 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePriorZero: Bridging Language Priors and World Models for Decision Making
May 12, 2026Leveraging the rich world knowledge of Large Language Models (LLMs) to enhance Reinforcement Learning (RL) agents offers a promising path toward general intelligence. However, a fundamental prior-dynamics mismatch hinders existing approaches: static LLM knowledge cannot directly adapt to the complex transition dynamics of long-horizon tasks. Using LLM priors as fixed policies limits exploration diversity, as the prior is blind to environment-specific dynamics; while end-to-end fine-tuning suffers from optimization instability and credit assignment issues. To bridge this gap, we propose PriorZero, a unified framework that integrates LLM-derived conceptual priors into world-model-based planning through a decoupled rollout-training design. During rollout, a novel root-prior injection mechanism incorporates LLM priors exclusively at the root node of Monte Carlo Tree Search (MCTS), focusing search on semantically promising actions while preserving the world model's deep lookahead capability. During training, PriorZero decouples world-model learning from LLM adaptation: the world model is continuously refined on interaction data to jointly improve its dynamics, policy, and value predictions, its value estimates are then leveraged to provide fine-grained credit assignment signals for stable LLM fine-tuning via alternating optimization. Experiments across diverse benchmarks, including text-based adventure games in Jericho and instruction-following gridworld tasks in BabyAI, demonstrate that PriorZero consistently improves both exploration efficiency and asymptotic performance, establishing a promising framework for LLM-empowered decision-making. Our code is available at https://github.com/opendilab/LightZero.
MetaphorStar: Image Metaphor Understanding and Reasoning with End-to-End Visual Reinforcement Learning
Feb 11, 2026Metaphorical comprehension in images remains a critical challenge for Nowadays AI systems. While Multimodal Large Language Models (MLLMs) excel at basic Visual Question Answering (VQA), they consistently struggle to grasp the nuanced cultural, emotional, and contextual implications embedded in visual content. This difficulty stems from the task's demand for sophisticated multi-hop reasoning, cultural context, and Theory of Mind (ToM) capabilities, which current models lack. To fill this gap, we propose MetaphorStar, the first end-to-end visual reinforcement learning (RL) framework for image implication tasks. Our framework includes three core components: the fine-grained dataset TFQ-Data, the visual RL method TFQ-GRPO, and the well-structured benchmark TFQ-Bench. Our fully open-source MetaphorStar family, trained using TFQ-GRPO on TFQ-Data, significantly improves performance by an average of 82.6% on the image implication benchmarks. Compared with 20+ mainstream MLLMs, MetaphorStar-32B achieves state-of-the-art (SOTA) on Multiple-Choice Question and Open-Style Question, significantly outperforms the top closed-source model Gemini-3.0-pro on True-False Question. Crucially, our experiments reveal that learning image implication tasks improves the general understanding ability, especially the complex visual reasoning ability. We further provide a systematic analysis of model parameter scaling, training data scaling, and the impact of different model architectures and training strategies, demonstrating the broad applicability of our method. We open-sourced all model weights, datasets, and method code at https://metaphorstar.github.io.
TreeTensor: Boost AI System on Nested Data with Constrained Tree-Like Tensor
Feb 09, 2026Tensor is the most basic and essential data structure of nowadays artificial intelligence (AI) system. The natural properties of Tensor, especially the memory-continuity and slice-independence, make it feasible for training system to leverage parallel computing unit like GPU to process data simultaneously in batch, spatial or temporal dimensions. However, if we look beyond perception tasks, the data in a complicated cognitive AI system usually has hierarchical structures (i.e. nested data) with various modalities. They are inconvenient and inefficient to program directly with conventional Tensor with fixed shape. To address this issue, we summarize two main computational patterns of nested data, and then propose a general nested data container: TreeTensor. Through various constraints and magic utilities of TreeTensor, one can apply arbitrary functions and operations to nested data with almost zero cost, including some famous machine learning libraries, such as Scikit-Learn, Numpy and PyTorch. Our approach utilizes a constrained tree-structure perspective to systematically model data relationships, and it can also easily be combined with other methods to extend more usages, such as asynchronous execution and variable-length data computation. Detailed examples and benchmarks show TreeTensor not only provides powerful usability in various problems, especially one of the most complicated AI systems at present: AlphaStar for StarCraftII, but also exhibits excellent runtime efficiency without any overhead. Our project is available at https://github.com/opendilab/DI-treetensor.
