 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-End Approach for Chord-Conditioned Song Generation
Sep 10, 2024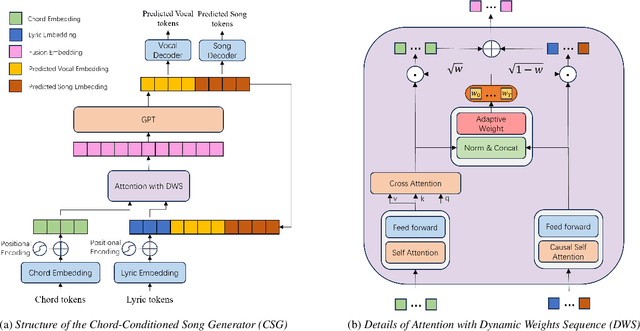
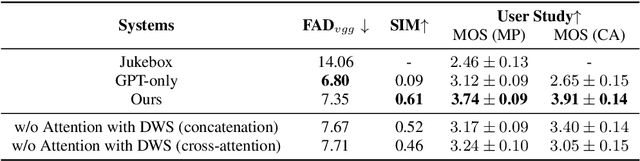
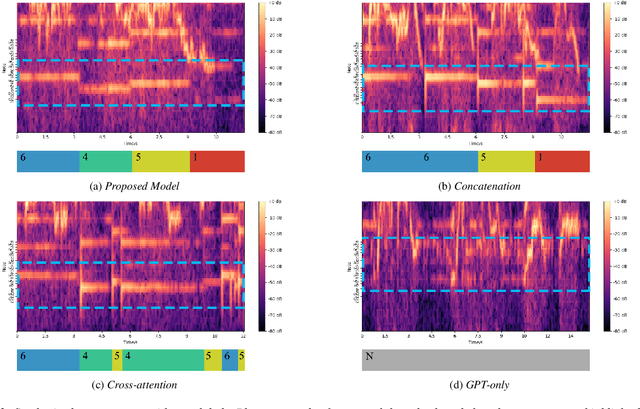
The Song Generation task aims to synthesize music composed of vocals and accompaniment from given lyrics. While the existing method, Jukebox, has explored this task, its constrained control over the generations often leads to deficiency in music performance. To mitigate the issue, we introduce an important concept from music composition, namely chords, to song generation networks. Chords form the foundation of accompaniment and provide vocal melody with associated harmony. Given the inaccuracy of automatic chord extractors, we devise a robust cross-attention mechanism augmented with dynamic weight sequence to integrate extracted chord information into song generations and reduce frame-level flaws, and propose a novel model termed Chord-Conditioned Song Generator (CSG) based on it. Experimental evidence demonstrates our proposed method outperforms other approaches in terms of musical performance and control precision of generated songs.
Co-Speech Gesture Video Generation via Motion-Decoupled Diffusion Model
Apr 02, 2024
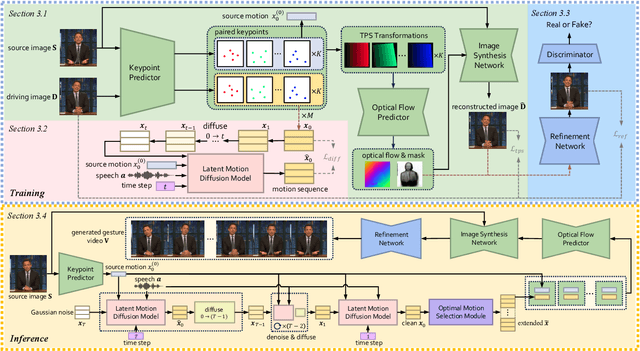

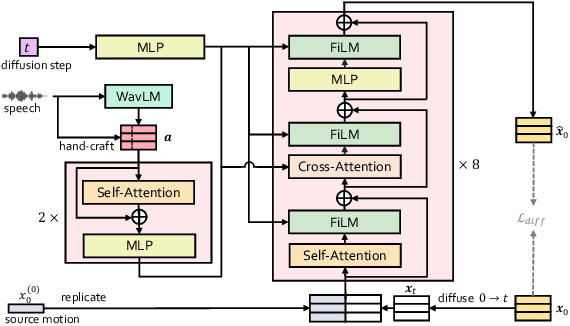
Co-speech gestures, if presented in the lively form of videos, can achieve superior visual effects in human-machine interaction. While previous works mostly generate structural human skeletons, resulting in the omission of appearance information, we focus on the direct generation of audio-driven co-speech gesture videos in this work. There are two main challenges: 1) A suitable motion feature is needed to describe complex human movements with crucial appearance information. 2) Gestures and speech exhibit inherent dependencies and should be temporally aligned even of arbitrary length. To solve these problems, we present a novel motion-decoupled framework to generate co-speech gesture videos. Specifically, we first introduce a well-designed nonlinear TPS transformation to obtain latent motion features preserving essential appearance information. Then a transformer-based diffusion model is proposed to learn the temporal correlation between gestures and speech, and performs generation in the latent motion space, followed by an optimal motion selection module to produce long-term coherent and consistent gesture videos. For better visual perception, we further design a refinement network focusing on missing details of certain areas. Extensive experimental results show that our proposed framework significantly outperforms existing approaches in both motion and video-related evaluations. Our code, demos, and more resources are available at https://github.com/thuhcsi/S2G-MDDiffusion.
Enhancing Expressiveness in Dance Generation via Integrating Frequency and Music Style Information
Mar 09, 2024



