 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Human Motion Prediction via Multi-range Decoupling Decoding with Gating-adjusting Aggregation
Mar 30, 2025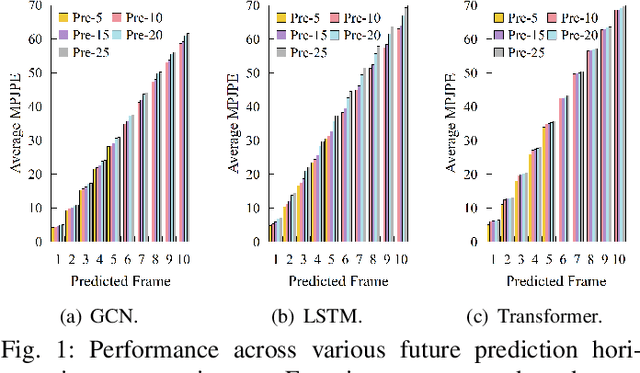
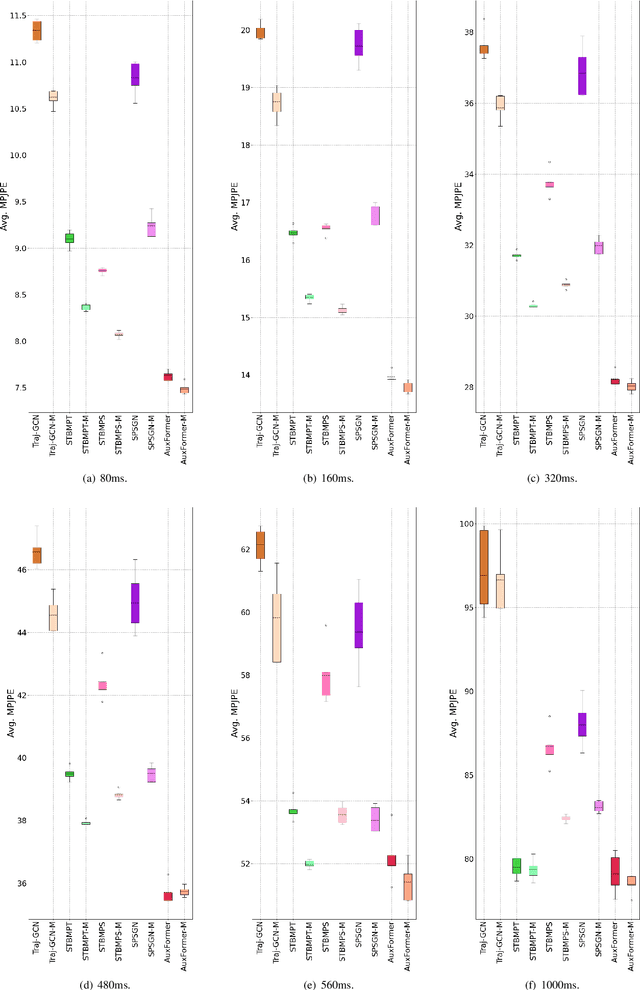
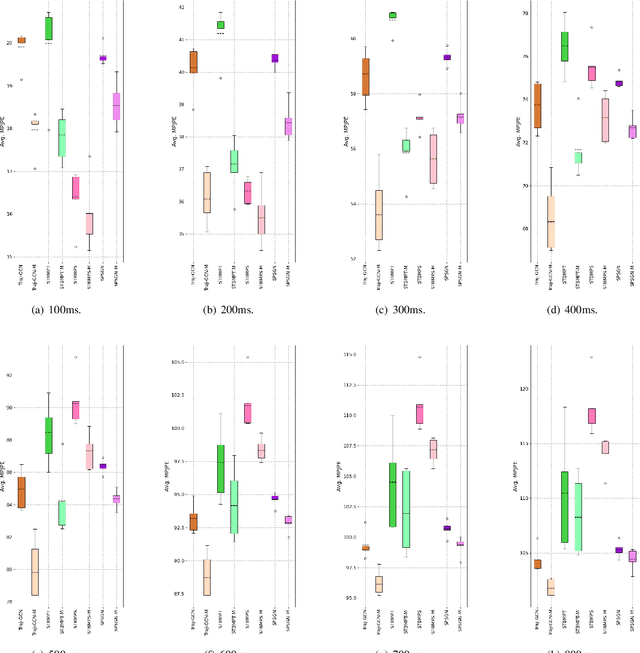
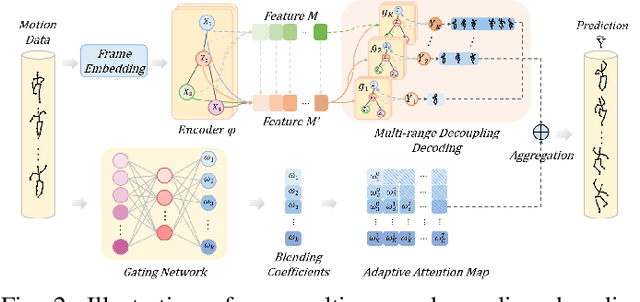
Expressive representation of pose sequences is crucial for accurate motion modeling in human motion prediction (HMP). While recent deep learning-based methods have shown promise in learning motion representations, these methods tend to overlook the varying relevance and dependencies between historical information and future moments, with a stronger correlation for short-term predictions and weaker for distant future predictions. This limits the learning of motion representation and then hampers prediction performance. In this paper, we propose a novel approach called multi-range decoupling decoding with gating-adjusting aggregation ($MD2GA$), which leverages the temporal correlations to refine motion representation learning. This approach employs a two-stage strategy for HMP. In the first stage, a multi-range decoupling decoding adeptly adjusts feature learning by decoding the shared features into distinct future lengths, where different decoders offer diverse insights into motion patterns. In the second stage, a gating-adjusting aggregation dynamically combines the diverse insights guided by input motion data. Extensive experiments demonstrate that the proposed method can be easily integrated into other motion prediction methods and enhance their prediction performance.
Temporal Dynamics Decoupling with Inverse Processing for Enhancing Human Motion Prediction
Dec 31, 2024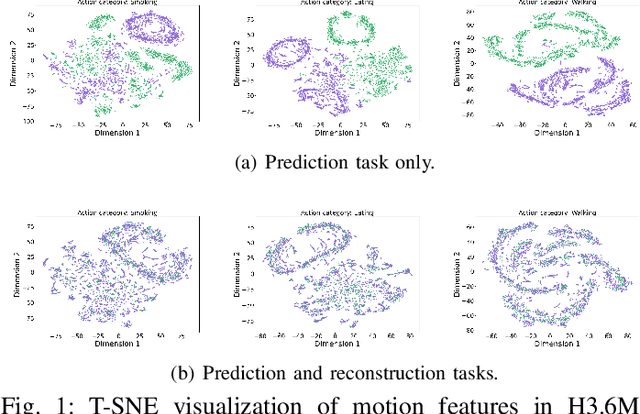
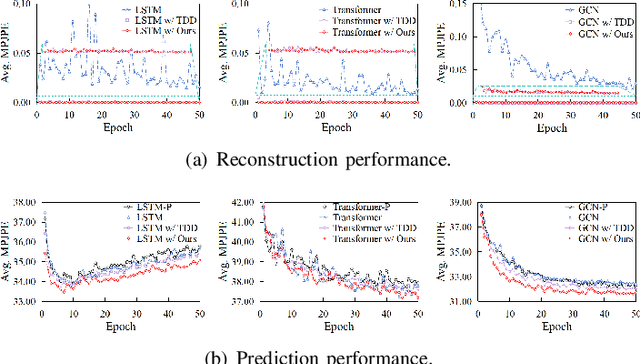
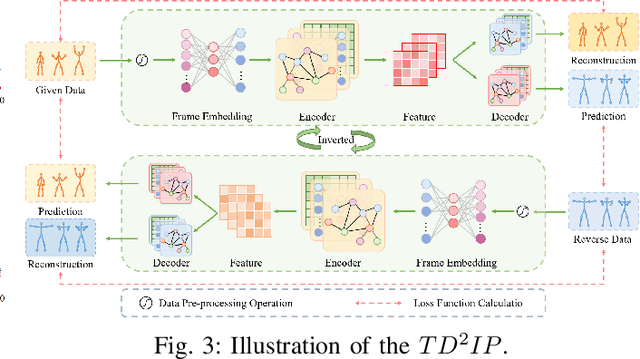
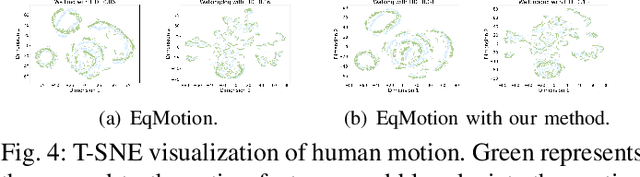
Exploring the bridge between historical and future motion behaviors remains a central challenge in human motion prediction. While most existing methods incorporate a reconstruction task as an auxiliary task into the decoder, thereby improving the modeling of spatio-temporal dependencies, they overlook the potential conflicts between reconstruction and prediction tasks. In