 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop 10 Open Challenges Steering the Future of Diffusion Language Model and Its Variants
Jan 20, 2026The paradigm of Large Language Models (LLMs) is currently defined by auto-regressive (AR) architectures, which generate text through a sequential ``brick-by-brick'' process. Despite their success, AR models are inherently constrained by a causal bottleneck that limits global structural foresight and iterative refinement. Diffusion Language Models (DLMs) offer a transformative alternative, conceptualizing text generation as a holistic, bidirectional denoising process akin to a sculptor refining a masterpiece. However, the potential of DLMs remains largely untapped as they are frequently confined within AR-legacy infrastructures and optimization frameworks. In this Perspective, we identify ten fundamental challenges ranging from architectural inertia and gradient sparsity to the limitations of linear reasoning that prevent DLMs from reaching their ``GPT-4 moment''. We propose a strategic roadmap organized into four pillars: foundational infrastructure, algorithmic optimization, cognitive reasoning, and unified multimodal intelligence. By shifting toward a diffusion-native ecosystem characterized by multi-scale tokenization, active remasking, and latent thinking, we can move beyond the constraints of the causal horizon. We argue that this transition is essential for developing next-generation AI capable of complex structural reasoning, dynamic self-correction, and seamless multimodal integration.
Map2Thought: Explicit 3D Spatial Reasoning via Metric Cognitive Maps
Jan 16, 2026We propose Map2Thought, a framework that enables explicit and interpretable spatial reasoning for 3D VLMs. The framework is grounded in two key components: Metric Cognitive Map (Metric-CogMap) and Cognitive Chain-of-Thought (Cog-CoT). Metric-CogMap provides a unified spatial representation by integrating a discrete grid for relational reasoning with a continuous, metric-scale representation for precise geometric understanding. Building upon the Metric-CogMap, Cog-CoT performs explicit geometric reasoning through deterministic operations, including vector operations, bounding-box distances, and occlusion-aware appearance order cues, producing interpretable inference traces grounded in 3D structure. Experimental results show that Map2Thought enables explainable 3D understanding, achieving 59.9% accuracy using only half the supervision, closely matching the 60.9% baseline trained with the full dataset. It consistently outperforms state-of-the-art methods by 5.3%, 4.8%, and 4.0% under 10%, 25%, and 50% training subsets, respectively, on the VSI-Bench.
Off The Grid: Detection of Primitives for Feed-Forward 3D Gaussian Splatting
Dec 17, 2025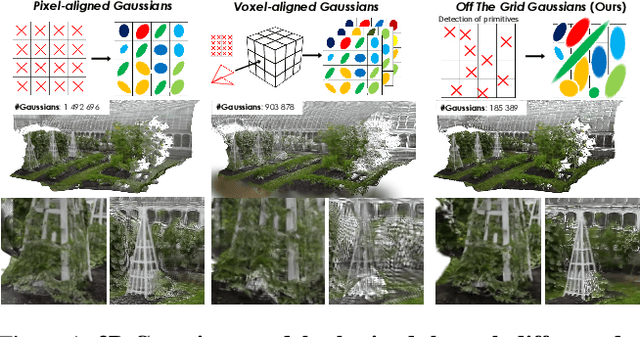
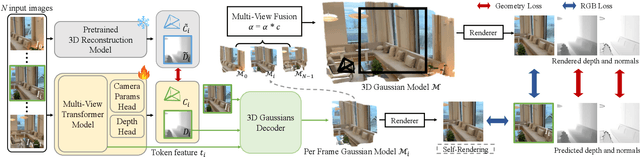


