 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHacking Task Confounder in Meta-Learning
Dec 10, 2023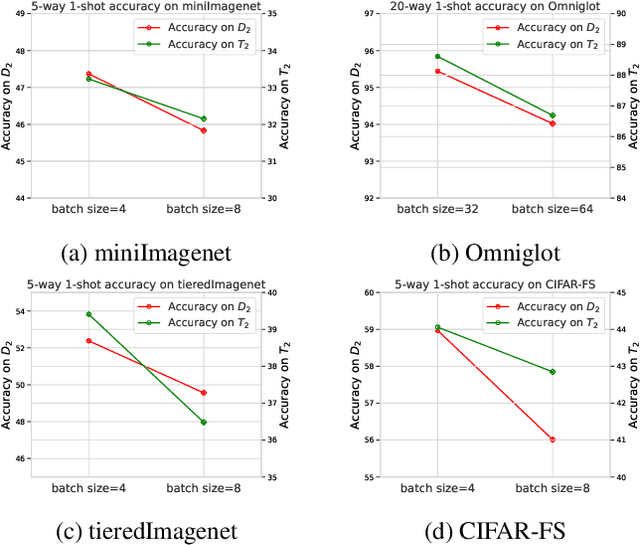
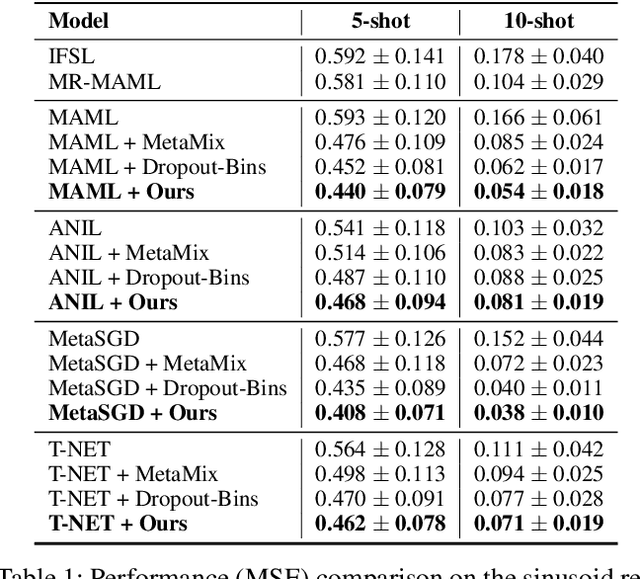
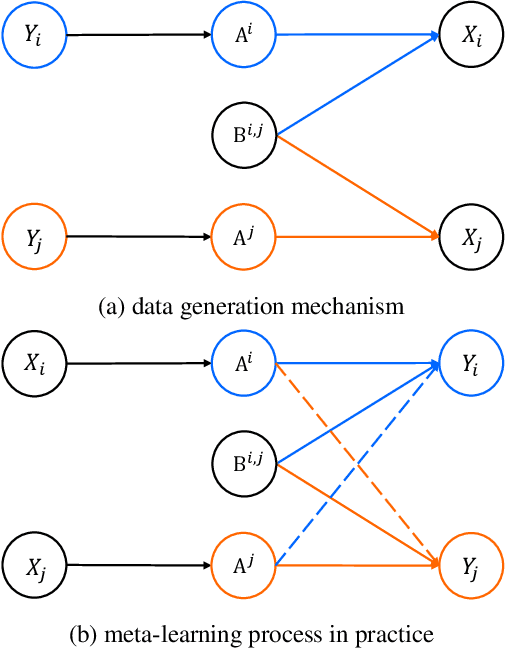
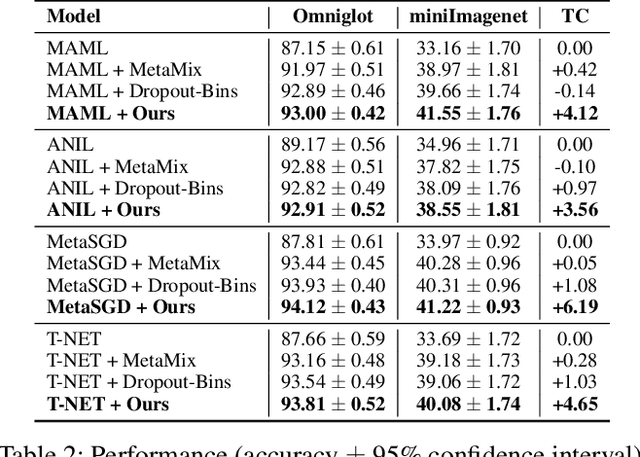
Meta-learning enables rapid generalization to new tasks by learning meta-knowledge from a variety of tasks. It is intuitively assumed that the more tasks a model learns in one training batch, the richer knowledge it acquires, leading to better generalization performance. However, contrary to this intuition, our experiments reveal an unexpected result: adding more tasks within a single batch actually degrades the generalization performance. To explain this unexpected phenomenon, we conduct a Structural Causal Model (SCM) for causal analysis. Our investigation uncovers the presence of spurious correlations between task-specific causal factors and labels in meta-learning. Furthermore, the confounding factors differ across different batches. We refer to these confounding factors as ``Task Confounders". Based on this insight, we propose a plug-and-play Meta-learning Causal Representation Learner (MetaCRL) to eliminate task confounders. It encodes decoupled causal factors from multiple tasks and utilizes an invariant-based bi-level optimization mechanism to ensure their causality for meta-learning. Extensive experiments on various benchmark datasets demonstrate that our work achieves state-of-the-art (SOTA) performance.
