 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning in a Combinatorial and Constrained World: Benchmarking LLMs on Natural-Language Combinatorial Optimization
Feb 02, 2026While large language models (LLMs) have shown strong performance in math and logic reasoning, their ability to handle combinatorial optimization (CO) -- searching high-dimensional solution spaces under hard constraints -- remains underexplored. To bridge the gap, we introduce NLCO, a \textbf{N}atural \textbf{L}anguage \textbf{C}ombinatorial \textbf{O}ptimization benchmark that evaluates LLMs on end-to-end CO reasoning: given a language-described decision-making scenario, the model must output a discrete solution without writing code or calling external solvers. NLCO covers 43 CO problems and is organized using a four-layer taxonomy of variable types, constraint families, global patterns, and objective classes, enabling fine-grained evaluation. We provide solver-annotated solutions and comprehensively evaluate LLMs by feasibility, solution optimality, and reasoning efficiency. Experiments across a wide range of modern LLMs show that high-performing models achieve strong feasibility and solution quality on small instances, but both degrade as instance size grows, even if more tokens are used for reasoning. We also observe systematic effects across the taxonomy: set-based tasks are relatively easy, whereas graph-structured problems and bottleneck objectives lead to more frequent failures.
Instance camera focus prediction for crystal agglomeration classification
Jan 13, 2026Agglomeration refers to the process of crystal clustering due to interparticle forces. Crystal agglomeration analysis from microscopic images is challenging due to the inherent limitations of two-dimensional imaging. Overlapping crystals may appear connected even when located at different depth layers. Because optical microscopes have a shallow depth of field, crystals that are in-focus and out-of-focus in the same image typically reside on different depth layers and do not constitute true agglomeration. To address this, we first quantified camera focus with an instance camera focus prediction network to predict 2 class focus level that aligns better with visual observations than traditional image processing focus measures. Then an instance segmentation model is combined with the predicted focus level for agglomeration classification. Our proposed method has a higher agglomeration classification and segmentation accuracy than the baseline models on ammonium perchlorate crystal and sugar crystal dataset.
Soft Conflict-Resolution Decision Transformer for Offline Multi-Task Reinforcement Learning
Nov 17, 2025Multi-task reinforcement learning (MTRL) seeks to learn a unified policy for diverse tasks, but often suffers from gradient conflicts across tasks. Existing masking-based methods attempt to mitigate such conflicts by assigning task-specific parameter masks. However, our empirical study shows that coarse-grained binary masks have the problem of over-suppressing key conflicting parameters, hindering knowledge sharing across tasks. Moreover, different tasks exhibit varying conflict levels, yet existing methods use a one-size-fits-all fixed sparsity strategy to keep training stability and performance, which proves inadequate. These limitations hinder the model's generalization and learning efficiency. To address these issues, we propose SoCo-DT, a Soft Conflict-resolution method based by parameter importance. By leveraging Fisher information, mask values are dynamically adjusted to retain important parameters while suppressing conflicting ones. In addition, we introduce a dynamic sparsity adjustment strategy based on the Interquartile Range (IQR), which constructs task-specific thresholding schemes using the distribution of conflict and harmony scores during training. To enable adaptive sparsity evolution throughout training, we further incorporate an asymmetric cosine annealing schedule to continuously update the threshold. Experimental results on the Meta-World benchmark show that SoCo-DT outperforms the state-of-the-art method by 7.6% on MT50 and by 10.5% on the suboptimal dataset, demonstrating its effectiveness in mitigating gradient conflicts and improving overall multi-task performance.