Feed-forward 3D Gaussian Splatting (3DGS) models enable real-time scene generation but are hindered by suboptimal pixel-aligned primitive placement, which relies on a dense, rigid grid and limits both quality and efficiency. We introduce a new feed-forward architecture that detects 3D Gaussian primitives at a sub-pixel level, replacing the pixel grid with an adaptive, "Off The Grid" distribution. Inspired by keypoint detection, our multi-resolution decoder learns to distribute primitives across image patches. This module is trained end-to-end with a 3D reconstruction backbone using self-supervised learning. Our resulting pose-free model generates photorealistic scenes in seconds, achieving state-of-the-art novel view synthesis for feed-forward models. It outperforms competitors while using far fewer primitives, demonstrating a more accurate and efficient allocation that captures fine details and reduces artifacts. Moreover, we observe that by learning to render 3D Gaussians, our 3D reconstruction backbone improves camera pose estimation, suggesting opportunities to train these foundational models without labels.
ECCV 2024 W-CODA: 1st Workshop on Multimodal Perception and Comprehension of Corner Cases in Autonomous Driving
Jul 02, 2025
In this paper, we present details of the 1st W-CODA workshop, held in conjunction with the ECCV 2024. W-CODA aims to explore next-generation solutions for autonomous driving corner cases, empowered by state-of-the-art multimodal perception and comprehension techniques. 5 Speakers from both academia and industry are invited to share their latest progress and opinions. We collect research papers and hold a dual-track challenge, including both corner case scene understanding and generation. As the pioneering effort, we will continuously bridge the gap between frontier autonomous driving techniques and fully intelligent, reliable self-driving agents robust towards corner cases.
MagicEraser: Erasing Any Objects via Semantics-Aware Control
Oct 14, 2024The traditional image inpainting task aims to restore corrupted regions by referencing surrounding background and foreground. However, the object erasure task, which is in increasing demand, aims to erase objects and generate harmonious background. Previous GAN-based inpainting methods struggle with intricate texture generation. Emerging diffusion model-based algorithms, such as Stable Diffusion Inpainting, exhibit the capability to generate novel content, but they often produce incongruent results at the locations of the erased objects and require high-quality text prompt inputs. To address these challenges, we introduce MagicEraser, a diffusion model-based framework tailored for the object erasure task. It consists of two phases: content initialization and controllable generation. In the latter phase, we develop two plug-and-play modules called prompt tuning and semantics-aware attention refocus. Additionally, we propose a data construction strategy that generates training data specially suitable for this task. MagicEraser achieves fine and effective control of content generation while mitigating undesired artifacts. Experimental results highlight a valuable advancement of our approach in the object erasure task.
TexGen: Text-Guided 3D Texture Generation with Multi-view Sampling and Resampling
Aug 02, 2024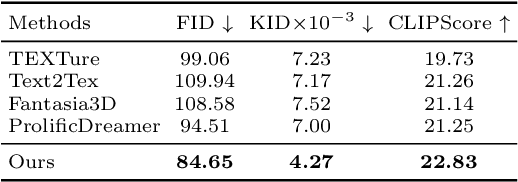
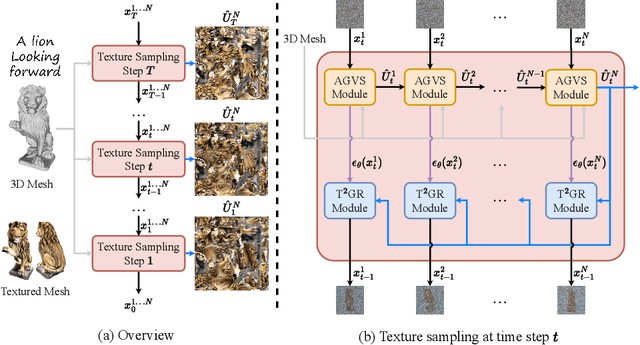
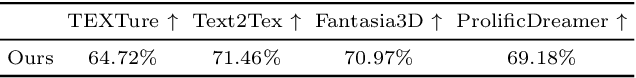

Given a 3D mesh, we aim to synthesize 3D textures that correspond to arbitrary textual descriptions. Current methods for generating and assembling textures from sampled views often result in prominent seams or excessive smoothing. To tackle these issues, we present TexGen, a novel multi-view sampling and resampling framework for texture generation leveraging a pre-trained text-to-image diffusion model. For view consistent sampling, first of all we maintain a texture map in RGB space that is parameterized by the denoising step and updated after each sampling step of the diffusion model to progressively reduce the view discrepancy. An attention-guided multi-view sampling strategy is exploited to broadcast the appearance information across views. To preserve texture details, we develop a noise resampling technique that aids in the estimation of noise, generating inputs for subsequent denoising steps, as directed by the text prompt and current texture map. Through an extensive amount of qualitative and quantitative evaluations, we demonstrate that our proposed method produces significantly better texture quality for diverse 3D objects with a high degree of view consistency and rich appearance details, outperforming current state-of-the-art methods. Furthermore, our proposed texture generation technique can also be applied to texture editing while preserving the original identity. More experimental results are available at https://dong-huo.github.io/TexGen/
EmoTalk3D: High-Fidelity Free-View Synthesis of Emotional 3D Talking Head
Aug 01, 2024