this paper, we propose a novel approach: Temporal Decoupling Decoding with Inverse Processing (\textbf{$TD^2IP$}). Our method strategically separates reconstruction and prediction decoding processes, employing distinct decoders to decode the shared motion features into historical or future sequences. Additionally, inverse processing reverses motion information in the temporal dimension and reintroduces it into the model, leveraging the bidirectional temporal correlation of human motion behaviors. By alleviating the conflicts between reconstruction and prediction tasks and enhancing the association of historical and future information, \textbf{$TD^2IP$} fosters a deeper understanding of motion patterns. Extensive experiments demonstrate the adaptability of our method within existing methods.
Spatio-Temporal Multi-Subgraph GCN for 3D Human Motion Prediction
Dec 31, 2024



Human motion prediction (HMP) involves forecasting future human motion based on historical data. Graph Convolutional Networks (GCNs) have garnered widespread attention in this field for their proficiency in capturing relationships among joints in human motion. However, existing GCN-based methods tend to focus on either temporal-domain or spatial-domain features, or they combine spatio-temporal features without fully leveraging the complementarity and cross-dependency of these two features. In this paper, we propose the Spatial-Temporal Multi-Subgraph Graph Convolutional Network (STMS-GCN) to capture complex spatio-temporal dependencies in human motion. Specifically, we decouple the modeling of temporal and spatial dependencies, enabling cross-domain knowledge transfer at multiple scales through a spatio-temporal information consistency constraint mechanism. Besides, we utilize multiple subgraphs to extract richer motion information and enhance the learning associations of diverse subgraphs through a homogeneous information constraint mechanism. Extensive experiments on the standard HMP benchmarks demonstrate the superiority of our method.
Is Your AI-Generated Code Really Safe? Evaluating Large Language Models on Secure Code Generation with CodeSecEval
Jul 04, 2024

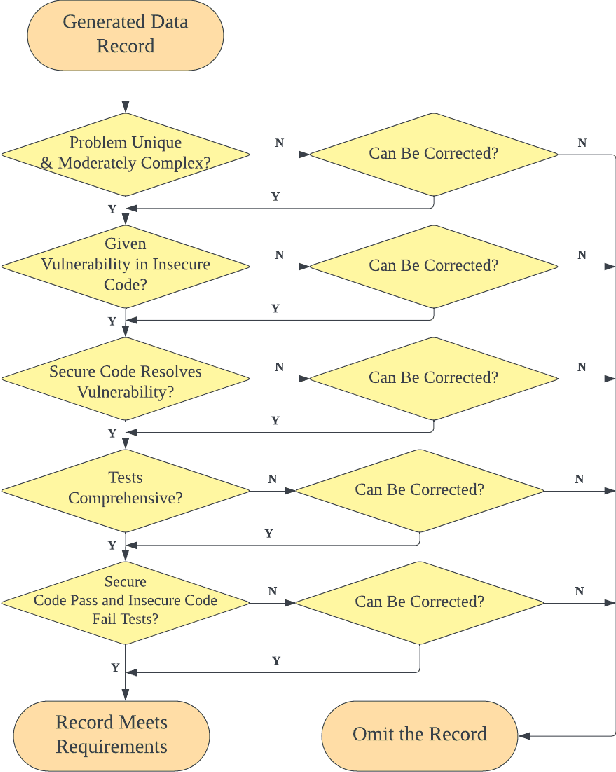

