 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizing Graph Foundation Models via Hyperbolic Retrieval-Augmented Generation
Jun 03, 2026Graph foundation models (GFMs) emerged as a dominant paradigm in graph representation learning by leveraging large-scale pre-training for cross-domain inference. However, the parameterized knowledge encoded within these models is insufficient to cope with distribution shifts, limiting their generalization ability. To mitigate this issue, retrieval-augmented generation (RAG) has been introduced to incorporate external knowledge at inference time. Nevertheless, existing RAG frameworks operating in Euclidean space suffer from a fundamental geometric limitation: the polynomial volume growth of Euclidean space is inherently mismatched with the tree-structured external knowledge bases. This mismatch leads to the loss of semantic granularity in retrieval and gives rise to the hubness phenomenon.To address this limitation, we propose a Hyperbolic Retrieval-Augmented Generation (HyRAG) framework designed to enhance the generalization capabilities of GFMs. Specifically, the introduced Hyperbolic Knowledge Indexing module retains the tree-like hierarchies of the external knowledge base by modeling them within hyperbolic space. The Multi-granularity Retrieval module then provides GFMs with the global semantic anchors and local semantic nuances through coarse-grained and fine-grained knowledge retrieval, respectively. Finally, the Dual-path Fusion module achieves effective knowledge integration for graph tasks at both the feature and structural levels. Experiments on multiple graph benchmarks demonstrate significant improvements in the zero-shot setting, highlighting the generalization of our method for robust GFMs inference.
Multi-modal Test-time Adaptation via Adaptive Probabilistic Gaussian Calibration
Apr 21, 2026Multi-modal test-time adaptation (TTA) enhances the resilience of benchmark multi-modal models against distribution shifts by leveraging the unlabeled target data during inference. Despite the documented success, the advancement of multi-modal TTA methodologies has been impeded by a persistent limitation, i.e., the lack of explicit modeling of category-conditional distributions, which is crucial for yielding accurate predictions and reliable decision boundaries. Canonical Gaussian discriminant analysis (GDA) provides a vanilla modeling of category-conditional distributions and achieves moderate advancement in uni-modal contexts. However, in multi-modal TTA scenario, the inherent modality distribution asymmetry undermines the effectiveness of modeling the category-conditional distribution via the canonical GDA. To this end, we introduce a tailored probabilistic Gaussian model for multi-modal TTA to explicitly model the category-conditional distributions, and further propose an adaptive contrastive asymmetry rectification technique to counteract the adverse effects arising from modality asymmetry, thereby deriving calibrated predictions and reliable decision boundaries. Extensive experiments across diverse benchmarks demonstrate that our method achieves state-of-the-art performance under a wide range of distribution shifts. The code is available at https://github.com/XuJinglinn/AdaPGC.
Test-Time Perturbation Learning with Delayed Feedback for Vision-Language-Action Models
Apr 20, 2026Vision-Language-Action models (VLAs) achieve remarkable performance in sequential decision-making but remain fragile to subtle environmental shifts, such as small changes in object pose. We attribute this brittleness to trajectory overfitting, where VLAs over-attend to the spurious correlation between actions and entities, then reproduce memorized action patterns. We propose Perturbation learning with Delayed Feedback (PDF), a verifier-free test-time adaptation framework that improves decision performance without fine-tuning the base model. PDF mitigates the spurious correlation through uncertainty-based data augmentation and action voting, while an adaptive scheduler allocates augmentation budgets to balance performance and efficiency. To further improve stability, PDF learns a lightweight perturbation module that retrospectively adjusts action logits guided by delayed feedback, correcting overconfidence issue. Experiments on LIBERO (+7.4\% success rate) and Atari (+10.3 human normalized score) demonstrate consistent gains of PDF in task success over vanilla VLA and VLA with test-time adaptation, establishing a practical path toward reliable test-time adaptation in multimodal decision-making agents. The code is available at \href{https://github.com/zhoujiahuan1991/CVPR2026-PDF}{https://github.com/zhoujiahuan1991/CVPR2026-PDF}.
