 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRIME: A Process-Outcome Alignment Benchmark for Verifiable Reasoning in Mathematics and Engineering
Feb 12, 2026While model-based verifiers are essential for scaling Reinforcement Learning with Verifiable Rewards (RLVR), current outcome-centric verification paradigms primarily focus on the consistency between the final result and the ground truth, often neglecting potential errors in the derivation process. This leads to assigning positive rewards to correct answers produced from incorrect derivations. To bridge this gap, we introduce PRIME, a benchmark for evaluating verifiers on Process-Outcome Alignment verification in Mathematics and Engineering. Curated from a comprehensive collection of college-level STEM problems, PRIME comprises 2,530 high-difficulty samples through a consistency-based filtering pipeline. Through extensive evaluation, we find that current verifiers frequently fail to detect derivation flaws. Furthermore, we propose a process-aware RLVR training paradigm utilizing verifiers selected via PRIME. This approach substantially outperforms the outcome-only verification baseline, achieving absolute performance gains of 8.29%, 9.12%, and 7.31% on AIME24, AIME25, and Beyond-AIME, respectively, for the Qwen3-14B-Base model. Finally, we demonstrate a strong linear correlation ($R^2 > 0.92$) between verifier accuracy on PRIME and RLVR training effectiveness, validating PRIME as a reliable predictor for verifier selection.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
R-Align: Enhancing Generative Reward Models through Rationale-Centric Meta-Judging
Feb 06, 2026Reinforcement Learning from Human Feedback (RLHF) remains indispensable for aligning large language models (LLMs) in subjective domains. To enhance robustness, recent work shifts toward Generative Reward Models (GenRMs) that generate rationales before predicting preferences. Yet in GenRM training and evaluation, practice remains outcome-label-only, leaving reasoning quality unchecked. We show that reasoning fidelity-the consistency between a GenRM's preference decision and reference decision rationales-is highly predictive of downstream RLHF outcomes, beyond standard label accuracy. Specifically, we repurpose existing reward-model benchmarks to compute Spurious Correctness (S-Corr)-the fraction of label-correct decisions with rationales misaligned with golden judgments. Our empirical evaluation reveals substantial S-Corr even for competitive GenRMs, and higher S-Corr is associated with policy degeneration under optimization. To improve fidelity, we propose Rationale-Centric Alignment, R-Align, which augments training with gold judgments and explicitly supervises rationale alignment. R-Align reduces S-Corr on RM benchmarks and yields consistent gains in actor performance across STEM, coding, instruction following, and general tasks.
STEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning
Jan 09, 2026We introduce Parallel Coordinated Reasoning (PaCoRe), a training-and-inference framework designed to overcome a central limitation of contemporary language models: their inability to scale test-time compute (TTC) far beyond sequential reasoning under a fixed context window. PaCoRe departs from the traditional sequential paradigm by driving TTC through massive parallel exploration coordinated via a message-passing architecture in multiple rounds. Each round launches many parallel reasoning trajectories, compacts their findings into context-bounded messages, and synthesizes these messages to guide the next round and ultimately produce the final answer. Trained end-to-end with large-scale, outcome-based reinforcement learning, the model masters the synthesis abilities required by PaCoRe and scales to multi-million-token effective TTC without exceeding context limits. The approach yields strong improvements across diverse domains, and notably pushes reasoning beyond frontier systems in mathematics: an 8B model reaches 94.5% on HMMT 2025, surpassing GPT-5's 93.2% by scaling effective TTC to roughly two million tokens. We open-source model checkpoints, training data, and the full inference pipeline to accelerate follow-up work.
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
Mar 31, 2025



We introduce Open-Reasoner-Zero, the first open source implementation of large-scale reasoning-oriented RL training focusing on scalability, simplicity and accessibility. Through extensive experiments, we demonstrate that a minimalist approach, vanilla PPO with GAE ($\lambda=1$, $\gamma=1$) and straightforward rule-based rewards, without any KL regularization, is sufficient to scale up both response length and benchmark performance, similar to the phenomenon observed in DeepSeek-R1-Zero. Using the same base model as DeepSeek-R1-Zero-Qwen-32B, our implementation achieves superior performance on AIME2024, MATH500, and the GPQA Diamond benchmark while demonstrating remarkable efficiency -- requiring only a tenth of the training steps, compared to DeepSeek-R1-Zero pipeline. In the spirit of open source, we release our source code, parameter settings, training data, and model weights across various sizes.
Multi-matrix Factorization Attention
Dec 26, 2024