Large language models (LLMs) have brought significant advancements to code generation and code repair, benefiting both novice and experienced developers. However, their training using unsanitized data from open-source repositories, like GitHub, raises the risk of inadvertently propagating security vulnerabilities. Despite numerous studies investigating the safety of code LLMs, there remains a gap in comprehensively addressing their security features. In this work, we aim to present a comprehensive study aimed at precisely evaluating and enhancing the security aspects of code LLMs. To support our research, we introduce CodeSecEval, a meticulously curated dataset designed to address 44 critical vulnerability types with 180 distinct samples. CodeSecEval serves as the foundation for the automatic evaluation of code models in two crucial tasks: code generation and code repair, with a strong emphasis on security. Our experimental results reveal that current models frequently overlook security issues during both code generation and repair processes, resulting in the creation of vulnerable code. In response, we propose different strategies that leverage vulnerability-aware information and insecure code explanations to mitigate these security vulnerabilities. Furthermore, our findings highlight that certain vulnerability types particularly challenge model performance, influencing their effectiveness in real-world applications. Based on these findings, we believe our study will have a positive impact on the software engineering community, inspiring the development of improved methods for training and utilizing LLMs, thereby leading to safer and more trustworthy model deployment.
Is Your AI-Generated Code Really Secure? Evaluating Large Language Models on Secure Code Generation with CodeSecEval
Jul 02, 2024Large language models (LLMs) have brought significant advancements to code generation and code repair, benefiting both novice and experienced developers. However, their training using unsanitized data from open-source repositories, like GitHub, raises the risk of inadvertently propagating security vulnerabilities. Despite numerous studies investigating the safety of code LLMs, there remains a gap in comprehensively addressing their security features. In this work, we aim to present