* 12 pages, 7 figures, 5 tables
Vision-Language Attribute Disentanglement and Reinforcement for Lifelong Person Re-Identification
Mar 20, 2026Lifelong person re-identification (LReID) aims to learn from varying domains to obtain a unified person retrieval model. Existing LReID approaches typically focus on learning from scratch or a visual classification-pretrained model, while the Vision-Language Model (VLM) has shown generalizable knowledge in a variety of tasks. Although existing methods can be directly adapted to the VLM, since they only consider global-aware learning, the fine-grained attribute knowledge is underleveraged, leading to limited acquisition and anti-forgetting capacity. To address this problem, we introduce a novel VLM-driven LReID approach named Vision-Language Attribute Disentanglement and Reinforcement (VLADR). Our key idea is to explicitly model the universally shared human attributes to improve inter-domain knowledge transfer, thereby effectively utilizing historical knowledge to reinforce new knowledge learning and alleviate forgetting. Specifically, VLADR includes a Multi-grain Text Attribute Disentanglement mechanism that mines the global and diverse local text attributes of an image. Then, an Inter-domain Cross-modal Attribute Reinforcement scheme is developed, which introduces cross-modal attribute alignment to guide visual attribute extraction and adopts inter-domain attribute alignment to achieve fine-grained knowledge transfer. Experimental results demonstrate that our VLADR outperforms the state-of-the-art methods by 1.9\%-2.2\% and 2.1\%-2.5\% on anti-forgetting and generalization capacity. Our source code is available at https://github.com/zhoujiahuan1991/CVPR2026-VLADR
All-in-One Image Restoration via Causal-Deconfounding Wavelet-Disentangled Prompt Network
Mar 04, 2026Image restoration represents a promising approach for addressing the inherent defects of image content distortion. Standard image restoration approaches suffer from high storage cost and the requirement towards the known degradation pattern, including type and degree, which can barely be satisfied in dynamic practical scenarios. In contrast, all-in-one image restoration (AiOIR) eliminates multiple degradations within a unified model to circumvent the aforementioned issues. However, according to our causal analysis, we disclose that two significant defects still exacerbate the effectiveness and generalization of AiOIR models: 1) the spurious correlation between non-degradation semantic features and degradation patterns; 2) the biased estimation of degradation patterns. To obtain the true causation between degraded images and restored images, we propose Causal-deconfounding Wavelet-disentangled Prompt Network (CWP-Net) to perform effective AiOIR. CWP-Net introduces two modules for decoupling, i.e., wavelet attention module of encoder and wavelet attention module of decoder. These modules explicitly disentangle the degradation and semantic features to tackle the issue of spurious correlation. To address the issue stemming from the biased estimation of degradation patterns, CWP-Net leverages a wavelet prompt block to generate the alternative variable for causal deconfounding. Extensive experiments on two all-in-one settings prove the effectiveness and superior performance of our proposed CWP-Net over the state-of-the-art AiOIR methods.
AmPLe: Supporting Vision-Language Models via Adaptive-Debiased Ensemble Multi-Prompt Learning
Dec 20, 2025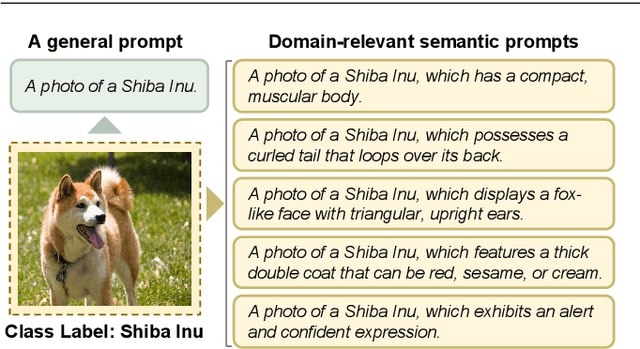

Multi-prompt learning methods have emerged as an effective approach for facilitating the rapid adaptation of vision-language models to downstream tasks with limited resources. Existing multi-prompt learning methods primarily focus on utilizing various meticulously designed prompts within a single foundation vision-language model to achieve superior performance. However, the overlooked model-prompt matching bias hinders the development of multi-prompt learning, i.e., the same prompt can convey different semantics across distinct vision-language models, such as CLIP-ViT-B/16 and CLIP-ViT-B/32, resulting in inconsistent predictions of identical prompt. To mitigate the impact of this bias on downstream tasks, we explore an ensemble learning approach to sufficiently aggregate the benefits of diverse predictions. Additionally, we further disclose the presence of sample-prompt matching bias, which originates from the prompt-irrelevant semantics encapsulated in the input samples. Thus, directly utilizing all information from the input samples for generating weights of ensemble learning can lead to suboptimal performance. In response, we extract prompt-relevant semantics from input samples by leveraging the guidance of the information theory-based analysis, adaptively calculating debiased ensemble weights. Overall, we propose Adaptive-Debiased Ensemble MultiPrompt Learning, abbreviated as AmPLe, to mitigate the two types of bias simultaneously. Extensive experiments on three representative tasks, i.e., generalization to novel classes, new target datasets, and unseen domain shifts, show that AmPLe can widely outperform existing methods. Theoretical validation from a causal perspective further supports the effectiveness of AmPLe.
