 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Model, Two Minds: Task-Conditioned Reasoning for Unified Image Quality and Aesthetic Assessment
Mar 20, 2026Unifying Image Quality Assessment (IQA) and Image Aesthetic Assessment (IAA) in a single multimodal large language model is appealing, yet existing methods adopt a task-agnostic recipe that applies the same reasoning strategy and reward to both tasks. We show this is fundamentally misaligned: IQA relies on low-level, objective perceptual cues and benefits from concise distortion-focused reasoning, whereas IAA requires deliberative semantic judgment and is poorly served by point-wise score regression. We identify these as a reasoning mismatch and an optimization mismatch, and provide empirical evidence for both through controlled probes. Motivated by these findings, we propose TATAR (Task-Aware Thinking with Asymmetric Rewards), a unified framework that shares the visual-language backbone while conditioning post-training on each task's nature. TATAR combines three components: fast--slow task-specific reasoning construction that pairs IQA with concise perceptual rationales and IAA with deliberative aesthetic narratives; two-stage SFT+GRPO learning that establishes task-aware behavioral priors before reward-driven refinement; and asymmetric rewards that apply Gaussian score shaping for IQA and Thurstone-style completion ranking for IAA. Extensive experiments across eight benchmarks demonstrate that TATAR consistently outperforms prior unified baselines on both tasks under in-domain and cross-domain settings, remains competitive with task-specific specialized models, and yields more stable training dynamics for aesthetic assessment. Our results establish task-conditioned post-training as a principled paradigm for unified perceptual scoring. Our code is publicly available at https://github.com/yinwen2019/TATAR.
D3LM: A Discrete DNA Diffusion Language Model for Bidirectional DNA Understanding and Generation
Mar 02, 2026Early DNA foundation models adopted BERT-style training, achieving good performance on DNA understanding tasks but lacking generative capabilities. Recent autoregressive models enable DNA generation, but employ left-to-right causal modeling that is suboptimal for DNA where regulatory relationships are inherently bidirectional. We present D3LM (\textbf{D}iscrete \textbf{D}NA \textbf{D}iffusion \textbf{L}anguage \textbf{M}odel), which unifies bidirectional representation learning and DNA generation through masked diffusion. D3LM directly adopts the Nucleotide Transformer (NT) v2 architecture but reformulates the training objective as masked diffusion in discrete DNA space, enabling both bidirectional understanding and generation capabilities within a single model. Compared to NT v2 of the same size, D3LM achieves improved performance on understanding tasks. Notably, on regulatory element generation, D3LM achieves an SFID of 10.92, closely approaching real DNA sequences (7.85) and substantially outperforming the previous best result of 29.16 from autoregressive models. Our work suggests diffusion language models as a promising paradigm for unified DNA foundation models. We further present the first systematic study of masked diffusion models in the DNA domain, investigating practical design choices such as tokenization schemes and sampling strategies, thereby providing empirical insights and a solid foundation for future research. D3LM has been released at https://huggingface.co/collections/Hengchang-Liu/d3lm.
Extending Sequence Length is Not All You Need: Effective Integration of Multimodal Signals for Gene Expression Prediction
Feb 25, 2026Gene expression prediction, which predicts mRNA expression levels from DNA sequences, presents significant challenges. Previous works often focus on extending input sequence length to locate distal enhancers, which may influence target genes from hundreds of kilobases away. Our work first reveals that for current models, long sequence modeling can decrease performance. Even carefully designed algorithms only mitigate the performance degradation caused by long sequences. Instead, we find that proximal multimodal epigenomic signals near target genes prove more essential. Hence we focus on how to better integrate these signals, which has been overlooked. We find that different signal types serve distinct biological roles, with some directly marking active regulatory elements while others reflect background chromatin patterns that may introduce confounding effects. Simple concatenation may lead models to develop spurious associations with these background patterns. To address this challenge, we propose Prism, a framework that learns multiple combinations of high-dimensional epigenomic features to represent distinct background chromatin states and uses backdoor adjustment to mitigate confounding effects. Our experimental results demonstrate that proper modeling of multimodal epigenomic signals achieves state-of-the-art performance using only short sequences for gene expression prediction.