Dance generation, as a branch of human motion generation, has attracted increasing attention. Recently, a few works attempt to enhance dance expressiveness, which includes genre matching, beat alignment, and dance dynamics, from certain aspects. However, the enhancement is quite limited as they lack comprehensive consideration of the aforementioned three factors. In this paper, we propose ExpressiveBailando, a novel dance generation method designed to generate expressive dances, concurrently taking all three factors into account. Specifically, we mitigate the issue of speed homogenization by incorporating frequency information into VQ-VAE, thus improving dance dynamics. Additionally, we integrate music style information by extracting genre- and beat-related features with a pre-trained music model, hence achieving improvements in the other two factors. Extensive experimental results demonstrate that our proposed method can generate dances with high expressiveness and outperforms existing methods both qualitatively and quantitatively.
SECap: Speech Emotion Captioning with Large Language Model
Dec 23, 2023



Speech emotions are crucial in human communication and are extensively used in fields like speech synthesis and natural language understanding. Most prior studies, such as speech emotion recognition, have categorized speech emotions into a fixed set of classes. Yet, emotions expressed in human speech are often complex, and categorizing them into predefined groups can be insufficient to adequately represent speech emotions. On the contrary, describing speech emotions directly by means of natural language may be a more effective approach. Regrettably, there are not many studies available that have focused on this direction. Therefore, this paper proposes a speech emotion captioning framework named SECap, aiming at effectively describing speech emotions using natural language. Owing to the impressive capabilities of large language models in language comprehension and text generation, SECap employs LLaMA as the text decoder to allow the production of coherent speech emotion captions. In addition, SECap leverages HuBERT as the audio encoder to extract general speech features and Q-Former as the Bridge-Net to provide LLaMA with emotion-related speech features. To accomplish this, Q-Former utilizes mutual information learning to disentangle emotion-related speech features and speech contents, while implementing contrastive learning to extract more emotion-related speech features. The results of objective and subjective evaluations demonstrate that: 1) the SECap framework outperforms the HTSAT-BART baseline in all objective evaluations; 2) SECap can generate high-quality speech emotion captions that attain performance on par with human annotators in subjective mean opinion score tests.
SimCalib: Graph Neural Network Calibration based on Similarity between Nodes
Dec 19, 2023Graph neural networks (GNNs) have exhibited impressive performance in modeling graph data as exemplified in various applications. Recently, the GNN calibration problem has attracted increasing attention, especially in cost-sensitive scenarios. Previous work has gained empirical insights on the issue, and devised effective approaches for it, but theoretical supports still fall short. In this work, we shed light on the relationship between GNN calibration and nodewise similarity via theoretical analysis. A novel calibration framework, named SimCalib, is accordingly proposed to consider similarity between nodes at global and local levels. At the global level, the Mahalanobis distance between the current node and class prototypes is integrated to implicitly consider similarity between the current node and all nodes in the same class. At the local level, the similarity of node representation movement dynamics, quantified by nodewise homophily and relative degree, is considered. Informed about the application of nodewise movement patterns in analyzing nodewise behavior on the over-smoothing problem, we empirically present a possible relationship between over-smoothing and GNN calibration problem. Experimentally, we discover a correlation between nodewise similarity and model calibration improvement, in alignment with our theoretical results. Additionally, we conduct extensive experiments investigating different design factors and demonstrate the effectiveness of our proposed SimCalib framework for GNN calibration by achieving state-of-the-art performance on 14 out of 16 benchmarks.
UnifiedGesture: A Unified Gesture Synthesis Model for Multiple Skeletons
Sep 13, 2023



The automatic co-speech gesture generation draws much attention in computer animation. Previous works designed network structures on individual datasets, which resulted in a lack of data volume and generalizability across different motion capture standards. In addition, it is a challenging task due to the weak correlation between speech and gestures. To address these problems, we present UnifiedGesture, a novel diffusion model-based speech-driven gesture synthesis approach, trained on multiple gesture datasets with different skeletons. Specifically, we first present a retargeting network to learn latent homeomorphic graphs for different motion capture standards, unifying the representations of various gestures while extending the dataset. We then capture the correlation between speech and gestures based on a diffusion model architecture using cross-local attention and self-attention to generate better speech-matched and realistic gestures. To further align speech and gesture and increase diversity, we incorporate reinforcement learning on the discrete gesture units with a learned reward function. Extensive experiments show that UnifiedGesture outperforms recent approaches on speech-driven gesture generation in terms of CCA, FGD, and human-likeness. All code, pre-trained models, databases, and demos are available to the public at https://github.com/YoungSeng/UnifiedGesture.
Towards Spontaneous Style Modeling with Semi-supervised Pre-training for Conversational Text-to-Speech Synthesis
Aug 31, 2023



The spontaneous behavior that often occurs in conversations makes speech more human-like compared to reading-style. However, synthesizing spontaneous-style speech is challenging due to the lack of high-quality spontaneous datasets and the high cost of labeling spontaneous behavior. In this paper, we propose a semi-supervised pre-training method to increase the amount of spontaneous-style speech and spontaneous behavioral labels. In the process of semi-supervised learning, both text and speech information are considered for detecting spontaneous behaviors labels in speech. Moreover, a linguistic-aware encoder is used to model the relationship between each sentence in the conversation. Experimental results indicate that our proposed method achieves superior expressive speech synthesis performance with the ability to model spontaneous behavior in spontaneous-style speech and predict reasonable spontaneous behavior from text.