a comprehensive study aimed at precisely evaluating and enhancing the security aspects of code LLMs. To support our research, we introduce CodeSecEval, a meticulously curated dataset designed to address 44 critical vulnerability types with 180 distinct samples. CodeSecEval serves as the foundation for the automatic evaluation of code models in two crucial tasks: code generation and code repair, with a strong emphasis on security. Our experimental results reveal that current models frequently overlook security issues during both code generation and repair processes, resulting in the creation of vulnerable code. In response, we propose different strategies that leverage vulnerability-aware information and insecure code explanations to mitigate these security vulnerabilities. Furthermore, our findings highlight that certain vulnerability types particularly challenge model performance, influencing their effectiveness in real-world applications. Based on these findings, we believe our study will have a positive impact on the software engineering community, inspiring the development of improved methods for training and utilizing LLMs, thereby leading to safer and more trustworthy model deployment.
Towards Effective Time-Aware Language Representation: Exploring Enhanced Temporal Understanding in Language Models
Jun 04, 2024
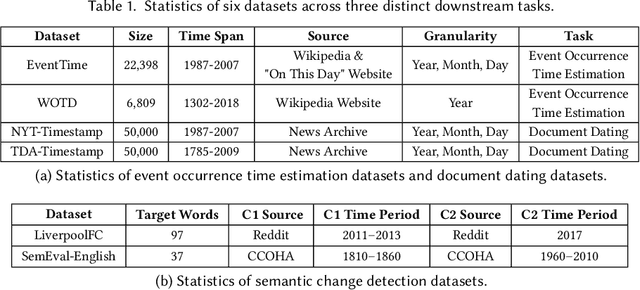

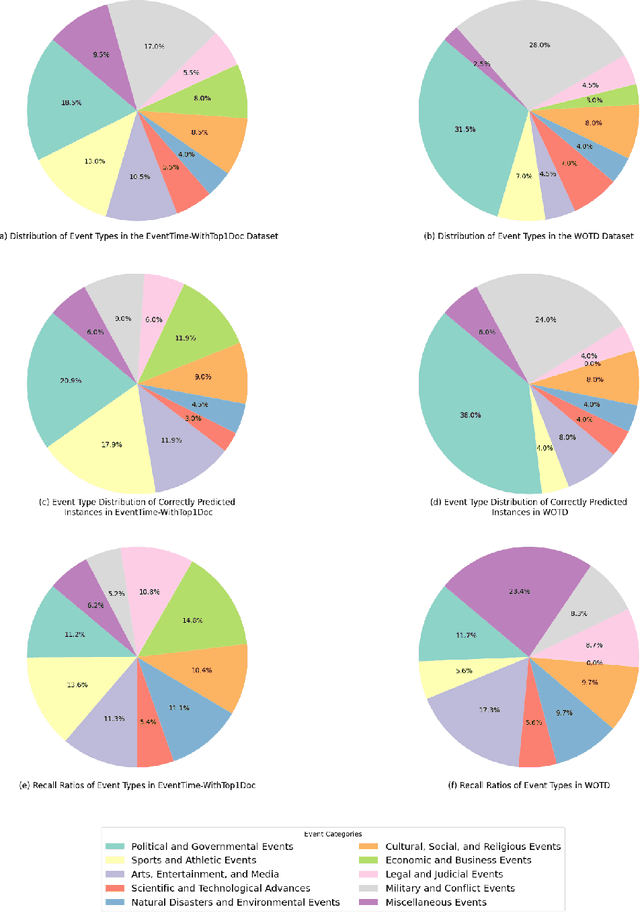
In the evolving field of Natural Language Processing, understanding the temporal context of text is increasingly crucial. This study investigates methods to incorporate temporal information during pre-training, aiming to achieve effective time-aware language representation for improved performance on time-related tasks. In contrast to common pre-trained models like BERT, which rely on synchronic document collections such as BookCorpus and Wikipedia, our research introduces BiTimeBERT 2.0, a novel language model pre-trained on a temporal news article collection. BiTimeBERT 2.0 utilizes this temporal news collection, focusing on three innovative pre-training objectives: Time-Aware Masked Language Modeling (TAMLM), Document Dating (DD), and Time-Sensitive Entity Replacement (TSER). Each objective targets a unique aspect of