Diffusion LMs Can Approximate Optimal Infilling Lengths Implicitly
Jan 31, 2026Diffusion language models (DLMs) provide a bidirectional generation framework naturally suited for infilling, yet their performance is constrained by the pre-specified infilling length. In this paper, we reveal that DLMs possess an inherent ability to discover the correct infilling length. We identify two key statistical phenomena in the first-step denoising confidence: a local \textit{Oracle Peak} that emerges near the ground-truth length and a systematic \textit{Length Bias} that often obscures this signal. By leveraging this signal and calibrating the bias, our training-free method \textbf{CAL} (\textbf{C}alibrated \textbf{A}daptive \textbf{L}ength) enables DLMs to approximate the optimal length through an efficient search before formal decoding. Empirical evaluations demonstrate that CAL improves Pass@1 by up to 47.7\% over fixed-length baselines and 40.5\% over chat-based adaptive methods in code infilling, while boosting BLEU-2 and ROUGE-L by up to 8.5\% and 9.9\% in text infilling. These results demonstrate that CAL paves the way for robust DLM infilling without requiring any specialized training. Code is available at https://github.com/NiuHechang/Calibrated_Adaptive_Length.
Controlled LLM Training on Spectral Sphere
Jan 13, 2026Scaling large models requires optimization strategies that ensure rapid convergence grounded in stability. Maximal Update Parametrization ($\boldsymbolμ$P) provides a theoretical safeguard for width-invariant $Θ(1)$ activation control, whereas emerging optimizers like Muon are only ``half-aligned'' with these constraints: they control updates but allow weights to drift. To address this limitation, we introduce the \textbf{Spectral Sphere Optimizer (SSO)}, which enforces strict module-wise spectral constraints on both weights and their updates. By deriving the steepest descent direction on the spectral sphere, SSO realizes a fully $\boldsymbolμ$P-aligned optimization