Towards the Sparseness of Projection Head in Self-Supervised Learning
Jul 19, 2023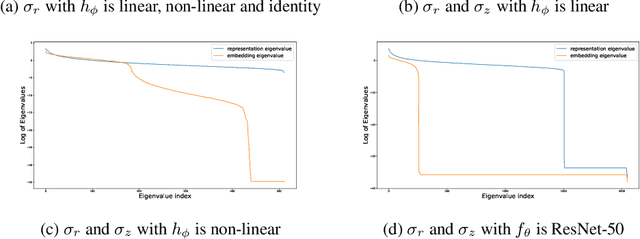
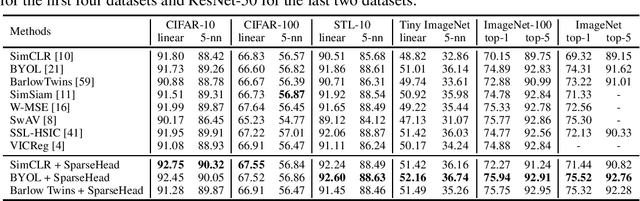
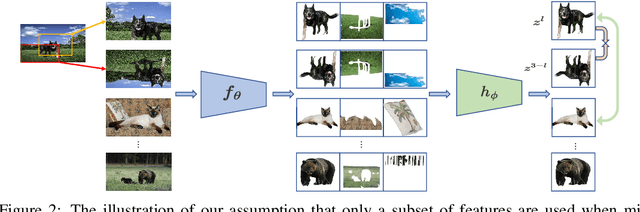
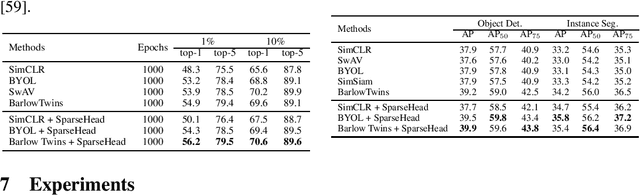
In recent years, self-supervised learning (SSL) has emerged as a promising approach for extracting valuable representations from unlabeled data. One successful SSL method is contrastive learning, which aims to bring positive examples closer while pushing negative examples apart. Many current contrastive learning approaches utilize a parameterized projection head. Through a combination of empirical analysis and theoretical investigation, we provide insights into the internal mechanisms of the projection head and its relationship with the phenomenon of dimensional collapse. Our findings demonstrate that the projection head enhances the quality of representations by performing contrastive loss in a projected subspace. Therefore, we propose an assumption that only a subset of features is necessary when minimizing the contrastive loss of a mini-batch of data. Theoretical analysis further suggests that a sparse projection head can enhance generalization, leading us to introduce SparseHead - a regularization term that effectively constrains the sparsity of the projection head, and can be seamlessly integrated with any self-supervised learning (SSL) approaches. Our experimental results validate the effectiveness of SparseHead, demonstrating its ability to improve the performance of existing contrastive methods.
Learning to Sample Tasks for Meta Learning
Jul 18, 2023Through experiments on various meta-learning methods, task samplers, and few-shot learning tasks, this paper arrives at three conclusions. Firstly, there are no universal task sampling strategies to guarantee the performance of meta-learning models. Secondly, task diversity can cause the models to either underfit or overfit during training. Lastly, the generalization performance of the models are influenced by task divergence, task entropy, and task difficulty. In response to these findings, we propose a novel task sampler called Adaptive Sampler (ASr). ASr is a plug-and-play task sampler that takes task divergence, task entropy, and task difficulty to sample tasks. To optimize ASr, we rethink and propose a simple and general meta-learning algorithm. Finally, a large number of empirical experiments demonstrate the effectiveness of the proposed ASr.
