 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-Conditioned Terminal Value Estimation for Real-time and Multi-task Model Predictive Control
Oct 07, 2024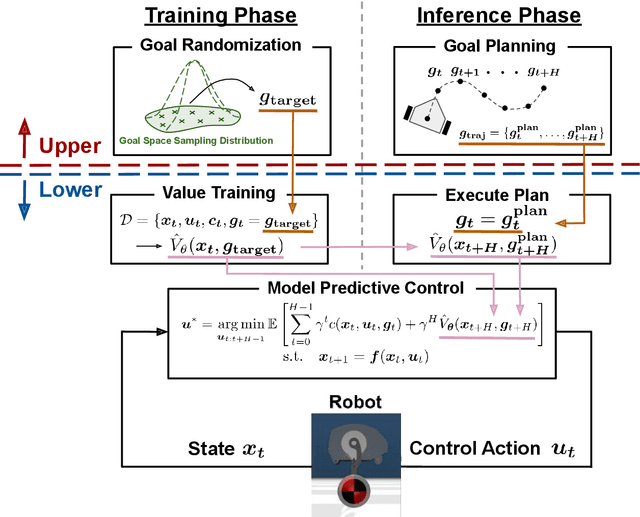
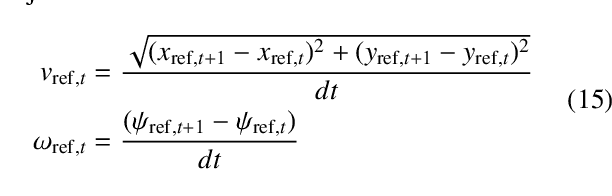
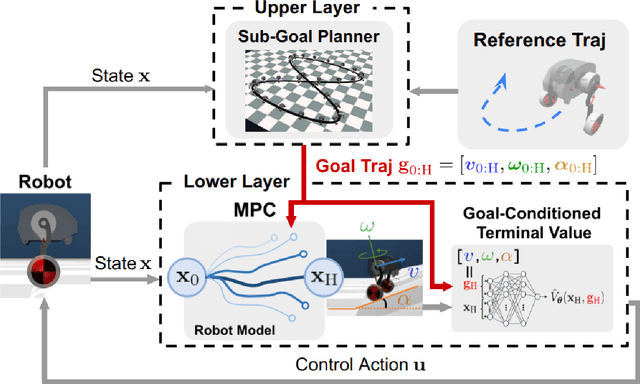
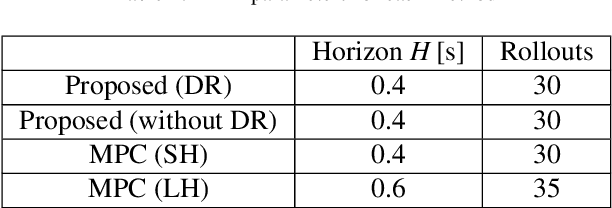
While MPC enables nonlinear feedback control by solving an optimal control problem at each timestep, the computational burden tends to be significantly large, making it difficult to optimize a policy within the control period. To address this issue, one possible approach is to utilize terminal value learning to reduce computational costs. However, the learned value cannot be used for other tasks in situations where the task dynamically changes in the original MPC setup. In this study, we develop an MPC framework with goal-conditioned terminal value learning to achieve multitask policy optimization while reducing computational time. Furthermore, by using a hierarchical control structure that allows the upper-level trajectory planner to output appropriate goal-conditioned trajectories, we demonstrate that a robot model is able to generate diverse motions. We evaluate the proposed method on a bipedal inverted pendulum robot model and confirm that combining goal-conditioned terminal value learning with an upper-level trajectory planner enables real-time control; thus, the robot successfully tracks a target trajectory on sloped terrain.
Unsupervised Neural Motion Retargeting for Humanoid Teleoperation
Jun 02, 2024



This study proposes an approach to human-to-humanoid teleoperation using GAN-based online motion retargeting, which obviates the need for the construction of pairwise datasets to identify the relationship between the human and the humanoid kinematics. Consequently, it can be anticipated that our proposed teleoperation system will reduce the complexity and setup requirements typically associated with humanoid controllers, thereby facilitating the development of more accessible and intuitive teleoperation systems for users without robotics knowledge. The experiments demonstrated the efficacy of the proposed method in retargeting a range of upper-body human motions to humanoid, including a body jab motion and a basketball shoot motion. Moreover, the human-in-the-loop teleoperation performance was evaluated by measuring the end-effector position errors between the human and the retargeted humanoid motions. The results demonstrated that the error was comparable to those of conventional motion retargeting methods that require pairwise motion datasets. Finally, a box pick-and-place task was conducted to demonstrate the usability of the developed humanoid teleoperation system.
Variational Autoencoder with Implicit Optimal Priors
Sep 14, 2018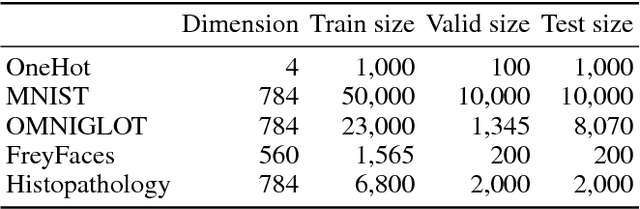
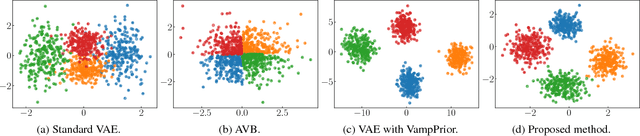
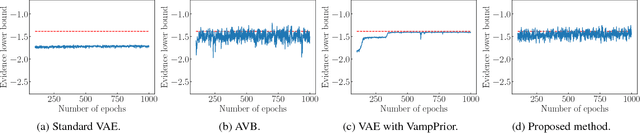

The variational autoencoder (VAE) is a powerful generative model that can estimate the probability of a data point by using latent variables. In the VAE, the posterior of the latent variable given the data point is regularized by the prior of the latent variable using Kullback Leibler (KL) divergence. Although the standard Gaussian distribution is usually used for the prior, this simple prior incurs over-regularization. As a sophisticated prior, the aggregated posterior has been introduced, which is the expectation of the posterior over the data distribution. This prior is optimal for the VAE in terms of maximizing the training objective function. However, KL divergence with the aggregated posterior cannot be calculated in a closed form, which prevents us from using this optimal prior. With the proposed method, we introduce the density ratio trick to estimate this KL divergence without modeling the aggregated posterior explicitly. Since the density ratio trick does not work well in high dimensions, we rewrite this KL divergence that contains the high-dimensional density ratio into the sum of the analytically calculable term and the low-dimensional density ratio term, to which the density ratio trick is applied. Experiments on various datasets show that the VAE with this implicit optimal prior achieves high density estimation performance.