Learned Rate Control for Frame-Level Adaptive Neural Video Compression via Dynamic Neural Network
Aug 28, 2025Neural Video Compression (NVC) has achieved remarkable performance in recent years. However, precise rate control remains a challenge due to the inherent limitations of learning-based codecs. To solve this issue, we propose a dynamic video compression framework designed for variable bitrate scenarios. First, to achieve variable bitrate implementation, we propose the Dynamic-Route Autoencoder with variable coding routes, each occupying partial computational complexity of the whole network and navigating to a distinct RD trade-off. Second, to approach the target bitrate, the Rate Control Agent estimates the bitrate of each route and adjusts the coding route of DRA at run time. To encompass a broad spectrum of variable bitrates while preserving overall RD performance, we employ the Joint-Routes Optimization strategy, achieving collaborative training of various routes. Extensive experiments on the HEVC and UVG datasets show that the proposed method achieves an average BD-Rate reduction of 14.8% and BD-PSNR gain of 0.47dB over state-of-the-art methods while maintaining an average bitrate error of 1.66%, achieving Rate-Distortion-Complexity Optimization (RDCO) for various bitrate and bitrate-constrained applications. Our code is available at https://git.openi.org.cn/OpenAICoding/DynamicDVC.
Let Androids Dream of Electric Sheep: A Human-like Image Implication Understanding and Reasoning Framework
May 22, 2025Metaphorical comprehension in images remains a critical challenge for AI systems, as existing models struggle to grasp the nuanced cultural, emotional, and contextual implications embedded in visual content. While multimodal large language models (MLLMs) excel in basic Visual Question Answer (VQA) tasks, they struggle with a fundamental limitation on image implication tasks: contextual gaps that obscure the relationships between different visual elements and their abstract meanings. Inspired by the human cognitive process, we propose Let Androids Dream (LAD), a novel framework for image implication understanding and reasoning. LAD addresses contextual missing through the three-stage framework: (1) Perception: converting visual information into rich and multi-level textual representations, (2) Search: iteratively searching and integrating cross-domain knowledge to resolve ambiguity, and (3) Reasoning: generating context-alignment image implication via explicit reasoning. Our framework with the lightweight GPT-4o-mini model achieves SOTA performance compared to 15+ MLLMs on English image implication benchmark and a huge improvement on Chinese benchmark, performing comparable with the GPT-4o model on Multiple-Choice Question (MCQ) and outperforms 36.7% on Open-Style Question (OSQ). Additionally, our work provides new insights into how AI can more effectively interpret image implications, advancing the field of vision-language reasoning and human-AI interaction. Our project is publicly available at https://github.com/MING-ZCH/Let-Androids-Dream-of-Electric-Sheep.
Learn to Think: Bootstrapping LLM Reasoning Capability Through Graph Representation Learning
May 17, 2025Large Language Models (LLMs) have achieved remarkable success across various domains. However, they still face significant challenges, including high computational costs for training and limitations in solving complex reasoning problems. Although existing methods have extended the reasoning capabilities of LLMs through structured paradigms, these approaches often rely on task-specific prompts and predefined reasoning processes, which constrain their flexibility and generalizability. To address these limitations, we propose a novel framework that leverages graph learning to enable more flexible and adaptive reasoning capabilities for LLMs. Specifically, this approach models the reasoning process of a problem as a graph and employs LLM-based graph learning to guide the adaptive generation of each reasoning step. To further enhance the adaptability of the model, we introduce a Graph Neural Network (GNN) module to perform representation learning on the generated reasoning process, enabling real-time adjustments to both the model and the prompt. Experimental results demonstrate that this method significantly improves reasoning performance across multiple tasks without requiring additional training or task-specific prompt design. Code can be found in https://github.com/zch65458525/L2T.
Embodied Intelligent Industrial Robotics: Concepts and Techniques
May 15, 2025In recent years, embodied intelligent robotics (EIR) has made significant progress in multi-modal perception, autonomous decision-making, and physical interaction. Some robots have already been tested in general-purpose scenarios such as homes and shopping malls. We aim to advance the research and application of embodied intelligence in industrial scenes. However, current EIR lacks a deep understanding of industrial environment semantics and the normative constraints between industrial operating objects. To address this gap, this paper first reviews the history of industrial robotics and the mainstream EIR frameworks. We then introduce the concept of the embodied intelligent industrial robotics (EIIR) and propose a knowledge-driven EIIR technology framework for industrial environments. The framework includes four main modules: world model, high-level task planner, low-level skill controller, and simulator. We also review the current development of technologies related to each module and highlight recent progress in adapting them to industrial applications. Finally, we summarize the key challenges EIIR faces in industrial scenarios and suggest future research directions. We believe that EIIR technology will shape the next generation of industrial robotics. Industrial systems based on embodied intelligent industrial robots offer strong potential for enabling intelligent manufacturing. We will continue to track and summarize new research in this area and hope this review will serve as a valuable reference for scholars and engineers interested in industrial embodied intelligence. Together, we can help drive the rapid advancement and application of this technology. The associated project can be found at https://github.com/jackyzengl/EIIR.