process. To enable large-scale training, we implement SSO as an efficient parallel algorithm within Megatron. Through extensive pretraining on diverse architectures, including Dense 1.7B, MoE 8B-A1B, and 200-layer DeepNet models, SSO consistently outperforms AdamW and Muon. Furthermore, we observe significant practical stability benefits, including improved MoE router load balancing, suppressed outliers, and strictly bounded activations.
Enhancing Human Motion Prediction via Multi-range Decoupling Decoding with Gating-adjusting Aggregation
Mar 30, 2025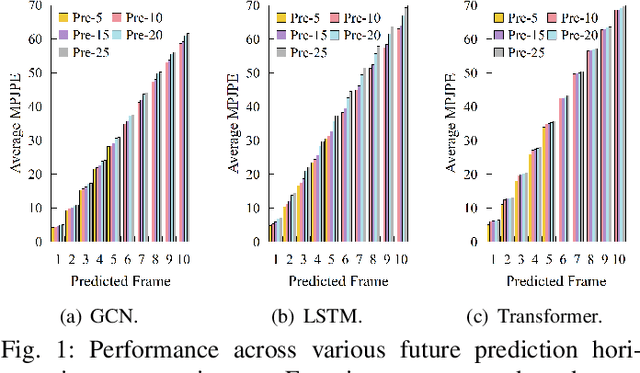
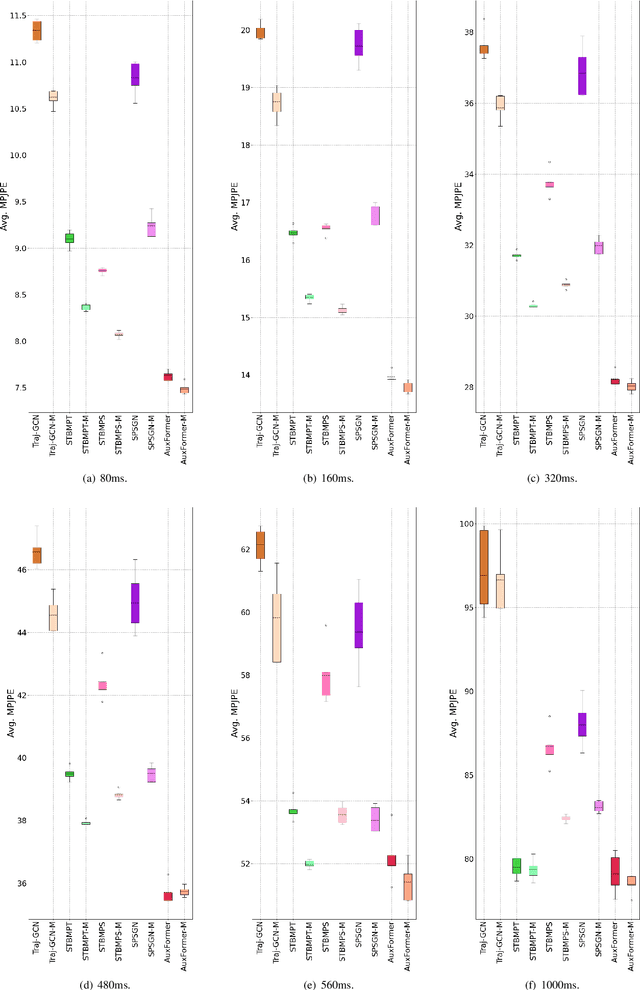
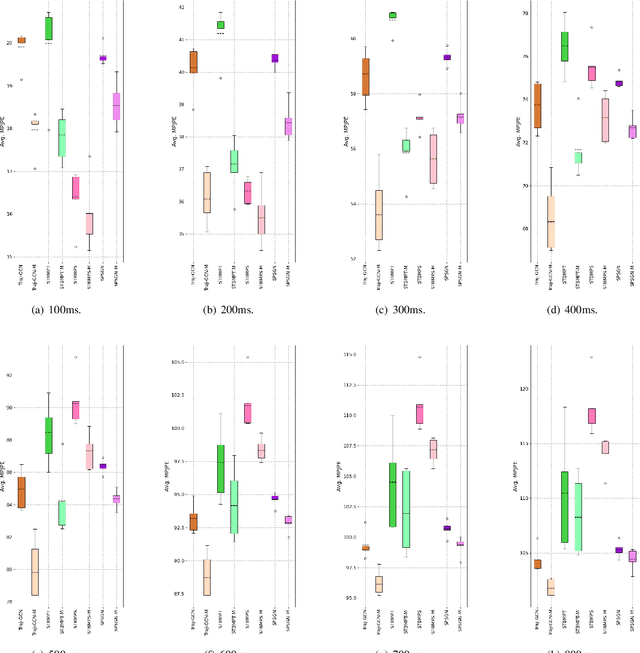
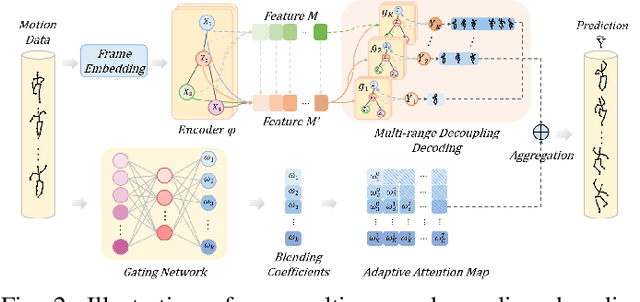
Expressive representation of pose sequences is crucial for accurate motion modeling in human motion prediction (HMP). While recent deep learning-based methods have shown promise in learning motion representations, these methods tend to overlook the varying relevance and dependencies between historical information and future moments, with a stronger correlation for short-term predictions and weaker for distant future predictions. This limits the learning of motion representation and then hampers prediction performance. In this paper, we propose a novel approach called multi-range decoupling decoding with gating-adjusting aggregation ($MD2GA$), which leverages the temporal correlations to refine motion representation learning. This approach employs a two-stage strategy for HMP. In the first stage, a multi-range decoupling decoding adeptly adjusts feature learning by decoding the shared features into distinct future lengths, where different decoders offer diverse insights into motion patterns. In the second stage, a gating-adjusting aggregation dynamically combines the diverse insights guided by input motion data. Extensive experiments demonstrate that the proposed method can be easily integrated into other motion prediction methods and enhance their prediction performance.
