we devise masked fine-tuning to bridge the gaps between pre-trained base models used for initialization and token pruning based dynamic vision transformers, by masking image patches and predicting the image class label based on left unmasked patches. Extensive experiments on ImageNet demonstrate that base models via masked fine-tuning gain strong occlusion robustness and ability against information loss. With this better initialization, Dynamic ViT achieves higher accuracies, especially under large token pruning ratios (e.g., 81.9% vs. 81.3%, and 62.3% vs. 58.9% for DeiT based Dynamic ViT/0.8 and Dynamic ViT/0.3). Moreover, we apply our method into different token pruning based dynamic vision transformers, different pre-trained models and randomly initialized models to demonstrate the generalization ability.
Progressive Visual Prompt Learning with Contrastive Feature Re-formation
Apr 17, 2023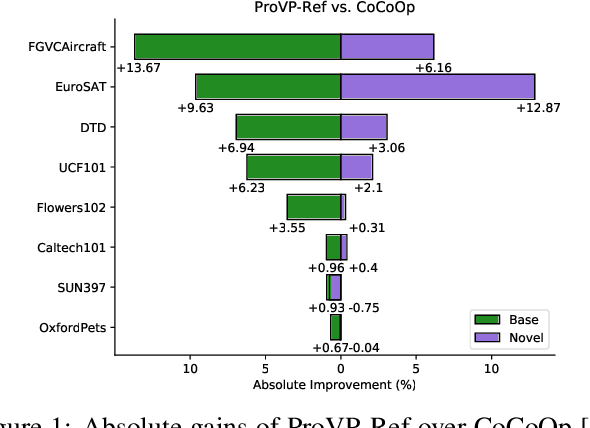
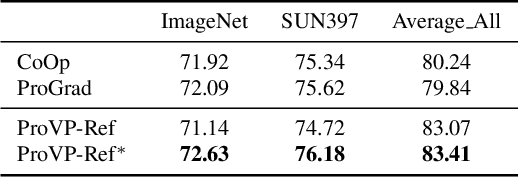
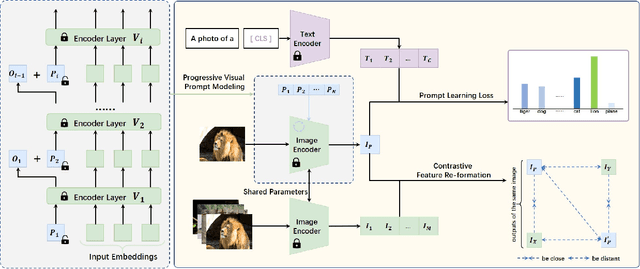
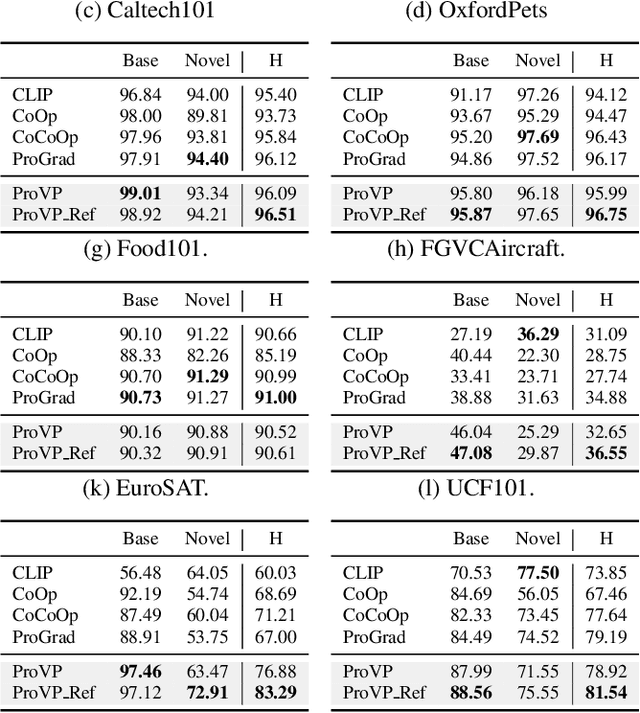
Prompt learning has been designed as an alternative to fine-tuning for adapting Vision-language (V-L) models to the downstream tasks. Previous works mainly focus on text prompt while visual prompt works are limited for V-L models. The existing visual prompt methods endure either mediocre performance or unstable training process, indicating the difficulty of visual prompt learning. In this paper, we propose a new Progressive Visual Prompt (ProVP) structure to strengthen the interactions among prompts of different layers. More importantly, our ProVP could effectively propagate the image embeddings to deep layers and behave partially similar to an instance adaptive prompt method. To alleviate generalization deterioration, we further propose a new contrastive feature re-formation, which prevents the serious deviation of the prompted visual feature from the fixed CLIP visual feature distribution. Combining both, our method (ProVP-Ref) is evaluated on 11 image benchmark datasets and achieves 7/11 state-of-theart results on both few-shot and base-to-novel settings. To the best of our knowledge, we are the first to demonstrate the superior performance of visual prompts in V-L models to previous prompt-based methods in downstream tasks. Meanwhile, it implies that our ProVP-Ref shows the best capability to adapt and to generalize.
