 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActuator Reality Shaping for Zero-Shot Sim-to-Real Robot Learning
Jul 02, 2026Sim-to-real transfer in robot learning is often limited by discrepancies between the ideal actuator dynamics assumed during policy training and the nonlinear, hardware-dependent behavior of physical motors. While conventional approaches attempt to bridge this gap by increasing simulator fidelity through system identification, domain randomization, or learned actuator models, we introduce an alternative paradigm: actuator reality shaping. Instead of modifying the simulator to match the real world, our method shapes the closed-loop behavior of physical actuators to match the idealized second-order reference dynamics used in simulation. By equipping each joint with a two-degree-of-freedom feedforward--feedback controller, we decouple reference-response shaping from robust stabilization, thereby providing a standardized actuator interface for reinforcement learning policies. As a result, policies trained only with the prescribed reference model can be deployed zero-shot on real hardware without task-level fine-tuning or learned actuator models. We validate the approach on a single-joint high-gear-ratio servo under external loads and a 7-DOF robotic arm reaching task, where actuator reality shaping substantially reduces sim-to-real tracking error and improves zero-shot task performance compared with standard servo-control and representative real-to-sim-to-real baselines. We further demonstrate zero-shot transfer on a wheeled-legged robot driving over a slope and a humanoid robot walking, suggesting that actuator reality shaping can serve as a reusable interface for robot learning across diverse hardware platforms.
DecompGrind: A Decomposition Framework for Robotic Grinding via Cutting-Surface Planning and Contact-Force Adaptation
Mar 24, 2026Robotic grinding is widely used for shaping workpieces in manufacturing, but it remains difficult to automate this process efficiently. In particular, efficiently grinding workpieces of different shapes and material hardness is challenging because removal resistance varies with local contact conditions. Moreover, it is difficult to achieve accurate estimation of removal resistance and analytical modeling of shape transition, and learning-based approaches often require large amounts of training data to cover diverse processing conditions. To address these challenges, we decompose robotic grinding into two components: removal-shape planning and contact-force adaptation. Based on this formulation, we propose DecompGrind, a framework that combines Global Cutting-Surface Planning (GCSP) and Local Contact-Force Adaptation (LCFA). GCSP determines removal shapes through geometric analysis of the current and target shapes without learning, while LCFA learns a contact-force adaptation policy using bilateral control-based imitation learning during the grinding of each removal shape. This decomposition restricts learning to local contact-force adaptation, allowing the policy to be learned from a small number of demonstrations, while handling global shape transition geometrically. Experiments using a robotic grinding system and 3D-printed workpieces demonstrate efficient robotic grinding of workpieces having different shapes and material hardness while maintaining safe levels of contact force.
Cutting Sequence Diffuser: Sim-to-Real Transferable Planning for Object Shaping by Grinding
Dec 19, 2024
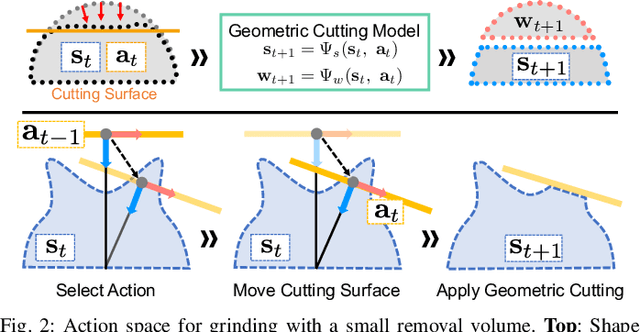
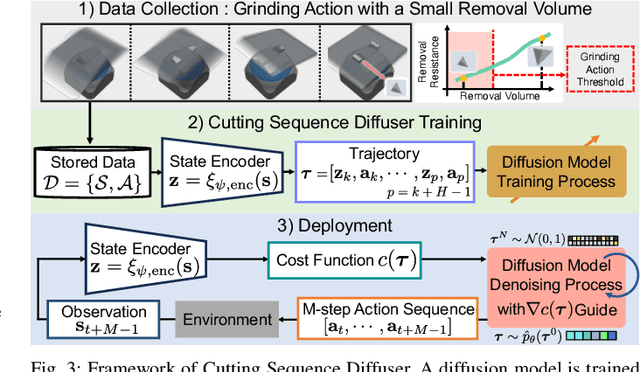
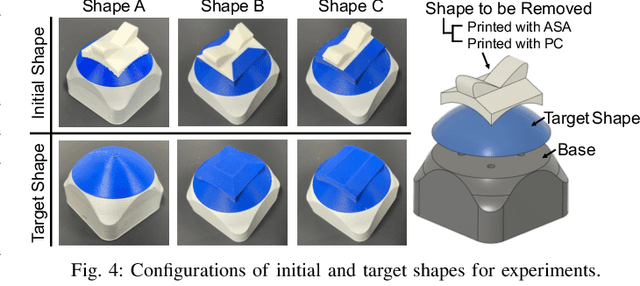
Automating object shaping by grinding with a robot is a crucial industrial process that involves removing material with a rotating grinding belt. This process generates removal resistance depending on such process conditions as material type, removal volume, and robot grinding posture, all of which complicate the analytical modeling of shape transitions. Additionally, a data-driven approach based on real-world data is challenging due to high data collection costs and the irreversible nature of the process. This paper proposes a Cutting Sequence Diffuser (CSD) for object shaping by grinding. The CSD, which only requires simple simulation data for model learning, offers an efficient way to plan long-horizon action sequences transferable to the real world. Our method designs a smooth action space with constrained small removal volumes to suppress the complexity of the shape transitions caused by removal resistance, thus reducing the reality gap in simulations. Moreover, by using a diffusion model to generate long-horizon action sequences, our approach reduces the planning time and allows for grinding the target shape while adhering to the constraints of a small removal volume per step. Through evaluations in both simulation and real robot experiments, we confirmed that our CSD was effective for grinding to different materials and various target shapes in a short time.