Learning Structure-enhanced Temporal Point Processes with Gromov-Wasserstein Regularization
Mar 29, 2025



Real-world event sequences are often generated by different temporal point processes (TPPs) and thus have clustering structures. Nonetheless, in the modeling and prediction of event sequences, most existing TPPs ignore the inherent clustering structures of the event sequences, leading to the models with unsatisfactory interpretability. In this study, we learn structure-enhanced TPPs with the help of Gromov-Wasserstein (GW) regularization, which imposes clustering structures on the sequence-level embeddings of the TPPs in the maximum likelihood estimation framework.In the training phase, the proposed method leverages a nonparametric TPP kernel to regularize the similarity matrix derived based on the sequence embeddings. In large-scale applications, we sample the kernel matrix and implement the regularization as a Gromov-Wasserstein (GW) discrepancy term, which achieves a trade-off between regularity and computational efficiency.The TPPs learned through this method result in clustered sequence embeddings and demonstrate competitive predictive and clustering performance, significantly improving the model interpretability without compromising prediction accuracy.
STOP: Integrated Spatial-Temporal Dynamic Prompting for Video Understanding
Mar 20, 2025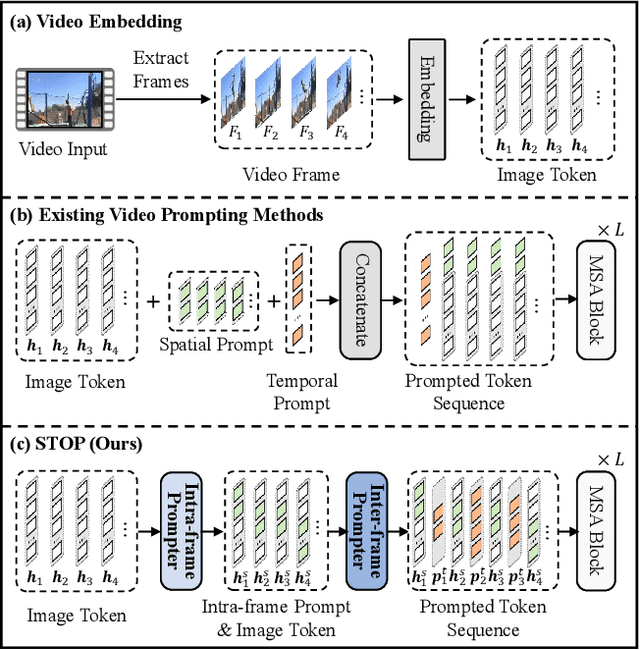
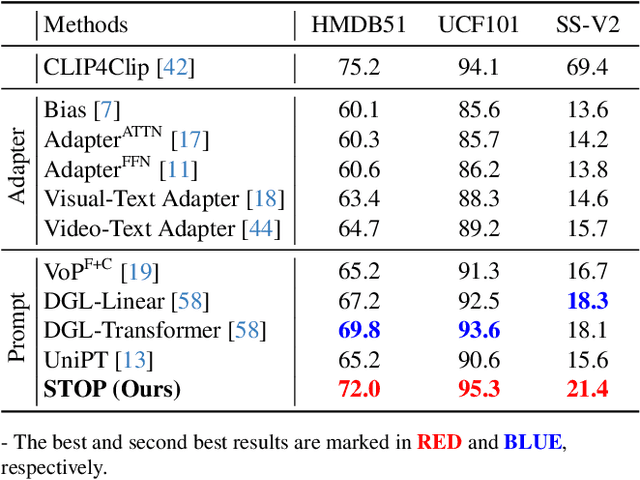
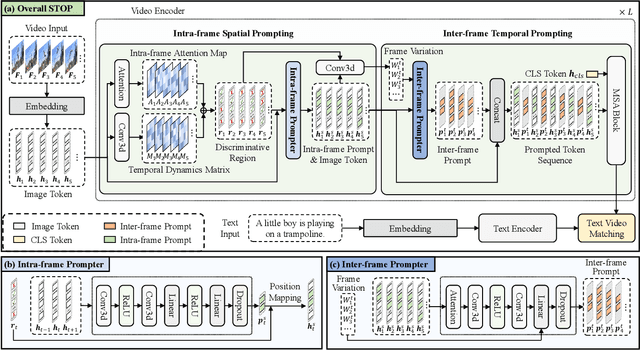
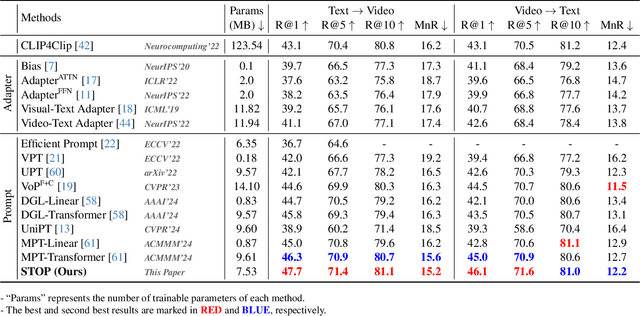
Pre-trained on tremendous image-text pairs, vision-language models like CLIP have demonstrated promising zero-shot generalization across numerous image-based tasks. However, extending these capabilities to video tasks remains challenging due to limited labeled video data and high training costs. Recent video prompting methods attempt to adapt CLIP for video tasks by introducing learnable prompts, but they typically rely on a single static prompt for all video sequences, overlooking the diverse temporal dynamics and spatial variations that exist across frames. This limitation significantly hinders the model's ability to capture essential temporal information for effective video understanding. To address this, we propose an integrated Spatial-TempOral dynamic Prompting (STOP) model which consists of two complementary modules, the intra-frame spatial prompting and