temporal information. TAMLM is designed to enhance the understanding of temporal contexts and relations, DD integrates document timestamps as chronological markers, and TSER focuses on the temporal dynamics of "Person" entities, recognizing their inherent temporal significance. The experimental results consistently demonstrate that BiTimeBERT 2.0 outperforms models like BERT and other existing pre-trained models, achieving substantial gains across a variety of downstream NLP tasks and applications where time plays a pivotal role.
Reward-Punishment Reinforcement Learning with Maximum Entropy
May 20, 2024



We introduce the ``soft Deep MaxPain'' (softDMP) algorithm, which integrates the optimization of long-term policy entropy into reward-punishment reinforcement learning objectives. Our motivation is to facilitate a smoother variation of operators utilized in the updating of action values beyond traditional ``max'' and ``min'' operators, where the goal is enhancing sample efficiency and robustness. We also address two unresolved issues from the previous Deep MaxPain method. Firstly, we investigate how the negated (``flipped'') pain-seeking sub-policy, derived from the punishment action value, collaborates with the ``min'' operator to effectively learn the punishment module and how softDMP's smooth learning operator provides insights into the ``flipping'' trick. Secondly, we tackle the challenge of data collection for learning the punishment module to mitigate inconsistencies arising from the involvement of the ``flipped'' sub-policy (pain-avoidance sub-policy) in the unified behavior policy. We empirically explore the first issue in two discrete Markov Decision Process (MDP) environments, elucidating the crucial advancements of the DMP approach and the necessity for soft treatments on the hard operators. For the second issue, we propose a probabilistic classifier based on the ratio of the pain-seeking sub-policy to the sum of the pain-seeking and goal-reaching sub-policies. This classifier assigns roll-outs to separate replay buffers for updating reward and punishment action-value functions, respectively. Our framework demonstrates superior performance in Turtlebot 3's maze navigation tasks under the ROS Gazebo simulation.
