 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsensus Group Relative Policy Optimization for Text Generation
Feb 03, 2026Many strong decoding methods for text generation follow a sample-and-rerank paradigm: they draw multiple candidates, score each under a utility (reward) function using consensus across samples, and return the best one. Although effective, these methods incur high computational costs during inference due to repeated sampling and scoring. Prior attempts to amortize inference-time computation typically rely on gold references, teacher labels, or curated preference data, increasing dataset construction effort and the demand for high-fidelity reward models. We propose Consensus Group Relative Policy Optimization (C-GRPO), which distills Minimum Bayes Risk (MBR) decoding into training by formulating the consensus utility as a group-relative objective within GRPO. C-GRPO requires only a utility function and policy samples, without gold references or explicit preference labels. Under ideal conditions, we show that the objective function of C-GRPO is directionally aligned with the gradient of the expected-utility objective underlying MBR decoding, leading to a convergence guarantee. Experiments on machine translation (WMT 2024) and text summarization (XSum) demonstrate that C-GRPO successfully achieves performance comparable to MBR decoding without the associated inference-time overhead, while outperforming reference-free baseline methods.
MO-GRPO: Mitigating Reward Hacking of Group Relative Policy Optimization on Multi-Objective Problems
Sep 26, 2025Group Relative Policy Optimization (GRPO) has been shown to be an effective algorithm when an accurate reward model is available. However, such a highly reliable reward model is not available in many real-world tasks. In this paper, we particularly focus on multi-objective settings, in which we identify that GRPO is vulnerable to reward hacking, optimizing only one of the objectives at the cost of the others. To address this issue, we propose MO-GRPO, an extension of GRPO with a simple normalization method to reweight the reward functions automatically according to the variances of their values. We first show analytically that MO-GRPO ensures that all reward functions contribute evenly to the loss function while preserving the order of preferences, eliminating the need for manual tuning of the reward functions' scales. Then, we evaluate MO-GRPO experimentally in four domains: (i) the multi-armed bandits problem, (ii) simulated control task (Mo-Gymnasium), (iii) machine translation tasks on the WMT benchmark (En-Ja, En-Zh), and (iv) instruction following task. MO-GRPO achieves stable learning by evenly distributing correlations among the components of rewards, outperforming GRPO, showing MO-GRPO to be a promising algorithm for multi-objective reinforcement learning problems.
Theoretical Guarantees for Minimum Bayes Risk Decoding
Feb 18, 2025Minimum Bayes Risk (MBR) decoding optimizes output selection by maximizing the expected utility value of an underlying human distribution. While prior work has shown the effectiveness of MBR decoding through empirical evaluation, few studies have analytically investigated why the method is effective. As a result of our analysis, we show that, given the size $n$ of the reference hypothesis set used in computation, MBR decoding approaches the optimal solution with high probability at a rate of $O\left(n^{-\frac{1}{2}}\right)$, under certain assumptions, even though the language space $Y$ is significantly larger $Y\gg n$. This result helps to theoretically explain the strong performance observed in several prior empirical studies on MBR decoding. In addition, we provide the performance gap for maximum-a-posteriori (MAP) decoding and compare it to MBR decoding. The result of this paper indicates that MBR decoding tends to converge to the optimal solution faster than MAP decoding in several cases.
