 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at the Application of Causal Inference in Graph Representation Learning
Apr 10, 2026Modeling causal relationships in graph representation learning remains a fundamental challenge. Existing approaches often draw on theories and methods from causal inference to identify causal subgraphs or mitigate confounders. However, due to the inherent complexity of graph-structured data, these approaches frequently aggregate diverse graph elements into single causal variables, an operation that risks violating the core assumptions of causal inference. In this work, we prove that such aggregation compromises causal validity. Building on this conclusion, we propose a theoretical model grounded in the smallest indivisible units of graph data to ensure that the causal validity is guaranteed. With this model, we further analyze the costs of achieving precise causal modeling in graph representation learning and identify the conditions under which the problem can be simplified. To empirically support our theory, we construct a controllable synthetic dataset that reflects realworld causal structures and conduct extensive experiments for validation. Finally, we develop a causal modeling enhancement module that can be seamlessly integrated into existing graph learning pipelines, and we demonstrate its effectiveness through comprehensive comparative experiments.
Causal Front-Door Adjustment for Robust Jailbreak Attacks on LLMs
Feb 05, 2026Safety alignment mechanisms in Large Language Models (LLMs) often operate as latent internal states, obscuring the model's inherent capabilities. Building on this observation, we model the safety mechanism as an unobserved confounder from a causal perspective. Then, we propose the \textbf{C}ausal \textbf{F}ront-Door \textbf{A}djustment \textbf{A}ttack ({\textbf{CFA}}$^2$) to jailbreak LLM, which is a framework that leverages Pearl's Front-Door Criterion to sever the confounding associations for robust jailbreaking. Specifically, we employ Sparse Autoencoders (SAEs) to physically strip defense-related features, isolating the core task intent. We further reduce computationally expensive marginalization to a deterministic intervention with low inference complexity. Experiments demonstrate that {CFA}$^2$ achieves state-of-the-art attack success rates while offering a mechanistic interpretation of the jailbreaking process.
Learn to Think: Bootstrapping LLM Reasoning Capability Through Graph Representation Learning
May 17, 2025Large Language Models (LLMs) have achieved remarkable success across various domains. However, they still face significant challenges, including high computational costs for training and limitations in solving complex reasoning problems. Although existing methods have extended the reasoning capabilities of LLMs through structured paradigms, these approaches often rely on task-specific prompts and predefined reasoning processes, which constrain their flexibility and generalizability. To address these limitations, we propose a novel framework that leverages graph learning to enable more flexible and adaptive reasoning capabilities for LLMs. Specifically, this approach models the reasoning process of a problem as a graph and employs LLM-based graph learning to guide the adaptive generation of each reasoning step. To further enhance the adaptability of the model, we introduce a Graph Neural Network (GNN) module to perform representation learning on the generated reasoning process, enabling real-time adjustments to both the model and the prompt. Experimental results demonstrate that this method significantly improves reasoning performance across multiple tasks without requiring additional training or task-specific prompt design. Code can be found in https://github.com/zch65458525/L2T.
Large Language Model Enhancers for Graph Neural Networks: An Analysis from the Perspective of Causal Mechanism Identification
May 15, 2025The use of large language models (LLMs) as feature enhancers to optimize node representations, which are then used as inputs for graph neural networks (GNNs), has shown significant potential in graph representation learning. However, the fundamental properties of this approach remain underexplored. To address this issue, we propose conducting a more in-depth analysis of this issue based on the interchange intervention method. First, we construct a synthetic graph dataset with controllable causal relationships, enabling precise manipulation of semantic relationships and causal modeling to provide data for analysis. Using this dataset, we conduct interchange interventions to examine the deeper properties of LLM enhancers and GNNs, uncovering their underlying logic and internal mechanisms. Building on the analytical results, we design a plug-and-play optimization module to improve the information transfer between LLM enhancers and GNNs. Experiments across multiple datasets and models validate the proposed module.