CoTZero: Annotation-Free Human-Like Vision Reasoning via Hierarchical Synthetic CoT
Feb 09, 2026Recent advances in vision-language models (VLMs) have markedly improved image-text alignment, yet they still fall short of human-like visual reasoning. A key limitation is that many VLMs rely on surface correlations rather than building logically coherent structured representations, which often leads to missed higher-level semantic structure and non-causal relational understanding, hindering compositional and verifiable reasoning. To address these limitations by introducing human models into the reasoning process, we propose CoTZero, an annotation-free paradigm with two components: (i) a dual-stage data synthesis approach and (ii) a cognition-aligned training method. In the first component, we draw inspiration from neurocognitive accounts of compositional productivity and global-to-local analysis. In the bottom-up stage, CoTZero extracts atomic visual primitives and incrementally composes them into diverse, structured question-reasoning forms. In the top-down stage, it enforces hierarchical reasoning by using coarse global structure to guide the interpretation of local details and causal relations. In the cognition-aligned training component, built on the synthesized CoT data, we introduce Cognitively Coherent Verifiable Rewards (CCVR) in Reinforcement Fine-Tuning (RFT) to further strengthen VLMs' hierarchical reasoning and generalization, providing stepwise feedback on reasoning coherence and factual correctness. Experiments show that CoTZero achieves an F1 score of 83.33 percent on our multi-level semantic inconsistency benchmark with lexical-perturbation negatives, across both in-domain and out-of-domain settings. Ablations confirm that each component contributes to more interpretable and human-aligned visual reasoning.
From Perception to Punchline: Empowering VLM with the Art of In-the-wild Meme
Dec 31, 2025Generating humorous memes is a challenging multimodal task that moves beyond direct image-to-caption supervision. It requires a nuanced reasoning over visual content, contextual cues, and subjective humor. To bridge this gap between visual perception and humorous punchline creation, we propose HUMOR}, a novel framework that guides VLMs through hierarchical reasoning and aligns them with group-wise human preferences. First, HUMOR employs a hierarchical, multi-path Chain-of-Thought (CoT): the model begins by identifying a template-level intent, then explores diverse reasoning paths under different contexts, and finally anchors onto a high-quality, context-specific path. This CoT supervision, which traces back from ground-truth captions, enhances reasoning diversity. We further analyze that this multi-path exploration with anchoring maintains a high expected humor quality, under the practical condition that high-quality paths retain significant probability mass. Second, to capture subjective humor, we train a pairwise reward model that operates within groups of memes sharing the same template. Following established theory, this approach ensures a consistent and robust proxy for human preference, even with subjective and noisy labels. The reward model then enables a group-wise reinforcement learning optimization, guaranteeing providing a theoretical guarantee for monotonic improvement within the trust region. Extensive experiments show that HUMOR empowers various VLMs with superior reasoning diversity, more reliable preference alignment, and higher overall meme quality. Beyond memes, our work presents a general training paradigm for open-ended, human-aligned multimodal generation, where success is guided by comparative judgment within coherent output group.
One Model for All Tasks: Leveraging Efficient World Models in Multi-Task Planning
Sep 09, 2025In heterogeneous multi-task learning, tasks not only exhibit diverse observation and action spaces but also vary substantially in intrinsic difficulty. While conventional multi-task world models like UniZero excel in single-task settings, we find that when handling large-scale heterogeneous environments, gradient conflicts and the loss of model plasticity often constrain their sample and computational efficiency. In this work, we address these challenges from two perspectives: the single learning iteration and the overall learning process. First, we investigate the impact of key design spaces on extending UniZero to multi-task planning. We find that a Mixture-of-Experts (MoE) architecture provides the most substantial performance gains by mitigating gradient conflicts, leading to our proposed model, \textit{ScaleZero}. Second, to dynamically balance the computational load across the learning process, we introduce an online, LoRA-based \textit{dynamic parameter scaling} (DPS) strategy. This strategy progressively integrates LoRA adapters in response to task-specific progress, enabling adaptive knowledge retention and parameter expansion. Empirical evaluations on standard benchmarks such as Atari, DMControl (DMC), and Jericho demonstrate that ScaleZero, relying exclusively on online reinforcement learning with one model, attains performance on par with specialized single-task baselines. Furthermore, when augmented with our dynamic parameter scaling strategy, our method achieves competitive performance while requiring only 80\% of the single-task environment interaction steps. These findings underscore the potential of ScaleZero for effective large-scale multi-task learning. Our code is available at \textcolor{magenta}{https://github.com/opendilab/LightZero}.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
Let Androids Dream of Electric Sheep: A Human-like Image Implication Understanding and Reasoning Framework
May 22, 2025Metaphorical comprehension in images remains a critical challenge for AI systems, as existing models struggle to grasp the nuanced cultural, emotional, and contextual implications embedded in visual content. While multimodal large language models (MLLMs) excel in basic Visual Question Answer (VQA) tasks, they struggle with a fundamental limitation on image implication tasks: contextual gaps that obscure the relationships between different visual elements and their abstract meanings. Inspired by the human cognitive process, we propose Let Androids Dream (LAD), a novel framework for image implication understanding and reasoning. LAD addresses contextual missing through the three-stage framework: (1) Perception: converting visual information into rich and multi-level textual representations, (2) Search: iteratively searching and integrating cross-domain knowledge to resolve ambiguity, and (3) Reasoning: generating context-alignment image implication via explicit reasoning. Our framework with the lightweight GPT-4o-mini model achieves SOTA performance compared to 15+ MLLMs on English image implication benchmark and a huge improvement on Chinese benchmark, performing comparable with the GPT-4o model on Multiple-Choice Question (MCQ) and outperforms 36.7% on Open-Style Question (OSQ). Additionally, our work provides new insights into how AI can more effectively interpret image implications, advancing the field of vision-language reasoning and human-AI interaction. Our project is publicly available at https://github.com/MING-ZCH/Let-Androids-Dream-of-Electric-Sheep.
Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning
Apr 15, 2025We introduce Kimina-Prover Preview, a large language model that pioneers a novel reasoning-driven exploration paradigm for formal theorem proving, as showcased in this preview release. Trained with a large-scale reinforcement learning pipeline from Qwen2.5-72B, Kimina-Prover demonstrates strong performance in Lean 4 proof generation by employing a structured reasoning pattern we term \textit{formal reasoning pattern}. This approach allows the model to emulate human problem-solving strategies in Lean, iteratively generating and refining proof steps. Kimina-Prover sets a new state-of-the-art on the miniF2F benchmark, reaching 80.7% with pass@8192. Beyond improved benchmark performance, our work yields several key insights: (1) Kimina-Prover exhibits high sample efficiency, delivering strong results even with minimal sampling (pass@1) and scaling effectively with computational budget, stemming from its unique reasoning pattern and RL training; (2) we demonstrate clear performance scaling with model size, a trend previously unobserved for neural theorem provers in formal mathematics; (3) the learned reasoning style, distinct from traditional search algorithms, shows potential to bridge the gap between formal verification and informal mathematical intuition. We open source distilled versions with 1.5B and 7B parameters of Kimina-Prover
Empowering LLMs in Decision Games through Algorithmic Data Synthesis
Mar 18, 2025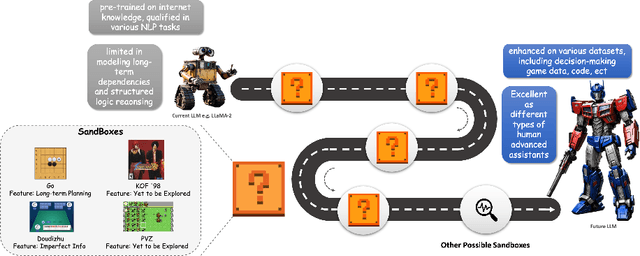
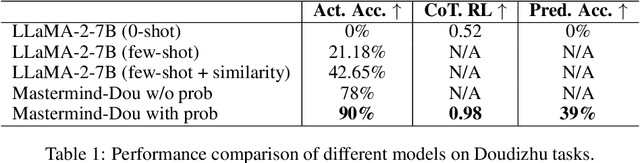
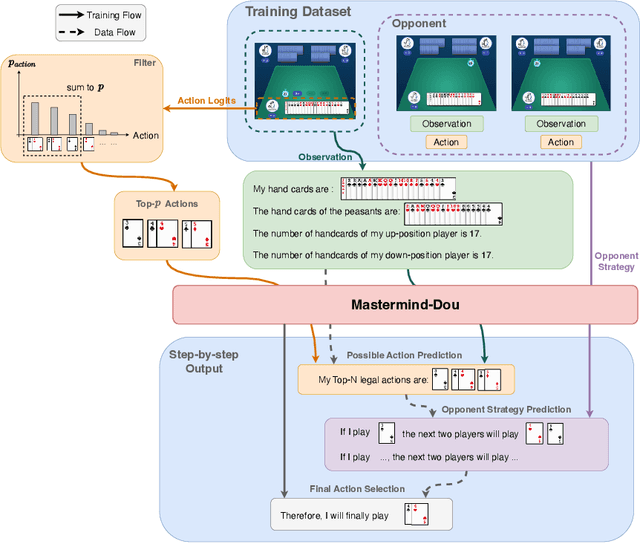

Large Language Models (LLMs) have exhibited impressive capabilities across numerous domains, yet they often struggle with complex reasoning and decision-making tasks. Decision-making games, which inherently require multifaceted reasoning logic, serve as ideal sandboxes for evaluating and enhancing the reasoning abilities of LLMs. In this work, we first explore whether LLMs can master complex decision-making games through targeted post-training. To this end, we design data synthesis strategies and curate extensive offline datasets from two classic games, Doudizhu and Go. We further develop a suite of techniques to effectively incorporate this data into LLM training, resulting in two novel agents: Mastermind-Dou and Mastermind-Go. Our experimental results demonstrate that these Mastermind LLMs achieve competitive performance in their respective games. Additionally, we explore whether integrating decision-making data can enhance the general reasoning abilities of LLMs. Our findings suggest that such post-training improves certain aspects of reasoning, providing valuable insights for optimizing LLM data collection and synthesis strategies.