 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-Conditioned Terminal Value Estimation for Real-time and Multi-task Model Predictive Control
Oct 07, 2024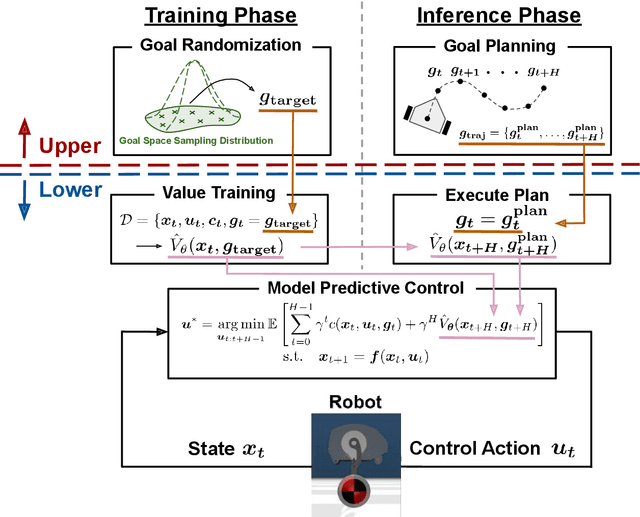
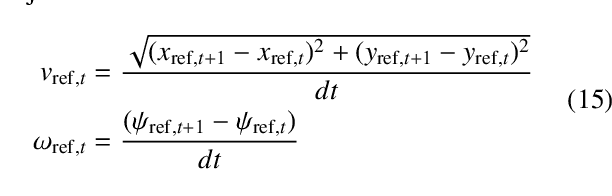
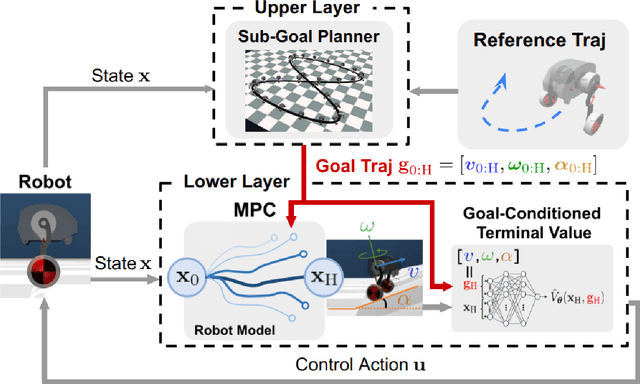
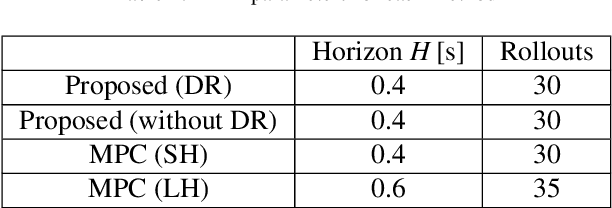
While MPC enables nonlinear feedback control by solving an optimal control problem at each timestep, the computational burden tends to be significantly large, making it difficult to optimize a policy within the control period. To address this issue, one possible approach is to utilize terminal value learning to reduce computational costs. However, the learned value cannot be used for other tasks in situations where the task dynamically changes in the original MPC setup. In this study, we develop an MPC framework with goal-conditioned terminal value learning to achieve multitask policy optimization while reducing computational time. Furthermore, by using a hierarchical control structure that allows the upper-level trajectory planner to output appropriate goal-conditioned trajectories, we demonstrate that a robot model is able to generate diverse motions. We evaluate the proposed method on a bipedal inverted pendulum robot model and confirm that combining goal-conditioned terminal value learning with an upper-level trajectory planner enables real-time control; thus, the robot successfully tracks a target trajectory on sloped terrain.
