 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagicMan: Generative Novel View Synthesis of Humans with 3D-Aware Diffusion and Iterative Refinement
Aug 26, 2024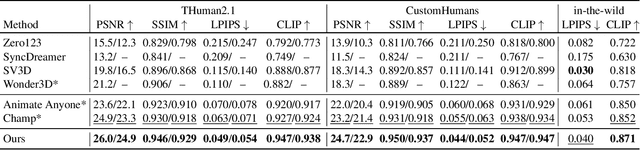
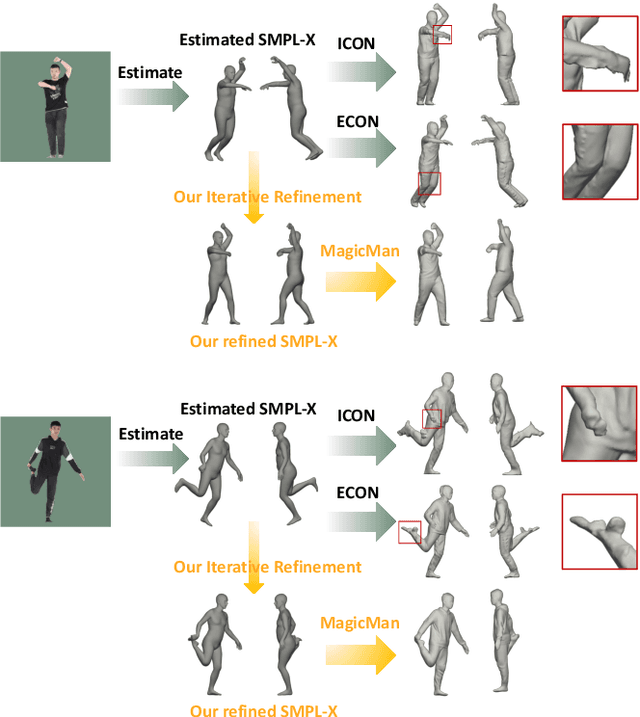
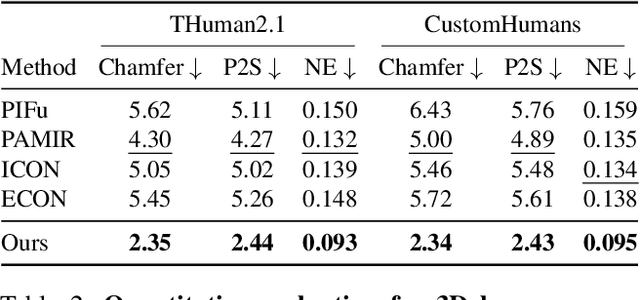
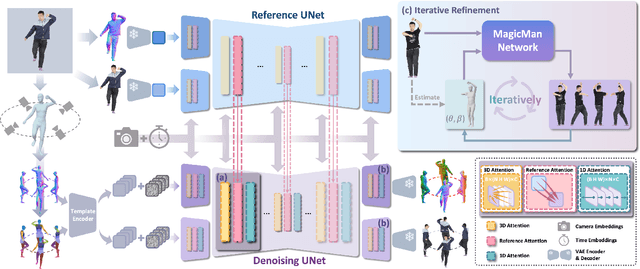
Existing works in single-image human reconstruction suffer from weak generalizability due to insufficient training data or 3D inconsistencies for a lack of comprehensive multi-view knowledge. In this paper, we introduce MagicMan, a human-specific multi-view diffusion model designed to generate high-quality novel view images from a single reference image. As its core, we leverage a pre-trained 2D diffusion model as the generative prior for generalizability, with the parametric SMPL-X model as the 3D body prior to promote 3D awareness. To tackle the critical challenge of maintaining consistency while achieving dense multi-view generation for improved 3D human reconstruction, we first introduce hybrid multi-view attention to facilitate both efficient and thorough information interchange across different views. Additionally, we present a geometry-aware dual branch to perform concurrent generation in both RGB and normal domains, further enhancing consistency via geometry cues. Last but not least, to address ill-shaped issues arising from inaccurate SMPL-X estimation that conflicts with the reference image, we propose a novel iterative refinement strategy, which progressively optimizes SMPL-X accuracy while enhancing the quality and consistency of the generated multi-views. Extensive experimental results demonstrate that our method significantly outperforms existing approaches in both novel view synthesis and subsequent 3D human reconstruction tasks.
Enhancing Expressiveness in Dance Generation via Integrating Frequency and Music Style Information
Mar 09, 2024



Dance generation, as a branch of human motion generation, has attracted increasing attention. Recently, a few works attempt to enhance dance expressiveness, which includes genre matching, beat alignment, and dance dynamics, from certain aspects. However, the enhancement is quite limited as they lack comprehensive consideration of the aforementioned three factors. In this paper, we propose ExpressiveBailando, a novel dance generation method designed to generate expressive dances, concurrently taking all three factors into account. Specifically, we mitigate the issue of speed homogenization by incorporating frequency information into VQ-VAE, thus improving dance dynamics. Additionally, we integrate music style information by extracting genre- and beat-related features with a pre-trained music model, hence achieving improvements in the other two factors. Extensive experimental results demonstrate that our proposed method can generate dances with high expressiveness and outperforms existing methods both qualitatively and quantitatively.