Dynamic MDETR: A Dynamic Multimodal Transformer Decoder for Visual Grounding
Sep 28, 2022

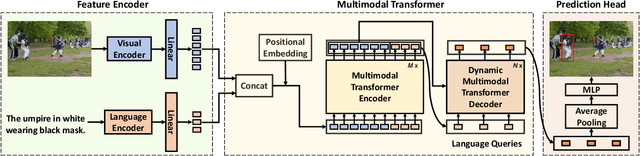
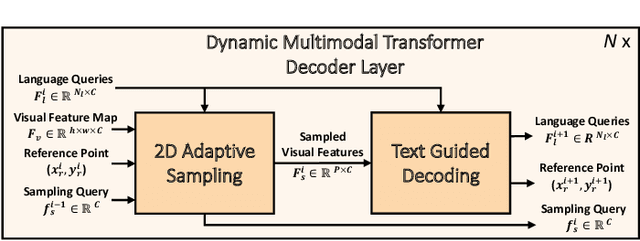
Multimodal transformer exhibits high capacity and flexibility to align image and text for visual grounding. However, the encoder-only grounding framework (e.g., TransVG) suffers from heavy computation due to the self-attention operation with quadratic time complexity. To address this issue, we present a new multimodal transformer architecture, coined as Dynamic MDETR, by decoupling the whole grounding process into encoding and decoding phases. The key observation is that there exists high spatial redundancy in images. Thus, we devise a new dynamic multimodal transformer decoder by exploiting this sparsity prior to speed up the visual grounding process. Specifically, our dynamic decoder is composed of a 2D adaptive sampling module and a text-guided decoding module. The sampling module aims to select these informative patches by predicting the offsets with respect to a reference point, while the decoding module works for extracting the grounded object information by performing cross attention between image features and text features. These two modules are stacked alternatively to gradually bridge the modality gap and iteratively refine the reference point of grounded object, eventually realizing the objective of visual grounding. Extensive experiments on five benchmarks demonstrate that our proposed Dynamic MDETR achieves competitive trade-offs between computation and accuracy. Notably, using only 9% feature points in the decoder, we can reduce ~44% GLOPs of the multimodal transformer, but still get higher accuracy than the encoder-only counterpart. In addition, to verify its generalization ability and scale up our Dynamic MDETR, we build the first one-stage CLIP empowered visual grounding framework, and achieve the state-of-the-art performance on these benchmarks.