inter-frame temporal prompting. Our intra-frame spatial prompts are designed to adaptively highlight discriminative regions within each frame by leveraging intra-frame attention and temporal variation, allowing the model to focus on areas with substantial temporal dynamics and capture fine-grained spatial details. Additionally, to highlight the varying importance of frames for video understanding, we further introduce inter-frame temporal prompts, dynamically inserting prompts between frames with high temporal variance as measured by frame similarity. This enables the model to prioritize key frames and enhances its capacity to understand temporal dependencies across sequences. Extensive experiments on various video benchmarks demonstrate that STOP consistently achieves superior performance against state-of-the-art methods. The code is available at https://github.com/zhoujiahuan1991/CVPR2025-STOP.
Regulatory DNA sequence Design with Reinforcement Learning
Mar 11, 2025
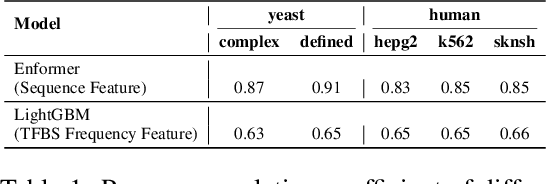


Cis-regulatory elements (CREs), such as promoters and enhancers, are relatively short DNA sequences that directly regulate gene expression. The fitness of CREs, measured by their ability to modulate gene expression, highly depends on the nucleotide sequences, especially specific motifs known as transcription factor binding sites (TFBSs). Designing high-fitness CREs is crucial for therapeutic and bioengineering applications. Current CRE design methods are limited by two major drawbacks: (1) they typically rely on iterative optimization strategies that modify existing sequences and are prone to local optima, and (2) they lack the guidance of biological prior knowledge in sequence optimization. In this paper, we address these limitations by proposing a generative approach that leverages reinforcement learning (RL) to fine-tune a pre-trained autoregressive (AR) model. Our method incorporates data-driven biological priors by deriving computational inference-based rewards that simulate the addition of activator TFBSs and removal of repressor TFBSs, which are then integrated into the RL process. We evaluate our method on promoter design tasks in two yeast media conditions and enhancer design tasks for three human cell types, demonstrating its ability to generate high-fitness CREs while maintaining sequence diversity. The code is available at https://github.com/yangzhao1230/TACO.