Explore 3D Dance Generation via Reward Model from Automatically-Ranked Demonstrations
Dec 18, 2023This paper presents an Exploratory 3D Dance generation framework, E3D2, designed to address the exploration capability deficiency in existing music-conditioned 3D dance generation models. Current models often generate monotonous and simplistic dance sequences that misalign with human preferences because they lack exploration capabilities. The E3D2 framework involves a reward model trained from automatically-ranked dance demonstrations, which then guides the reinforcement learning process. This approach encourages the agent to explore and generate high quality and diverse dance movement sequences. The soundness of the reward model is both theoretically and experimentally validated. Empirical experiments demonstrate the effectiveness of E3D2 on the AIST++ dataset. Project Page: https://sites.google.com/view/e3d2.
QPGesture: Quantization-Based and Phase-Guided Motion Matching for Natural Speech-Driven Gesture Generation
May 18, 2023Speech-driven gesture generation is highly challenging due to the random jitters of human motion. In addition, there is an inherent asynchronous relationship between human speech and gestures. To tackle these challenges, we introduce a novel quantization-based and phase-guided motion-matching framework. Specifically, we first present a gesture VQ-VAE module to learn a codebook to summarize meaningful gesture units. With each code representing a unique gesture, random jittering problems are alleviated effectively. We then use Levenshtein distance to align diverse gestures with different speech. Levenshtein distance based on audio quantization as a similarity metric of corresponding speech of gestures helps match more appropriate gestures with speech, and solves the alignment problem of speech and gestures well. Moreover, we introduce phase to guide the optimal gesture matching based on the semantics of context or rhythm of audio. Phase guides when text-based or speech-based gestures should be performed to make the generated gestures more natural. Extensive experiments show that our method outperforms recent approaches on speech-driven gesture generation. Our code, database, pre-trained models, and demos are available at https://github.com/YoungSeng/QPGesture.
GTN-Bailando: Genre Consistent Long-Term 3D Dance Generation based on Pre-trained Genre Token Network
Apr 25, 2023Music-driven 3D dance generation has become an intensive research topic in recent years with great potential for real-world applications. Most existing methods lack the consideration of genre, which results in genre inconsistency in the generated dance movements. In addition, the correlation between the dance genre and the music has not been investigated. To address these issues, we propose a genre-consistent dance generation framework, GTN-Bailando. First, we propose the Genre Token Network (GTN), which infers the genre from music to enhance the genre consistency of long-term dance generation. Second, to improve the generalization capability of the model, the strategy of pre-training and fine-tuning is adopted.Experimental results on the AIST++ dataset show that the proposed dance generation framework outperforms state-of-the-art methods in terms of motion quality and genre consistency.
Speech Representation Disentanglement with Adversarial Mutual Information Learning for One-shot Voice Conversion
Aug 18, 2022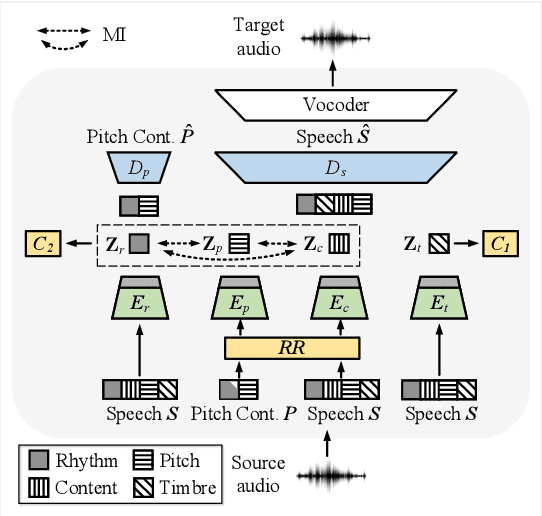

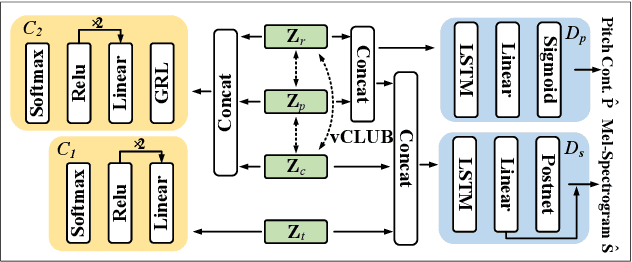
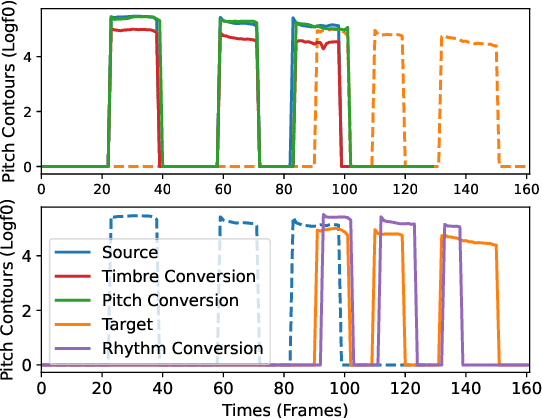
One-shot voice conversion (VC) with only a single target speaker's speech for reference has become a hot research topic. Existing works generally disentangle timbre, while information about pitch, rhythm and content is still mixed together. To perform one-shot VC effectively with further disentangling these speech components, we employ random resampling for pitch and content encoder and use the variational contrastive log-ratio upper bound of mutual information and gradient reversal layer based adversarial mutual information learning to ensure the different parts of the latent space containing only the desired disentangled representation during training. Experiments on the VCTK dataset show the model achieves state-of-the-art performance for one-shot VC in terms of naturalness and intellgibility. In addition, we can transfer characteristics of one-shot VC on timbre, pitch and rhythm separately by speech representation disentanglement. Our code, pre-trained models and demo are available at https://im1eon.github.io/IS2022-SRDVC/.