GraphTEN: Graph Enhanced Texture Encoding Network
Mar 18, 2025
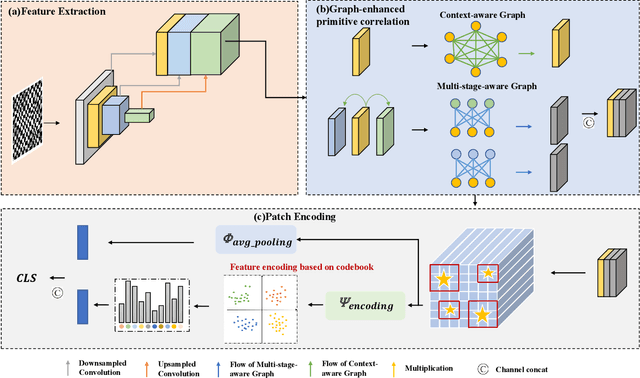


Texture recognition is a fundamental problem in computer vision and pattern recognition. Recent progress leverages feature aggregation into discriminative descriptions based on convolutional neural networks (CNNs). However, modeling non-local context relations through visual primitives remains challenging due to the variability and randomness of texture primitives in spatial distributions. In this paper, we propose a graph-enhanced texture encoding network (GraphTEN) designed to capture both local and global features of texture primitives. GraphTEN models global associations through fully connected graphs and captures cross-scale dependencies of texture primitives via bipartite graphs. Additionally, we introduce a patch encoding module that utilizes a codebook to achieve an orderless representation of texture by encoding multi-scale patch features into a unified feature space. The proposed GraphTEN achieves superior performance compared to state-of-the-art methods across five publicly available datasets.
CrossView-GS: Cross-view Gaussian Splatting For Large-scale Scene Reconstruction
Jan 03, 20253D Gaussian Splatting (3DGS) has emerged as a prominent method for scene representation and reconstruction, leveraging densely distributed Gaussian primitives to enable real-time rendering of high-resolution images. While existing 3DGS methods perform well in scenes with minor view variation, large view changes in cross-view scenes pose optimization challenges for these methods. To address these issues, we propose a novel cross-view Gaussian Splatting method for large-scale scene reconstruction, based on dual-branch fusion. Our method independently reconstructs models from aerial and ground views as two independent branches to establish the baselines of Gaussian distribution, providing reliable priors for cross-view reconstruction during both initialization and densification. Specifically, a gradient-aware regularization strategy is introduced to mitigate smoothing issues caused by significant view disparities. Additionally, a unique Gaussian supplementation strategy is utilized to incorporate complementary information of dual-branch into the cross-view model. Extensive experiments on benchmark datasets demonstrate that our method achieves superior performance in novel view synthesis compared to state-of-the-art methods.
Toward Efficient Data-Free Unlearning
Dec 18, 2024Machine unlearning without access to real data distribution is challenging. The existing method based on data-free distillation achieved unlearning by filtering out synthetic samples containing forgetting information but struggled to distill the retaining-related knowledge efficiently. In this work, we analyze that such a problem is due to over-filtering, which reduces the synthesized retaining-related information. We propose a novel method, Inhibited Synthetic PostFilter (ISPF), to tackle this challenge from two perspectives: First, the Inhibited Synthetic, by reducing the synthesized forgetting information; Second, the PostFilter, by fully utilizing the retaining-related information in synthesized samples. Experimental results demonstrate that the proposed ISPF effectively tackles the challenge and outperforms existing methods.