 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Human Motion Prediction via Multi-range Decoupling Decoding with Gating-adjusting Aggregation
Paper and Code
Mar 30, 2025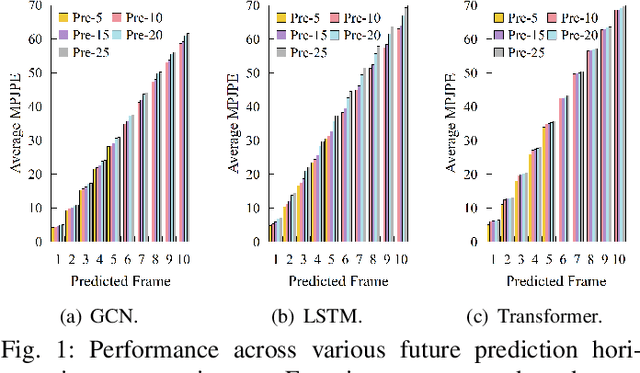
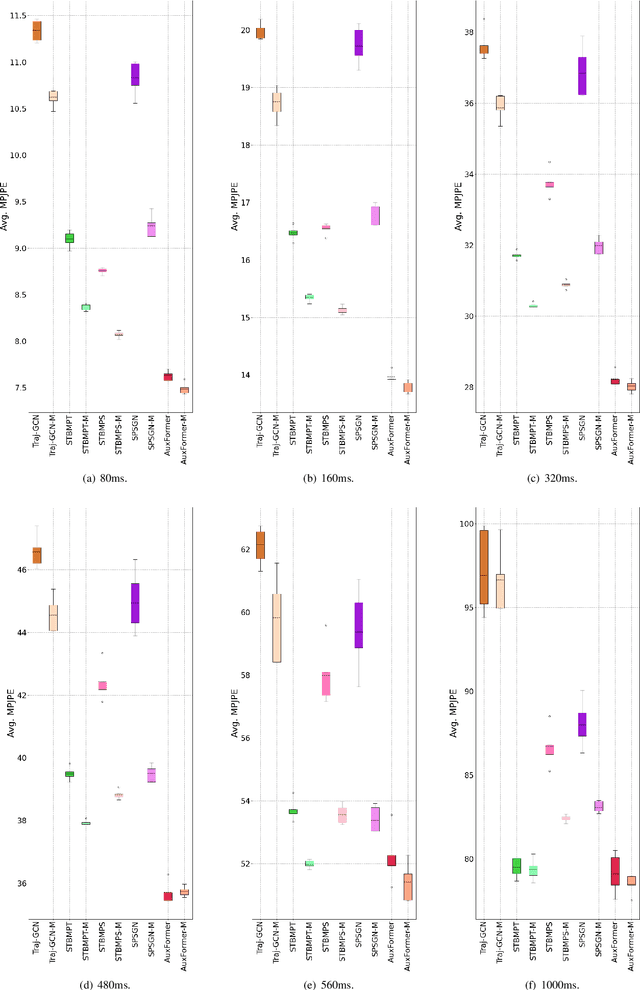
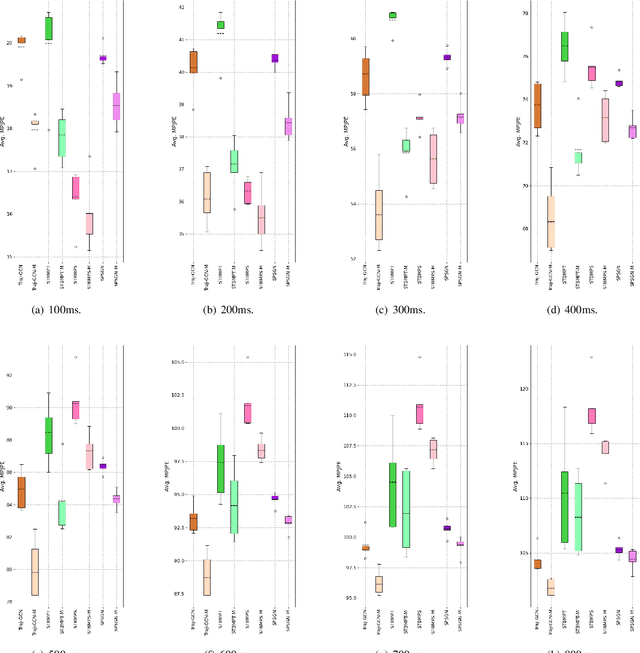
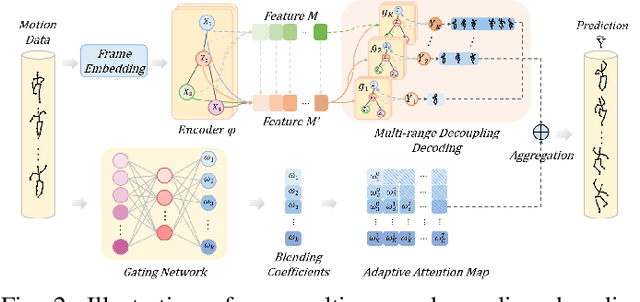
Expressive representation of pose sequences is crucial for accurate motion modeling in human motion prediction (HMP). While recent deep learning-based methods have shown promise in learning motion representations, these methods tend to overlook the varying relevance and dependencies between historical information and future moments, with a stronger correlation for short-term predictions and weaker for distant future predictions. This limits the learning of motion representation and then hampers prediction performance. In this paper, we propose a novel approach called multi-range decoupling decoding with gating-adjusting aggregation ($MD2GA$), which leverages the temporal correlations to refine motion representation learning. This approach employs a two-stage strategy for HMP. In the first stage, a multi-range decoupling decoding adeptly adjusts feature learning by decoding the shared features into distinct future lengths, where different decoders offer diverse insights into motion patterns. In the second stage, a gating-adjusting aggregation dynamically combines the diverse insights guided by input motion data. Extensive experiments demonstrate that the proposed method can be easily integrated into other motion prediction methods and enhance their prediction performance.