Doubly Debiased Test-Time Prompt Tuning for Vision-Language Models
Nov 12, 2025Test-time prompt tuning for vision-language models has demonstrated impressive generalization capabilities under zero-shot settings. However, tuning the learnable prompts solely based on unlabeled test data may induce prompt optimization bias, ultimately leading to suboptimal performance on downstream tasks. In this work, we analyze the underlying causes of prompt optimization bias from both the model and data perspectives. In terms of the model, the entropy minimization objective typically focuses on reducing the entropy of model predictions while overlooking their correctness. This can result in overconfident yet incorrect outputs, thereby compromising the quality of prompt optimization. On the data side, prompts affected by optimization bias can introduce misalignment between visual and textual modalities, which further aggravates the prompt optimization bias. To this end, we propose a Doubly Debiased Test-Time Prompt Tuning method. Specifically, we first introduce a dynamic retrieval-augmented modulation module that retrieves high-confidence knowledge from a dynamic knowledge base using the test image feature as a query, and uses the retrieved knowledge to modulate the predictions. Guided by the refined predictions, we further develop a reliability-aware prompt optimization module that incorporates a confidence-based weighted ensemble and cross-modal consistency distillation to impose regularization constraints during prompt tuning. Extensive experiments across 15 benchmark datasets involving both natural distribution shifts and cross-datasets generalization demonstrate that our method outperforms baselines, validating its effectiveness in mitigating prompt optimization bias.
Self-Reinforcing Prototype Evolution with Dual-Knowledge Cooperation for Semi-Supervised Lifelong Person Re-Identification
Jul 02, 2025Current lifelong person re-identification (LReID) methods predominantly rely on fully labeled data streams. However, in real-world scenarios where annotation resources are limited, a vast amount of unlabeled data coexists with scarce labeled samples, leading to the Semi-Supervised LReID (Semi-LReID) problem where LReID methods suffer severe performance degradation. Existing LReID methods, even when combined with semi-supervised strategies, suffer from limited long-term adaptation performance due to struggling with the noisy knowledge occurring during unlabeled data utilization. In this paper, we pioneer the investigation of Semi-LReID, introducing a novel Self-Reinforcing Prototype Evolution with Dual-Knowledge Cooperation framework (SPRED). Our key innovation lies in establishing a self-reinforcing cycle between dynamic prototype-guided pseudo-label generation and new-old knowledge collaborative purification to enhance the utilization of unlabeled data. Specifically, learnable identity prototypes are introduced to dynamically capture the identity distributions and generate high-quality pseudo-labels. Then, the dual-knowledge cooperation scheme integrates current model specialization and historical model generalization, refining noisy pseudo-labels. Through this cyclic design, reliable pseudo-labels are progressively mined to improve current-stage learning and ensure positive knowledge propagation over long-term learning. Experiments on the established Semi-LReID benchmarks show that our SPRED achieves state-of-the-art performance. Our source code is available at https://github.com/zhoujiahuan1991/ICCV2025-SPRED