Evaluation of Best-of-N Sampling Strategies for Language Model Alignment
Feb 18, 2025



Best-of-N (BoN) sampling with a reward model has been shown to be an effective strategy for aligning Large Language Models (LLMs) with human preferences at the time of decoding. BoN sampling is susceptible to a problem known as reward hacking. Since the reward model is an imperfect proxy for the true objective, an excessive focus on optimizing its value can lead to a compromise of its performance on the true objective. Previous work proposes Regularized BoN sampling (RBoN), a BoN sampling with regularization to the objective, and shows that it outperforms BoN sampling so that it mitigates reward hacking and empirically (Jinnai et al., 2024). However, Jinnai et al. (2024) introduce RBoN based on a heuristic and they lack the analysis of why such regularization strategy improves the performance of BoN sampling. The aim of this study is to analyze the effect of BoN sampling on regularization strategies. Using the regularization strategies corresponds to robust optimization, which maximizes the worst case over a set of possible perturbations in the proxy reward. Although the theoretical guarantees are not directly applicable to RBoN, RBoN corresponds to a practical implementation. This paper proposes an extension of the RBoN framework, called Stochastic RBoN sampling (SRBoN), which is a theoretically guaranteed approach to worst-case RBoN in proxy reward. We then perform an empirical evaluation using the AlpacaFarm and Anthropic's hh-rlhf datasets to evaluate which factors of the regularization strategies contribute to the improvement of the true proxy reward. In addition, we also propose another simple RBoN method, the Sentence Length Regularized BoN, which has a better performance in the experiment as compared to the previous methods.
Unsupervised Neural Motion Retargeting for Humanoid Teleoperation
Jun 02, 2024



This study proposes an approach to human-to-humanoid teleoperation using GAN-based online motion retargeting, which obviates the need for the construction of pairwise datasets to identify the relationship between the human and the humanoid kinematics. Consequently, it can be anticipated that our proposed teleoperation system will reduce the complexity and setup requirements typically associated with humanoid controllers, thereby facilitating the development of more accessible and intuitive teleoperation systems for users without robotics knowledge. The experiments demonstrated the efficacy of the proposed method in retargeting a range of upper-body human motions to humanoid, including a body jab motion and a basketball shoot motion. Moreover, the human-in-the-loop teleoperation performance was evaluated by measuring the end-effector position errors between the human and the retargeted humanoid motions. The results demonstrated that the error was comparable to those of conventional motion retargeting methods that require pairwise motion datasets. Finally, a box pick-and-place task was conducted to demonstrate the usability of the developed humanoid teleoperation system.
Reward-Punishment Reinforcement Learning with Maximum Entropy
May 20, 2024



We introduce the ``soft Deep MaxPain'' (softDMP) algorithm, which integrates the optimization of long-term policy entropy into reward-punishment reinforcement learning objectives. Our motivation is to facilitate a smoother variation of operators utilized in the updating of action values beyond traditional ``max'' and ``min'' operators, where the goal is enhancing sample efficiency and robustness. We also address two unresolved issues from the previous Deep MaxPain method. Firstly, we investigate how the negated (``flipped'') pain-seeking sub-policy, derived from the punishment action value, collaborates with the ``min'' operator to effectively learn the punishment module and how softDMP's smooth learning operator provides insights into the ``flipping'' trick. Secondly, we tackle the challenge of data collection for learning the punishment module to mitigate inconsistencies arising from the involvement of the ``flipped'' sub-policy (pain-avoidance sub-policy) in the unified behavior policy. We empirically explore the first issue in two discrete Markov Decision Process (MDP) environments, elucidating the crucial advancements of the DMP approach and the necessity for soft treatments on the hard operators. For the second issue, we propose a probabilistic classifier based on the ratio of the pain-seeking sub-policy to the sum of the pain-seeking and goal-reaching sub-policies. This classifier assigns roll-outs to separate replay buffers for updating reward and punishment action-value functions, respectively. Our framework demonstrates superior performance in Turtlebot 3's maze navigation tasks under the ROS Gazebo simulation.