LLM Enhancers for GNNs: An Analysis from the Perspective of Causal Mechanism Identification
May 13, 2025The use of large language models (LLMs) as feature enhancers to optimize node representations, which are then used as inputs for graph neural networks (GNNs), has shown significant potential in graph representation learning. However, the fundamental properties of this approach remain underexplored. To address this issue, we propose conducting a more in-depth analysis of this issue based on the interchange intervention method. First, we construct a synthetic graph dataset with controllable causal relationships, enabling precise manipulation of semantic relationships and causal modeling to provide data for analysis. Using this dataset, we conduct interchange interventions to examine the deeper properties of LLM enhancers and GNNs, uncovering their underlying logic and internal mechanisms. Building on the analytical results, we design a plug-and-play optimization module to improve the information transfer between LLM enhancers and GNNs. Experiments across multiple datasets and models validate the proposed module.
Bootstrapping Heterogeneous Graph Representation Learning via Large Language Models: A Generalized Approach
Dec 11, 2024



Graph representation learning methods are highly effective in handling complex non-Euclidean data by capturing intricate relationships and features within graph structures. However, traditional methods face challenges when dealing with heterogeneous graphs that contain various types of nodes and edges due to the diverse sources and complex nature of the data. Existing Heterogeneous Graph Neural Networks (HGNNs) have shown promising results but require prior knowledge of node and edge types and unified node feature formats, which limits their applicability. Recent advancements in graph representation learning using Large Language Models (LLMs) offer new solutions by integrating LLMs' data processing capabilities, enabling the alignment of various graph representations. Nevertheless, these methods often overlook heterogeneous graph data and require extensive preprocessing. To address these limitations, we propose a novel method that leverages the strengths of both LLM and GNN, allowing for the processing of graph data with any format and type of nodes and edges without the need for type information or special preprocessing. Our method employs LLM to automatically summarize and classify different data formats and types, aligns node features, and uses a specialized GNN for targeted learning, thus obtaining effective graph representations for downstream tasks. Theoretical analysis and experimental validation have demonstrated the effectiveness of our method.
MBDS: A Multi-Body Dynamics Simulation Dataset for Graph Networks Simulators
Oct 04, 2024



Modeling the structure and events of the physical world constitutes a fundamental objective of neural networks. Among the diverse approaches, Graph Network Simulators (GNS) have emerged as the leading method for modeling physical phenomena, owing to their low computational cost and high accuracy. The datasets employed for training and evaluating physical simulation techniques are typically generated by researchers themselves, often resulting in limited data volume and quality. Consequently, this poses challenges in accurately assessing the performance of these methods. In response to this, we have constructed a high-quality physical simulation dataset encompassing 1D, 2D, and 3D scenes, along with more trajectories and time-steps compared to existing datasets. Furthermore, our work distinguishes itself by developing eight complete scenes, significantly enhancing the dataset's comprehensiveness. A key feature of our dataset is the inclusion of precise multi-body dynamics, facilitating a more realistic simulation of the physical world. Utilizing our high-quality dataset, we conducted a systematic evaluation of various existing GNS methods. Our dataset is accessible for download at https://github.com/Sherlocktein/MBDS, offering a valuable resource for researchers to enhance the training and evaluation of their methodologies.
Introducing Diminutive Causal Structure into Graph Representation Learning
Jun 13, 2024When engaging in end-to-end graph representation learning with Graph Neural Networks (GNNs), the intricate causal relationships and rules inherent in graph data pose a formidable challenge for the model in accurately capturing authentic data relationships. A proposed mitigating strategy involves the direct integration of rules or relationships corresponding to the graph data into the model. However, within the domain of graph representation learning, the inherent complexity of graph data obstructs the derivation of a comprehensive causal structure that encapsulates universal rules or relationships governing the entire dataset. Instead, only specialized diminutive causal structures, delineating specific causal relationships within constrained subsets of graph data, emerge as discernible. Motivated by empirical insights, it is observed that GNN models exhibit a tendency to converge towards such specialized causal structures during the training process. Consequently, we posit that the introduction of these specific causal structures is advantageous for the training of GNN models. Building upon this proposition, we introduce a novel method that enables GNN models to glean insights from these specialized diminutive causal structures, thereby enhancing overall performance. Our method specifically extracts causal knowledge from the model representation of these diminutive causal structures and incorporates interchange intervention to optimize the learning process. Theoretical analysis serves to corroborate the efficacy of our proposed method. Furthermore, empirical experiments consistently demonstrate significant performance improvements across diverse datasets.