Phase-Amplitude Reduction-Based Imitation Learning
Jun 06, 2024In this study, we propose the use of the phase-amplitude reduction method to construct an imitation learning framework. Imitating human movement trajectories is recognized as a promising strategy for generating a range of human-like robot movements. Unlike previous dynamical system-based imitation learning approaches, our proposed method allows the robot not only to imitate a limit cycle trajectory but also to replicate the transient movement from the initial or disturbed state to the limit cycle. Consequently, our method offers a safer imitation learning approach that avoids generating unpredictable motions immediately after disturbances or from a specified initial state. We first validated our proposed method by reconstructing a simple limit-cycle attractor. We then compared the proposed approach with a conventional method on a lemniscate trajectory tracking task with a simulated robot arm. Our findings confirm that our proposed method can more accurately generate transient movements to converge on a target periodic attractor compared to the previous standard approach. Subsequently, we applied our method to a real robot arm to imitate periodic human movements.
A Policy Adaptation Method for Implicit Multitask Reinforcement Learning Problems
Aug 31, 2023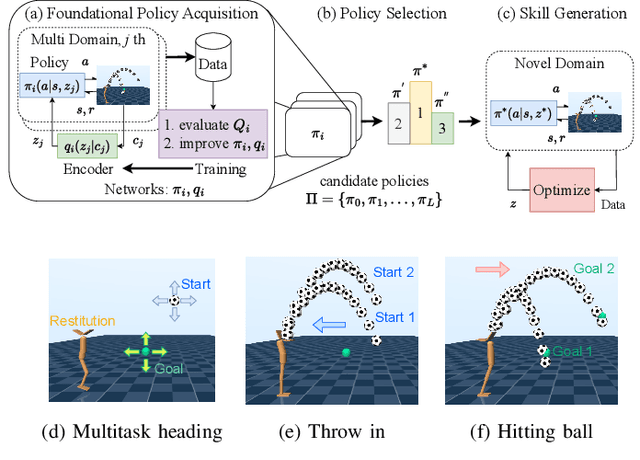
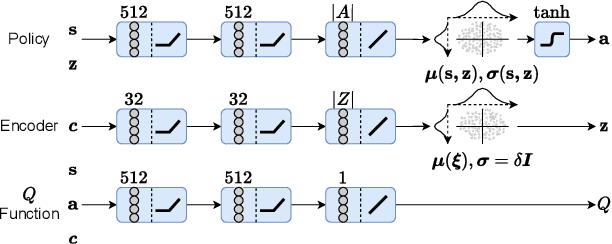
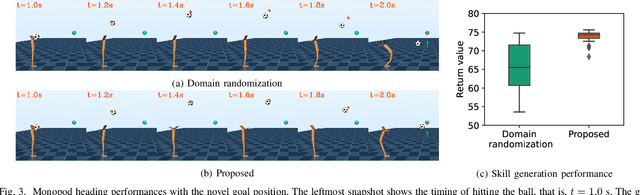
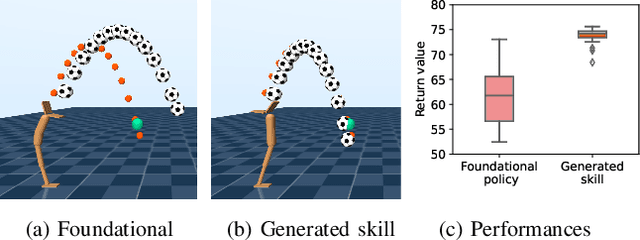
In dynamic motion generation tasks, including contact and collisions, small changes in policy parameters can lead to extremely different returns. For example, in soccer, the ball can fly in completely different directions with a similar heading motion by slightly changing the hitting position or the force applied to the ball or when the friction of the ball varies. However, it is difficult to imagine that completely different skills are needed for heading a ball in different directions. In this study, we proposed a multitask reinforcement learning algorithm for adapting a policy to implicit changes in goals or environments in a single motion category with different reward functions or physical parameters of the environment. We evaluated the proposed method on the ball heading task using a monopod robot model. The results showed that the proposed method can adapt to implicit changes in the goal positions or the coefficients of restitution of the ball, whereas the standard domain randomization approach cannot cope with different task settings.