Randomized-to-Canonical Model Predictive Control for Real-world Visual Robotic Manipulation
Jul 05, 2022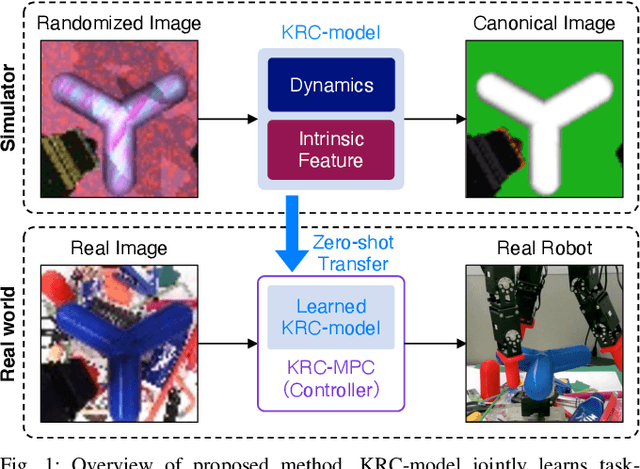
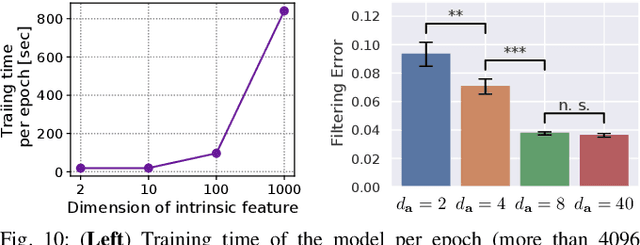
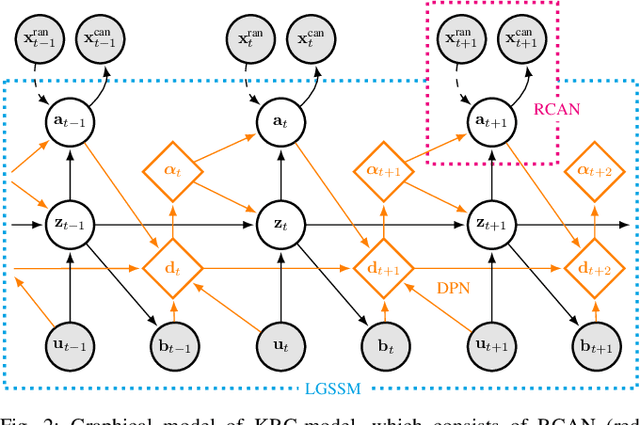
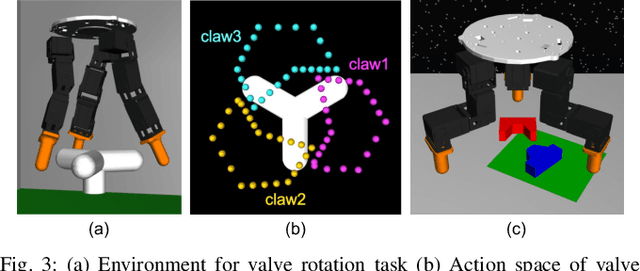
Many works have recently explored Sim-to-real transferable visual model predictive control (MPC). However, such works are limited to one-shot transfer, where real-world data must be collected once to perform the sim-to-real transfer, which remains a significant human effort in transferring the models learned in simulations to new domains in the real world. To alleviate this problem, we first propose a novel model-learning framework called Kalman Randomized-to-Canonical Model (KRC-model). This framework is capable of extracting task-relevant intrinsic features and their dynamics from randomized images. We then propose Kalman Randomized-to-Canonical Model Predictive Control (KRC-MPC) as a zero-shot sim-to-real transferable visual MPC using KRC-model. The effectiveness of our method is evaluated through a valve rotation task by a robot hand in both simulation and the real world, and a block mating task in simulation. The experimental results show that KRC-MPC can be applied to various real domains and tasks in a zero-shot manner.