Rethinking the Bias of Foundation Model under Long-tailed Distribution
Jan 27, 2025
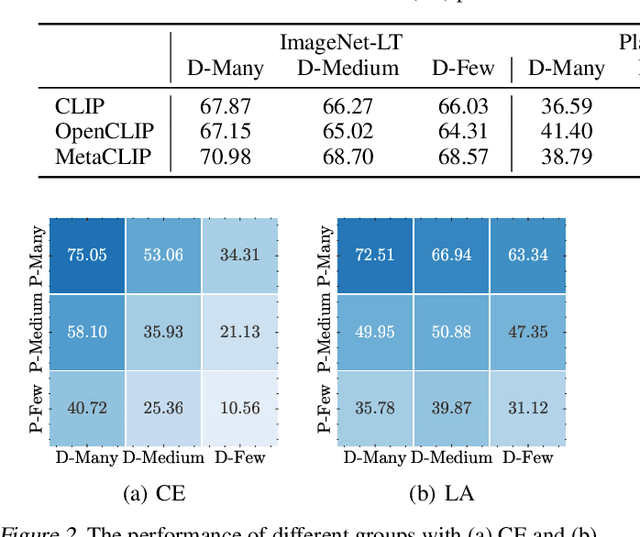
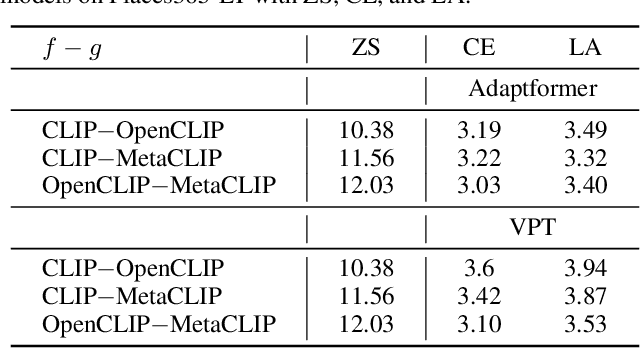
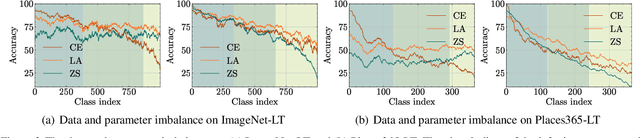
Long-tailed learning has garnered increasing attention due to its practical significance. Among the various approaches, the fine-tuning paradigm has gained considerable interest with the advent of foundation models. However, most existing methods primarily focus on leveraging knowledge from these models, overlooking the inherent biases introduced by the imbalanced training data they rely on. In this paper, we examine how such imbalances from pre-training affect long-tailed downstream tasks. Specifically, we find the imbalance biases inherited in foundation models on downstream task as parameter imbalance and data imbalance. During fine-tuning, we observe that parameter imbalance plays a more critical role, while data imbalance can be mitigated using existing re-balancing strategies. Moreover, we find that parameter imbalance cannot be effectively addressed by current re-balancing techniques, such as adjusting the logits, during training, unlike data imbalance. To tackle both imbalances simultaneously, we build our method on causal learning and view the incomplete semantic factor as the confounder, which brings spurious correlations between input samples and labels. To resolve the negative effects of this, we propose a novel backdoor adjustment method that learns the true causal effect between input samples and labels, rather than merely fitting the correlations in the data. Notably, we achieve an average performance increase of about $1.67\%$ on each dataset.