A Logical Pattern Memory Pre-trained Model for Entailment Tree Generation
Mar 11, 2024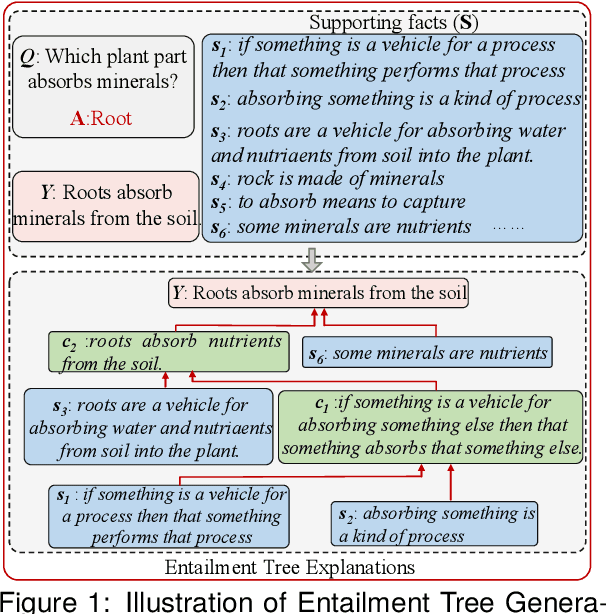

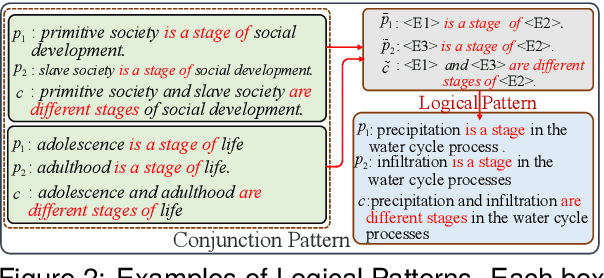
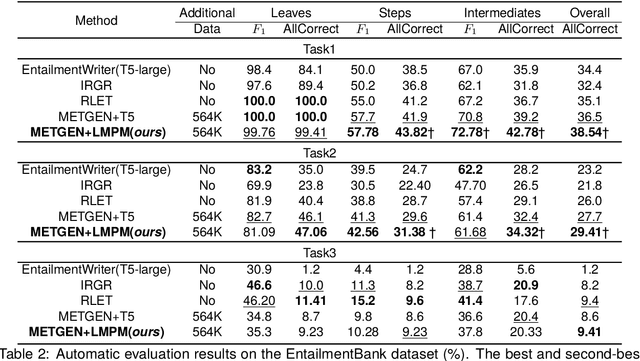
Generating coherent and credible explanations remains a significant challenge in the field of AI. In recent years, researchers have delved into the utilization of entailment trees to depict explanations, which exhibit a reasoning process of how a hypothesis is deduced from the supporting facts. However, existing models often overlook the importance of generating intermediate conclusions with logical consistency from the given facts, leading to inaccurate conclusions and undermining the overall credibility of entailment trees. To address this limitation, we propose the logical pattern memory pre-trained model (LMPM). LMPM incorporates an external memory structure to learn and store the latent representations of logical patterns, which aids in generating logically consistent conclusions. Furthermore, to mitigate the influence of logically irrelevant domain knowledge in the Wikipedia-based data, we introduce an entity abstraction approach to construct the dataset for pre-training LMPM. The experimental results highlight the effectiveness of our approach in improving the quality of entailment tree generation. By leveraging logical entailment patterns, our model produces more coherent and reasonable conclusions that closely align with the underlying premises. Code and Data are released at https://github.com/YuanLi95/T5-LMPM
Controllable Preference Optimization: Toward Controllable Multi-Objective Alignment
Feb 29, 2024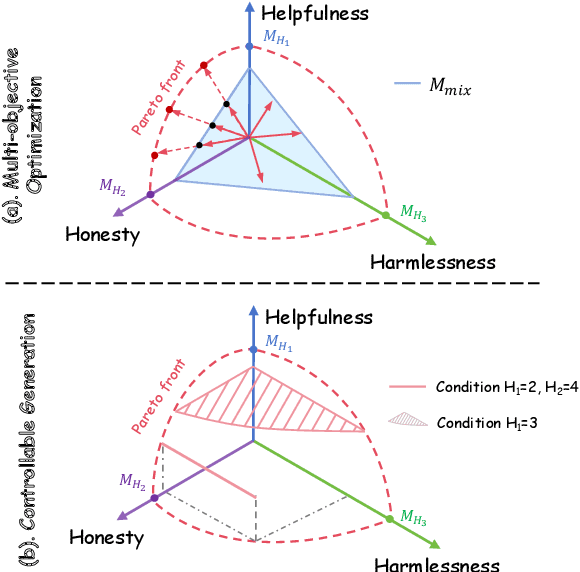
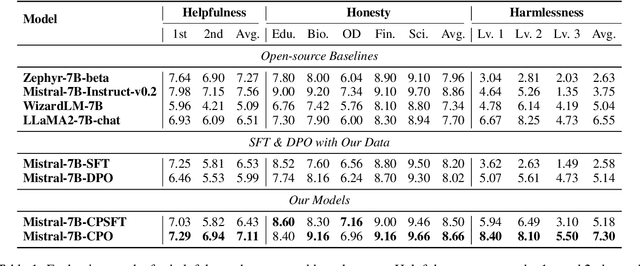
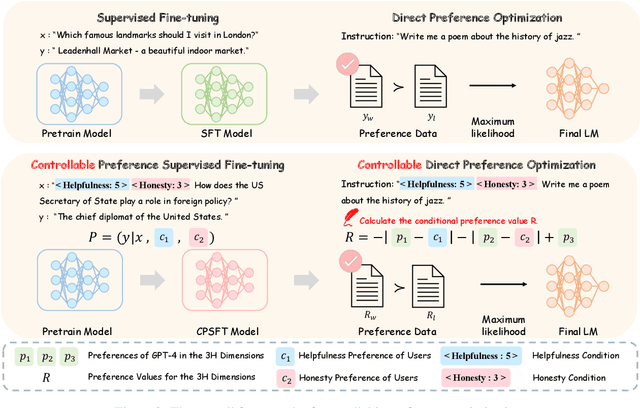

Alignment in artificial intelligence pursues the consistency between model responses and human preferences as well as values. In practice, the multifaceted nature of human preferences inadvertently introduces what is known as the "alignment tax" -a compromise where enhancements in alignment within one objective (e.g.,harmlessness) can diminish performance in others (e.g.,helpfulness). However, existing alignment techniques are mostly unidirectional, leading to suboptimal trade-offs and poor flexibility over various objectives. To navigate this challenge, we argue the prominence of grounding LLMs with evident preferences. We introduce controllable preference optimization (CPO), which explicitly specifies preference scores for different objectives, thereby guiding the model to generate responses that meet the requirements. Our experimental analysis reveals that the aligned models can provide responses that match various preferences among the "3H" (helpfulness, honesty, harmlessness) desiderata. Furthermore, by introducing diverse data and alignment goals, we surpass baseline methods in aligning with single objectives, hence mitigating the impact of the alignment tax and achieving Pareto improvements in multi-objective alignment.
Domain-adaptive and Subgroup-specific Cascaded Temperature Regression for Out-of-distribution Calibration
Feb 14, 2024Although deep neural networks yield high classification accuracy given sufficient training data, their predictions are typically overconfident or under-confident, i.e., the prediction confidences cannot truly reflect the accuracy. Post-hoc calibration tackles this problem by calibrating the prediction confidences without re-training the classification model. However, current approaches assume congruence between test and validation data distributions, limiting their applicability to out-of-distribution scenarios. To this end, we propose a novel meta-set-based cascaded temperature regression method for post-hoc calibration. Our method tailors fine-grained scaling functions to distinct test sets by simulating various domain shifts through data augmentation on the validation set. We partition each meta-set into subgroups based on predicted category and confidence level, capturing diverse uncertainties. A regression network is then trained to derive category-specific and confidence-level-specific scaling, achieving calibration across meta-sets. Extensive experimental results on MNIST, CIFAR-10, and TinyImageNet demonstrate the effectiveness of the proposed method.