Manifold-Guided Sampling in Diffusion Models for Unbiased Image Generation
Jul 17, 2023Diffusion models are a powerful class of generative models that can produce high-quality images, but they may suffer from data bias. Data bias occurs when the training data does not reflect the true distribution of the data domain, but rather exhibits some skewed or imbalanced patterns. For example, the CelebA dataset contains more female images than male images, which can lead to biased generation results and affect downstream applications. In this paper, we propose a novel method to mitigate data bias in diffusion models by applying manifold guidance. Our key idea is to estimate the manifold of the training data using a learnable information-theoretic approach, and then use it to guide the sampling process of diffusion models. In this way, we can encourage the generated images to be uniformly distributed on the data manifold, without changing the model architecture or requiring labels or retraining. We provide theoretical analysis and empirical evidence to show that our method can improve the quality and unbiasedness of image generation compared to standard diffusion models.
A Unified GAN Framework Regarding Manifold Alignment for Remote Sensing Images Generation
May 31, 2023Generative Adversarial Networks (GANs) and their variants have achieved remarkable success on natural images. It aims to approximate the distribution of the training datasets. However, their performance degrades when applied to remote sensing (RS) images, and the discriminator often suffers from the overfitting problem. In this paper, we examine the differences between natural and RS images and find that the intrinsic dimensions of RS images are much lower than those of natural images. Besides, the low-dimensional data manifold of RS images may exacerbate the uneven sampling of training datasets and introduce biased information. The discriminator can easily overfit to the biased training distribution, leading to a faulty generation model, even the mode collapse problem. While existing GANs focus on the general distribution of RS datasets, they often neglect the underlying data manifold. In respond, we propose a learnable information-theoretic measure that preserves the intrinsic structures of the original data, and establish a unified GAN framework for manifold alignment in supervised and unsupervised RS image generation.
Intriguing Property of GAN for Remote Sensing Image Generation
Mar 09, 2023


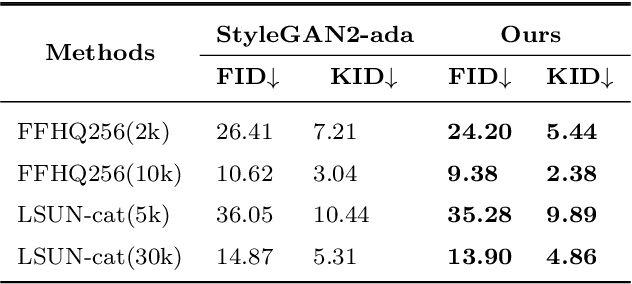
Generative adversarial networks (GANs) have achieved remarkable progress in the natural image field. However, when applying GANs in the remote sensing (RS) image generation task, we discover an extraordinary phenomenon: the GAN model is more sensitive to the size of training data for RS image generation than for natural image generation. In other words, the generation quality of RS images will change significantly with the number of training categories or samples per category. In this paper, we first analyze this phenomenon from two kinds of toy experiments and conclude that the amount of feature information contained in the GAN model decreases with reduced training data. Based on this discovery, we propose two innovative adjustment schemes, namely Uniformity Regularization (UR) and Entropy Regularization (ER), to increase the information learned by the GAN model at the distributional and sample levels, respectively. We theoretically and empirically demonstrate the effectiveness and versatility of our methods. Extensive experiments on the NWPU-RESISC45 and PatternNet datasets show that our methods outperform the well-established models on RS image generation tasks.
Introducing Expertise Logic into Graph Representation Learning from A Causal Perspective
Jan 20, 2023Benefiting from the injection of human prior knowledge, graphs, as derived discrete data, are semantically dense so that models can efficiently learn the semantic information from such data. Accordingly, graph neural networks (GNNs) indeed achieve impressive success in various fields. Revisiting the GNN learning paradigms, we discover that the relationship between human expertise and the knowledge modeled by GNNs still confuses researchers. To this end, we introduce motivating experiments and derive an empirical observation that the human expertise is gradually learned by the GNNs in general domains. By further observing the ramifications of introducing expertise logic into graph representation learning, we conclude that leading the GNNs to learn human expertise can improve the model performance. By exploring the intrinsic mechanism behind such observations, we elaborate the Structural Causal Model for the graph representation learning paradigm. Following the theoretical guidance, we innovatively introduce the auxiliary causal logic learning paradigm to improve the model to learn the expertise logic causally related to the graph representation learning task. In practice, the counterfactual technique is further performed to tackle the insufficient training issue during optimization. Plentiful experiments on the crafted and real-world domains support the consistent effectiveness of the proposed method.