 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-Conditioned Terminal Value Estimation for Real-time and Multi-task Model Predictive Control
Paper and Code
Oct 07, 2024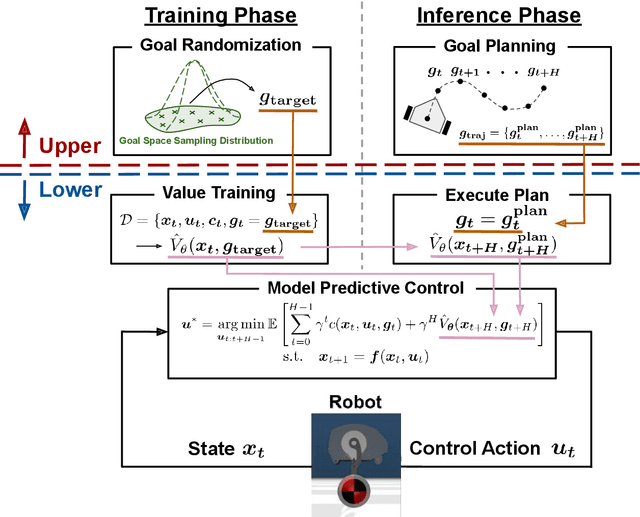
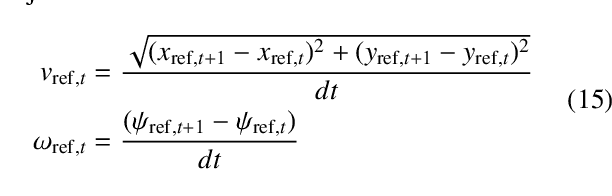
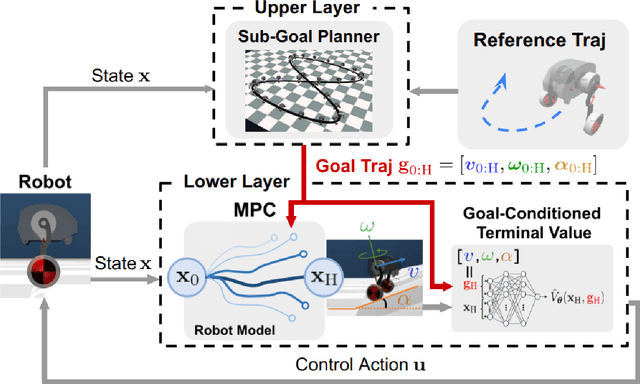
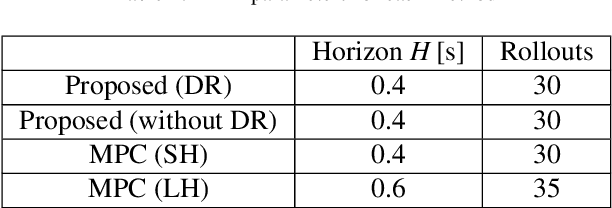
While MPC enables nonlinear feedback control by solving an optimal control problem at each timestep, the computational burden tends to be significantly large, making it difficult to optimize a policy within the control period. To address this issue, one possible approach is to utilize terminal value learning to reduce computational costs. However, the learned value cannot be used for other tasks in situations where the task dynamically changes in the original MPC setup. In this study, we develop an MPC framework with goal-conditioned terminal value learning to achieve multitask policy optimization while reducing computational time. Furthermore, by using a hierarchical control structure that allows the upper-level trajectory planner to output appropriate goal-conditioned trajectories, we demonstrate that a robot model is able to generate diverse motions. We evaluate the proposed method on a bipedal inverted pendulum robot model and confirm that combining goal-conditioned terminal value learning with an upper-level trajectory planner enables real-time control; thus, the robot successfully tracks a target trajectory on sloped terrain.