We propose novel attention architectures, Multi-matrix Factorization Attention (MFA) and MFA-Key-Reuse (MFA-KR). Existing variants for standard Multi-Head Attention (MHA), including SOTA methods like MLA, fail to maintain as strong performance under stringent Key-Value cache (KV cache) constraints. MFA enhances model capacity by efficiently scaling up both the number and dimension of attention heads through low-rank matrix factorization in the Query-Key (QK) circuit. Extending MFA, MFA-KR further reduces memory requirements by repurposing the key cache as value through value projection re-parameterization. MFA's design enables strong model capacity when working under tight KV cache budget, while MFA-KR is suitable for even harsher KV cache limits with minor performance trade-off. Notably, in our extensive and large-scale experiments, the proposed architecture outperforms MLA and performs comparably to MHA, while reducing KV cache usage by up to 56% and 93.7%, respectively.
Explore 3D Dance Generation via Reward Model from Automatically-Ranked Demonstrations
Dec 18, 2023This paper presents an Exploratory 3D Dance generation framework, E3D2, designed to address the exploration capability deficiency in existing music-conditioned 3D dance generation models. Current models often generate monotonous and simplistic dance sequences that misalign with human preferences because they lack exploration capabilities. The E3D2 framework involves a reward model trained from automatically-ranked dance demonstrations, which then guides the reinforcement learning process. This approach encourages the agent to explore and generate high quality and diverse dance movement sequences. The soundness of the reward model is both theoretically and experimentally validated. Empirical experiments demonstrate the effectiveness of E3D2 on the AIST++ dataset. Project Page: https://sites.google.com/view/e3d2.
A Perspective of Q-value Estimation on Offline-to-Online Reinforcement Learning
Dec 12, 2023
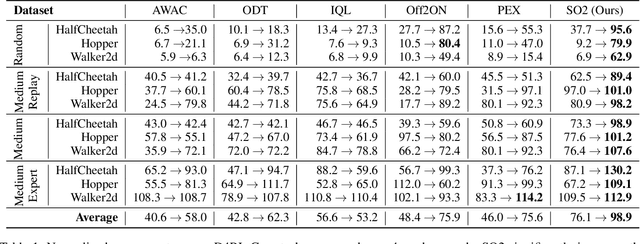
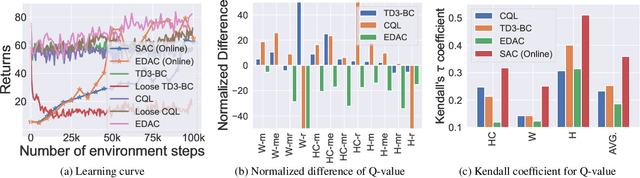

Offline-to-online Reinforcement Learning (O2O RL) aims to improve the performance of offline pretrained policy using only a few online samples. Built on offline RL algorithms, most O2O methods focus on the balance between RL objective and pessimism, or the utilization of offline and online samples. In this paper, from a novel perspective, we systematically study the challenges that remain in O2O RL and identify that the reason behind the slow improvement of the performance and the instability of online finetuning lies in the inaccurate Q-value estimation inherited from offline pretraining. Specifically, we demonstrate that the estimation bias and the inaccurate rank of Q-value cause a misleading signal for the policy update, making the standard offline RL algorithms, such as CQL and TD3-BC, ineffective in the online finetuning. Based on this observation, we address the problem of Q-value estimation by two techniques: (1) perturbed value update and (2) increased frequency of Q-value updates. The first technique smooths out biased Q-value estimation with sharp peaks, preventing early-stage policy exploitation of sub-optimal actions. The second one alleviates the estimation bias inherited from offline pretraining by accelerating learning. Extensive experiments on the MuJoco and Adroit environments demonstrate that the proposed method, named SO2, significantly alleviates Q-value estimation issues, and consistently improves the performance against the state-of-the-art methods by up to 83.1%.
Masked Pretraining for Multi-Agent Decision Making
Oct 18, 2023Building a single generalist agent with zero-shot capability has recently sparked significant advancements in decision-making. However, extending this capability to multi-agent scenarios presents challenges. Most current works struggle with zero-shot capabilities, due to two challenges particular to the multi-agent settings: a mismatch between centralized pretraining and decentralized execution, and varying agent numbers and action spaces, making it difficult to create generalizable representations across diverse downstream tasks. To overcome these challenges, we propose a \textbf{Mask}ed pretraining framework for \textbf{M}ulti-\textbf{a}gent decision making (MaskMA). This model, based on transformer architecture, employs a mask-based collaborative learning strategy suited for decentralized execution with partial observation. Moreover, MaskMA integrates a generalizable action representation by dividing the action space into actions toward self-information and actions related to other entities. This flexibility allows MaskMA to tackle tasks with varying agent numbers and thus different action spaces. Extensive experiments in SMAC reveal MaskMA, with a single model pretrained on 11 training maps, can achieve an impressive 77.8% zero-shot win rate on 60 unseen test maps by decentralized execution, while also performing effectively on other types of downstream tasks (\textit{e.g.,} varied policies collaboration and ad hoc team play).