Graph Partial Label Learning with Potential Cause Discovering
Mar 18, 2024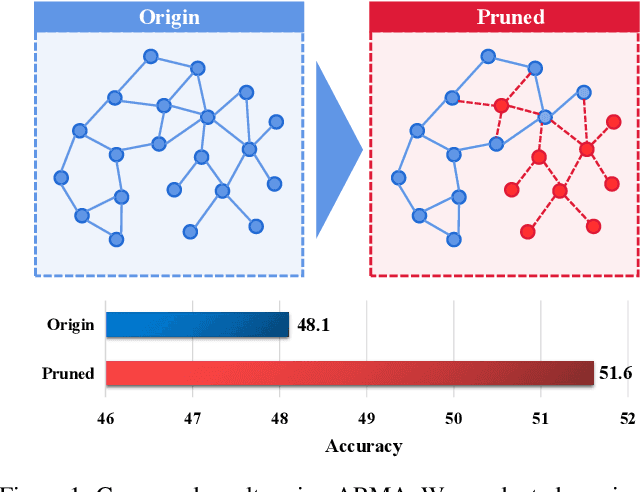
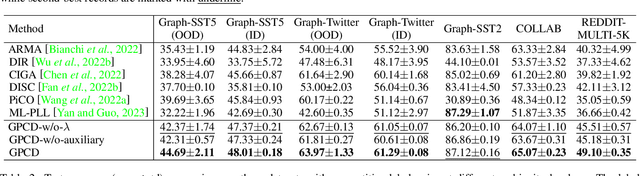
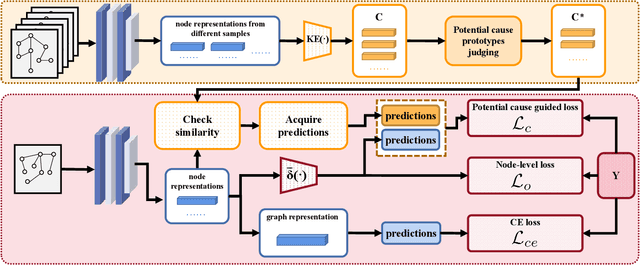
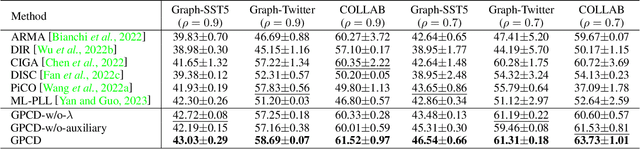
Graph Neural Networks (GNNs) have gained considerable attention for their potential in addressing challenges posed by complex graph-structured data in diverse domains. However, accurately annotating graph data for training is difficult due to the inherent complexity and interconnectedness of graphs. To tackle this issue, we propose a novel graph representation learning method that enables GNN models to effectively learn discriminative information even in the presence of noisy labels within the context of Partially Labeled Learning (PLL). PLL is a critical weakly supervised learning problem, where each training instance is associated with a set of candidate labels, including both the true label and additional noisy labels. Our approach leverages potential cause extraction to obtain graph data that exhibit a higher likelihood of possessing a causal relationship with the labels. By incorporating auxiliary training based on the extracted graph data, our model can effectively filter out the noise contained in the labels. We support the rationale behind our approach with a series of theoretical analyses. Moreover, we conduct extensive evaluations and ablation studies on multiple datasets, demonstrating the superiority of our proposed method.
Rethinking Causal Relationships Learning in Graph Neural Networks
Dec 15, 2023



Graph Neural Networks (GNNs) demonstrate their significance by effectively modeling complex interrelationships within graph-structured data. To enhance the credibility and robustness of GNNs, it becomes exceptionally crucial to bolster their ability to capture causal relationships. However, despite recent advancements that have indeed strengthened GNNs from a causal learning perspective, conducting an in-depth analysis specifically targeting the causal modeling prowess of GNNs remains an unresolved issue. In order to comprehensively analyze various GNN models from a causal learning perspective, we constructed an artificially synthesized dataset with known and controllable causal relationships between data and labels. The rationality of the generated data is further ensured through theoretical foundations. Drawing insights from analyses conducted using our dataset, we introduce a lightweight and highly adaptable GNN module designed to strengthen GNNs' causal learning capabilities across a diverse range of tasks. Through a series of experiments conducted on both synthetic datasets and other real-world datasets, we empirically validate the effectiveness of the proposed module.