We present a novel approach for synthesizing 3D talking heads with controllable emotion, featuring enhanced lip synchronization and rendering quality. Despite significant progress in the field, prior methods still suffer from multi-view consistency and a lack of emotional expressiveness. To address these issues, we collect EmoTalk3D dataset with calibrated multi-view videos, emotional annotations, and per-frame 3D geometry. By training on the EmoTalk3D dataset, we propose a \textit{`Speech-to-Geometry-to-Appearance'} mapping framework that first predicts faithful 3D geometry sequence from the audio features, then the appearance of a 3D talking head represented by 4D Gaussians is synthesized from the predicted geometry. The appearance is further disentangled into canonical and dynamic Gaussians, learned from multi-view videos, and fused to render free-view talking head animation. Moreover, our model enables controllable emotion in the generated talking heads and can be rendered in wide-range views. Our method exhibits improved rendering quality and stability in lip motion generation while capturing dynamic facial details such as wrinkles and subtle expressions. Experiments demonstrate the effectiveness of our approach in generating high-fidelity and emotion-controllable 3D talking heads. The code and EmoTalk3D dataset are released at https://nju-3dv.github.io/projects/EmoTalk3D.
GSD: View-Guided Gaussian Splatting Diffusion for 3D Reconstruction
Jul 05, 2024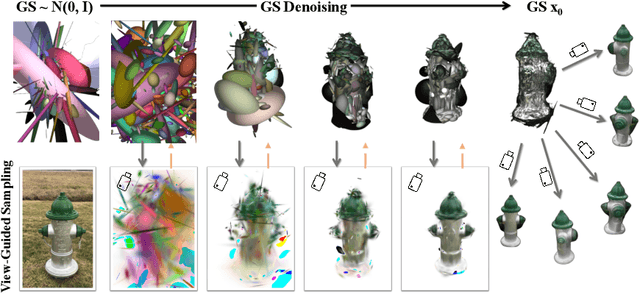



We present GSD, a diffusion model approach based on Gaussian Splatting (GS) representation for 3D object reconstruction from a single view. Prior works suffer from inconsistent 3D geometry or mediocre rendering quality due to improper representations. We take a step towards resolving these shortcomings by utilizing the recent state-of-the-art 3D explicit representation, Gaussian Splatting, and an unconditional diffusion model. This model learns to generate 3D objects represented by sets of GS ellipsoids. With these strong generative 3D priors, though learning unconditionally, the diffusion model is ready for view-guided reconstruction without further model fine-tuning. This is achieved by propagating fine-grained 2D features through the efficient yet flexible splatting function and the guided denoising sampling process. In addition, a 2D diffusion model is further employed to enhance rendering fidelity, and improve reconstructed GS quality by polishing and re-using the rendered images. The final reconstructed objects explicitly come with high-quality 3D structure and texture, and can be efficiently rendered in arbitrary views. Experiments on the challenging real-world CO3D dataset demonstrate the superiority of our approach.
AutoTVG: A New Vision-language Pre-training Paradigm for Temporal Video Grounding
Jun 11, 2024



Temporal Video Grounding (TVG) aims to localize a moment from an untrimmed video given the language description. Since the annotation of TVG is labor-intensive, TVG under limited supervision has accepted attention in recent years. The great success of vision-language pre-training guides TVG to follow the traditional "pre-training + fine-tuning" paradigm, however, the pre-training process would suffer from a lack of temporal modeling and fine-grained alignment due to the difference of data nature between pre-train and test. Besides, the large gap between pretext and downstream tasks makes zero-shot testing impossible for the pre-trained model. To avoid the drawbacks of the traditional paradigm, we propose AutoTVG, a new vision-language pre-training paradigm for TVG that enables the model to learn semantic alignment and boundary regression from automatically annotated untrimmed videos. To be specific, AutoTVG consists of a novel Captioned Moment Generation (CMG) module to generate captioned moments from untrimmed videos, and TVGNet with a regression head to predict localization results. Experimental results on Charades-STA and ActivityNet Captions show that, regarding zero-shot temporal video grounding, AutoTVG achieves highly competitive performance with in-distribution methods under out-of-distribution testing, and is superior to existing pre-training frameworks with much less training data.
MirrorGaussian: Reflecting 3D Gaussians for Reconstructing Mirror Reflections
May 20, 2024



3D Gaussian Splatting showcases notable advancements in photo-realistic and real-time novel view synthesis. However, it faces challenges in modeling mirror reflections, which exhibit substantial appearance variations from different viewpoints. To tackle this problem, we present MirrorGaussian, the first method for mirror scene reconstruction with real-time rendering based on 3D Gaussian Splatting. The key insight is grounded on the mirror symmetry between the real-world space and the virtual mirror space. We introduce an intuitive dual-rendering strategy that enables differentiable rasterization of both the real-world 3D Gaussians and the mirrored counterpart obtained by reflecting the former about the mirror plane. All 3D Gaussians are jointly optimized with the mirror plane in an end-to-end framework. MirrorGaussian achieves high-quality and real-time rendering in scenes with mirrors, empowering scene editing like adding new mirrors and objects. Comprehensive experiments on multiple datasets demonstrate that our approach significantly outperforms existing methods, achieving state-of-the-art results. Project page: https://mirror-gaussian.github.io/.