End-to-End Dense Video Grounding via Parallel Regression
Sep 23, 2021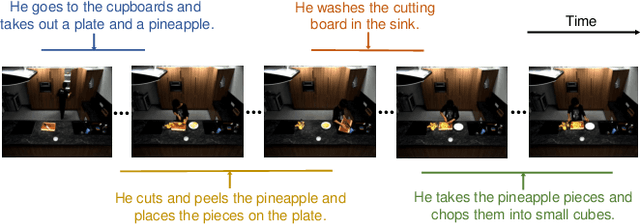
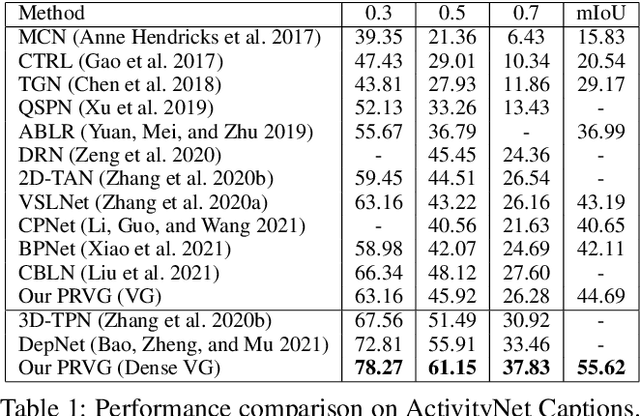
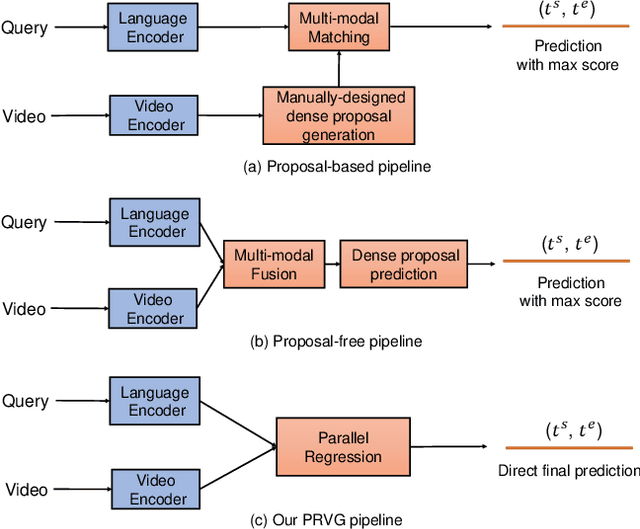
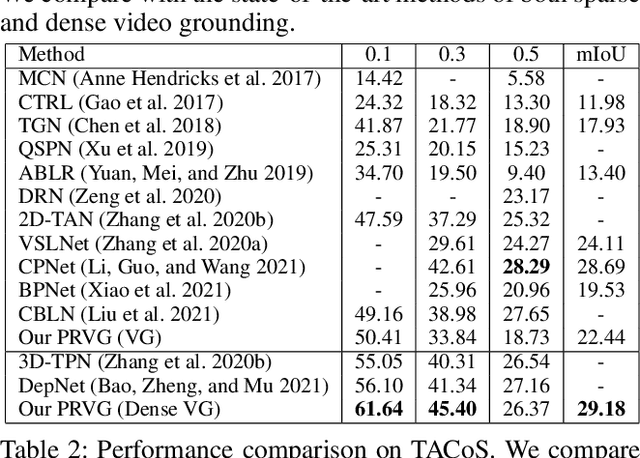
Video grounding aims to localize the corresponding video moment in an untrimmed video given a language query. Existing methods often address this task in an indirect way, by casting it as a proposal-and-match or fusion-and-detection problem. Solving these surrogate problems often requires sophisticated label assignment during training and hand-crafted removal of near-duplicate results. Meanwhile, existing works typically focus on sparse video grounding with a single sentence as input, which could result in ambiguous localization due to its unclear description. In this paper, we tackle a new problem of dense video grounding, by simultaneously localizing multiple moments with a paragraph as input. From a perspective on video grounding as language conditioned regression, we present an end-to-end parallel decoding paradigm by re-purposing a Transformer-alike architecture (PRVG). The key design in our PRVG is to use languages as queries, and directly regress the moment boundaries based on language-modulated visual representations. Thanks to its simplicity in design, our PRVG framework can be applied in different testing schemes (sparse or dense grounding) and allows for efficient inference without any post-processing technique. In addition, we devise a robust proposal-level attention loss to guide the training of PRVG, which is invariant to moment duration and contributes to model convergence. We perform experiments on two video grounding benchmarks of ActivityNet Captions and TACoS, demonstrating that our PRVG can significantly outperform previous methods. We also perform in-depth studies to investigate the effectiveness of parallel regression paradigm on video grounding.