 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOPlanner: Plan to Roll Out Conservatively but to Explore Optimistically for Model-Based RL
Oct 11, 2023
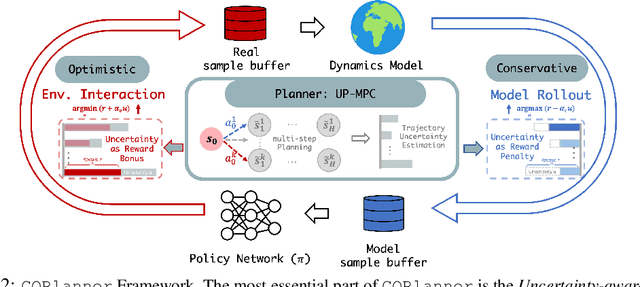
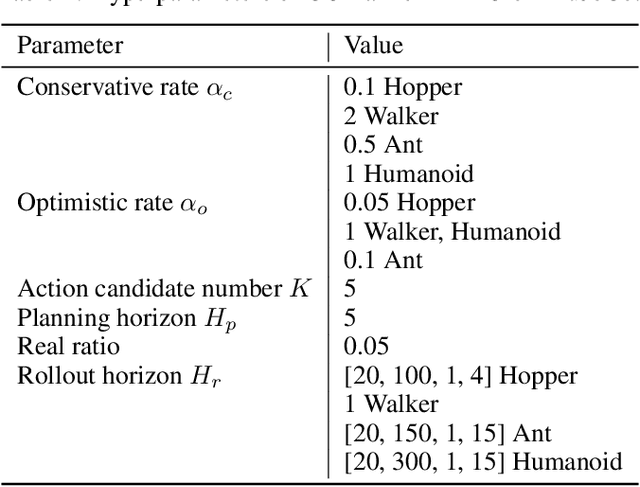

Dyna-style model-based reinforcement learning contains two phases: model rollouts to generate sample for policy learning and real environment exploration using current policy for dynamics model learning. However, due to the complex real-world environment, it is inevitable to learn an imperfect dynamics model with model prediction error, which can further mislead policy learning and result in sub-optimal solutions. In this paper, we propose $\texttt{COPlanner}$, a planning-driven framework for model-based methods to address the inaccurately learned dynamics model problem with conservative model rollouts and optimistic environment exploration. $\texttt{COPlanner}$ leverages an uncertainty-aware policy-guided model predictive control (UP-MPC) component to plan for multi-step uncertainty estimation. This estimated uncertainty then serves as a penalty during model rollouts and as a bonus during real environment exploration respectively, to choose actions. Consequently, $\texttt{COPlanner}$ can avoid model uncertain regions through conservative model rollouts, thereby alleviating the influence of model error. Simultaneously, it explores high-reward model uncertain regions to reduce model error actively through optimistic real environment exploration. $\texttt{COPlanner}$ is a plug-and-play framework that can be applied to any dyna-style model-based methods. Experimental results on a series of proprioceptive and visual continuous control tasks demonstrate that both sample efficiency and asymptotic performance of strong model-based methods are significantly improved combined with $\texttt{COPlanner}$.
Theoretically Guaranteed Policy Improvement Distilled from Model-Based Planning
Jul 24, 2023Model-based reinforcement learning (RL) has demonstrated remarkable successes on a range of continuous control tasks due to its high sample efficiency. To save the computation cost of conducting planning online, recent practices tend to distill optimized action sequences into an RL policy during the training phase. Although the distillation can incorporate both the foresight of planning and the exploration ability of RL policies, the theoretical understanding of these methods is yet unclear. In this paper, we extend the policy improvement step of Soft Actor-Critic (SAC) by developing an approach to distill from model-based planning to the policy. We then demonstrate that such an approach of policy improvement has a theoretical guarantee of monotonic improvement and convergence to the maximum value defined in SAC. We discuss effective design choices and implement our theory as a practical algorithm -- Model-based Planning Distilled to Policy (MPDP) -- that updates the policy jointly over multiple future time steps. Extensive experiments show that MPDP achieves better sample efficiency and asymptotic performance than both model-free and model-based planning algorithms on six continuous control benchmark tasks in MuJoCo.