Model-Based Imitation Learning Using Entropy Regularization of Model and Policy
Jun 21, 2022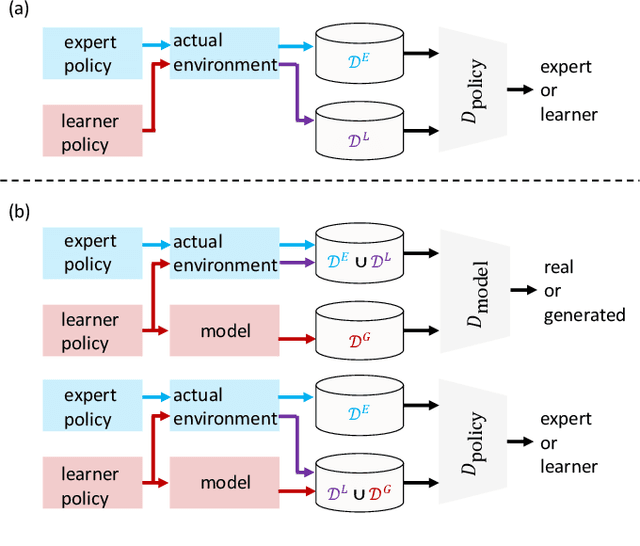
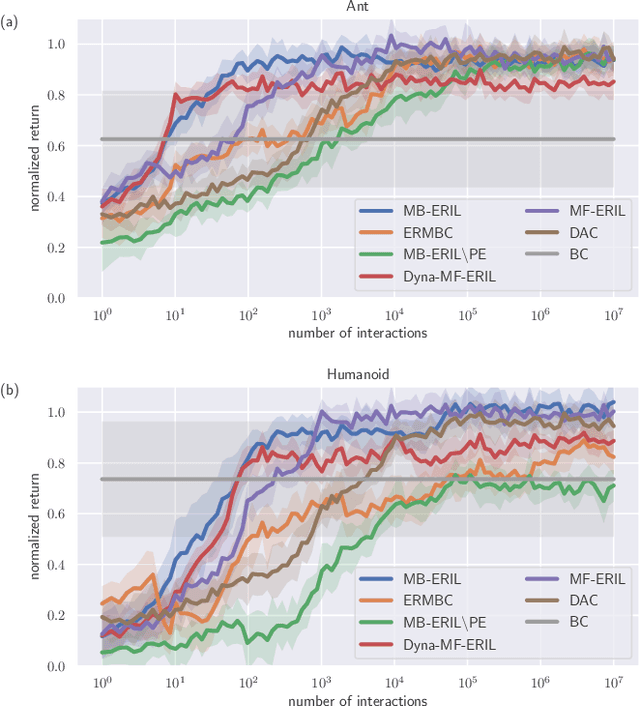

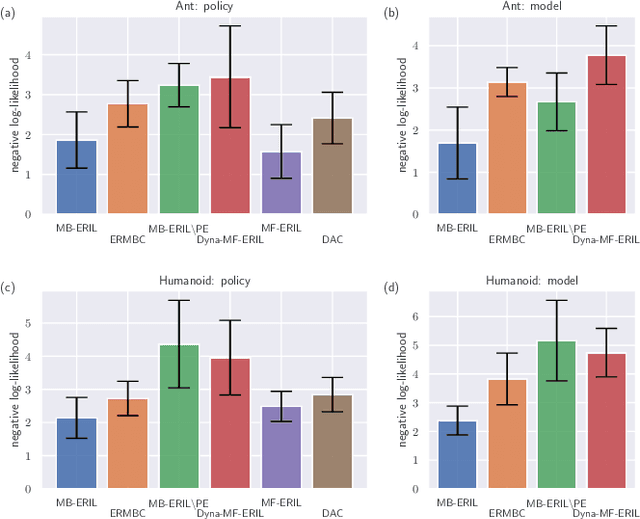
Approaches based on generative adversarial networks for imitation learning are promising because they are sample efficient in terms of expert demonstrations. However, training a generator requires many interactions with the actual environment because model-free reinforcement learning is adopted to update a policy. To improve the sample efficiency using model-based reinforcement learning, we propose model-based Entropy-Regularized Imitation Learning (MB-ERIL) under the entropy-regularized Markov decision process to reduce the number of interactions with the actual environment. MB-ERIL uses two discriminators. A policy discriminator distinguishes the actions generated by a robot from expert ones, and a model discriminator distinguishes the counterfactual state transitions generated by the model from the actual ones. We derive the structured discriminators so that the learning of the policy and the model is efficient. Computer simulations and real robot experiments show that MB-ERIL achieves a competitive performance and significantly improves the sample efficiency compared to baseline methods.