Multi-Modal Learning with Bayesian-Oriented Gradient Calibration
May 29, 2025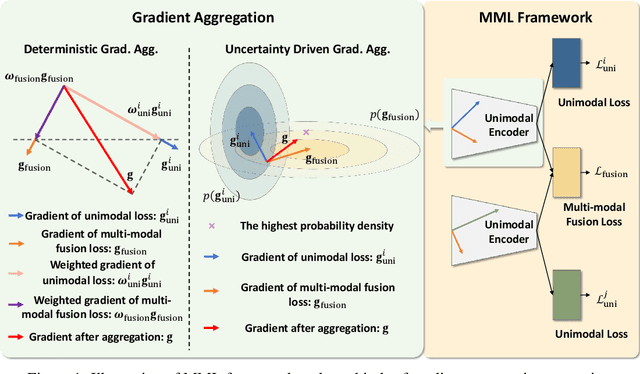
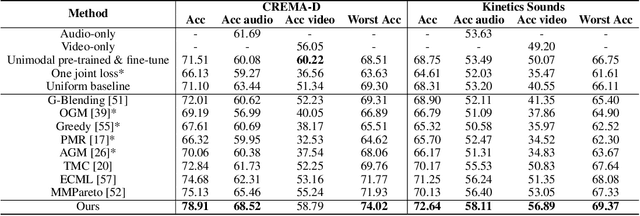
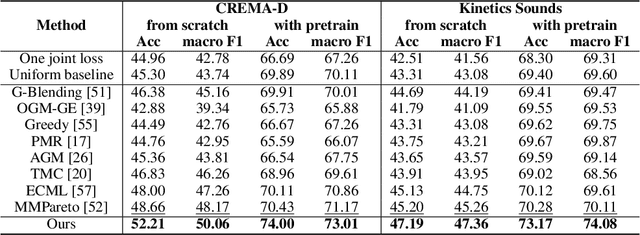
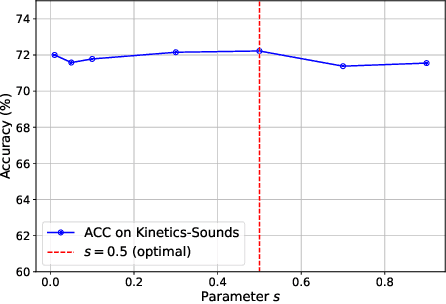
Multi-Modal Learning (MML) integrates information from diverse modalities to improve predictive accuracy. However, existing methods mainly aggregate gradients with fixed weights and treat all dimensions equally, overlooking the intrinsic gradient uncertainty of each modality. This may lead to (i) excessive updates in sensitive dimensions, degrading performance, and (ii) insufficient updates in less sensitive dimensions, hindering learning. To address this issue, we propose BOGC-MML, a Bayesian-Oriented Gradient Calibration method for MML to explicitly model the gradient uncertainty and guide the model optimization towards the optimal direction. Specifically, we first model each modality's gradient as a random variable and derive its probability distribution, capturing the full uncertainty in the gradient space. Then, we propose an effective method that converts the precision (inverse variance) of each gradient distribution into a scalar evidence. This evidence quantifies the confidence of each modality in every gradient dimension. Using these evidences, we explicitly quantify per-dimension uncertainties and fuse them via a reduced Dempster-Shafer rule. The resulting uncertainty-weighted aggregation produces a calibrated update direction that balances sensitivity and conservatism across dimensions. Extensive experiments on multiple benchmark datasets demonstrate the effectiveness and advantages of the proposed method.
On the Transferability and Discriminability of Repersentation Learning in Unsupervised Domain Adaptation
May 28, 2025In this paper, we addressed the limitation of relying solely on distribution alignment and source-domain empirical risk minimization in Unsupervised Domain Adaptation (UDA). Our information-theoretic analysis showed that this standard adversarial-based framework neglects the discriminability of target-domain features, leading to suboptimal performance. To bridge this theoretical-practical gap, we defined "good representation learning" as guaranteeing both transferability and discriminability, and proved that an additional loss term targeting target-domain discriminability is necessary. Building on these insights, we proposed a novel adversarial-based UDA framework that explicitly integrates a domain alignment objective with a discriminability-enhancing constraint. Instantiated as Domain-Invariant Representation Learning with Global and Local Consistency (RLGLC), our method leverages Asymmetrically-Relaxed Wasserstein of Wasserstein Distance (AR-WWD) to address class imbalance and semantic dimension weighting, and employs a local consistency mechanism to preserve fine-grained target-domain discriminative information. Extensive experiments across multiple benchmark datasets demonstrate that RLGLC consistently surpasses state-of-the-art methods, confirming the value of our theoretical perspective and underscoring the necessity of enforcing both transferability and discriminability in adversarial-based UDA.