$q$-Munchausen Reinforcement Learning
May 16, 2022

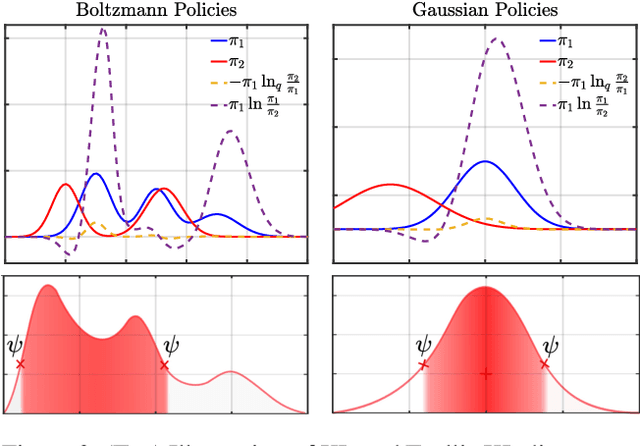
The recently successful Munchausen Reinforcement Learning (M-RL) features implicit Kullback-Leibler (KL) regularization by augmenting the reward function with logarithm of the current stochastic policy. Though significant improvement has been shown with the Boltzmann softmax policy, when the Tsallis sparsemax policy is considered, the augmentation leads to a flat learning curve for almost every problem considered. We show that it is due to the mismatch between the conventional logarithm and the non-logarithmic (generalized) nature of Tsallis entropy. Drawing inspiration from the Tsallis statistics literature, we propose to correct the mismatch of M-RL with the help of $q$-logarithm/exponential functions. The proposed formulation leads to implicit Tsallis KL regularization under the maximum Tsallis entropy framework. We show such formulation of M-RL again achieves superior performance on benchmark problems and sheds light on more general M-RL with various entropic indices $q$.
Enforcing KL Regularization in General Tsallis Entropy Reinforcement Learning via Advantage Learning
May 16, 2022

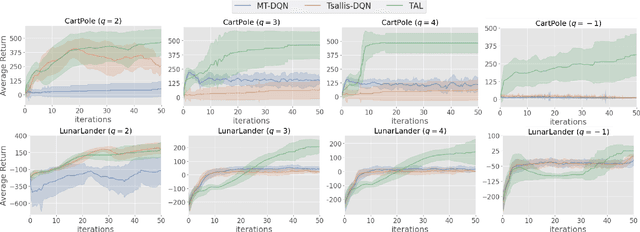

Maximum Tsallis entropy (MTE) framework in reinforcement learning has gained popularity recently by virtue of its flexible modeling choices including the widely used Shannon entropy and sparse entropy. However, non-Shannon entropies suffer from approximation error and subsequent underperformance either due to its sensitivity or the lack of closed-form policy expression. To improve the tradeoff between flexibility and empirical performance, we propose to strengthen their error-robustness by enforcing implicit Kullback-Leibler (KL) regularization in MTE motivated by Munchausen DQN (MDQN). We do so by drawing connection between MDQN and advantage learning, by which MDQN is shown to fail on generalizing to the MTE framework. The proposed method Tsallis Advantage Learning (TAL) is verified on extensive experiments to not only significantly improve upon Tsallis-DQN for various non-closed-form Tsallis entropies, but also exhibits comparable performance to state-of-the-art maximum Shannon entropy algorithms.