Goal-Conditioned Terminal Value Estimation for Real-time and Multi-task Model Predictive Control
Oct 07, 2024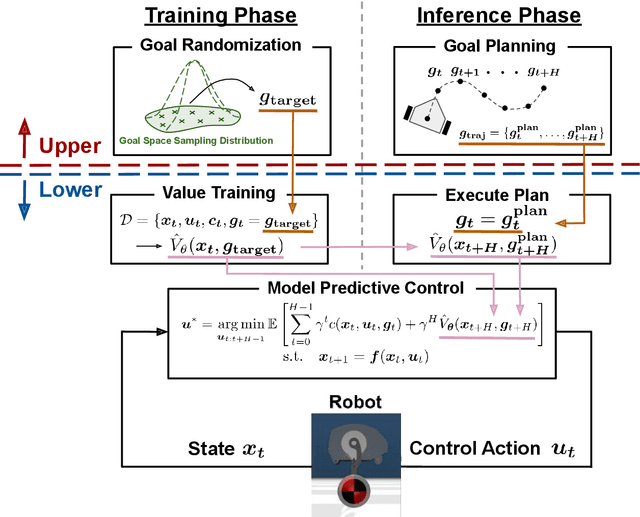
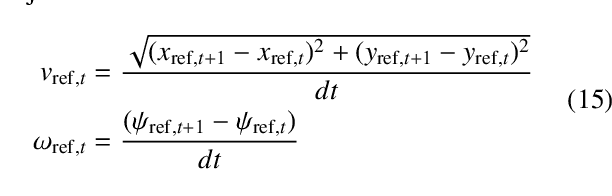
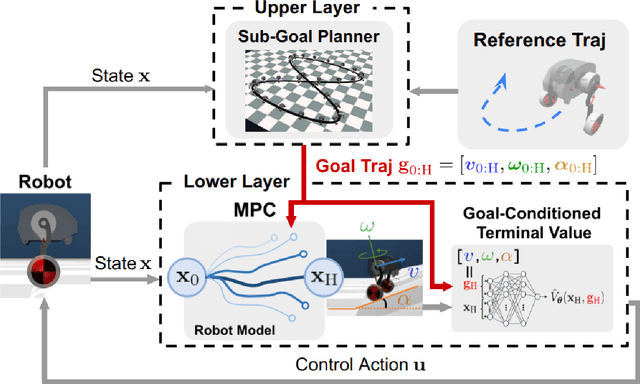
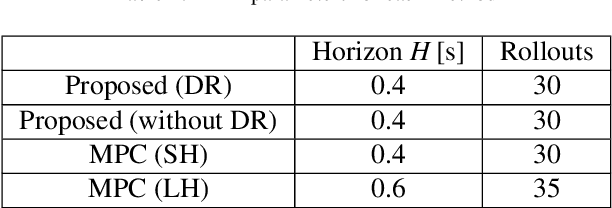
While MPC enables nonlinear feedback control by solving an optimal control problem at each timestep, the computational burden tends to be significantly large, making it difficult to optimize a policy within the control period. To address this issue, one possible approach is to utilize terminal value learning to reduce computational costs. However, the learned value cannot be used for other tasks in situations where the task dynamically changes in the original MPC setup. In this study, we develop an MPC framework with goal-conditioned terminal value learning to achieve multitask policy optimization while reducing computational time. Furthermore, by using a hierarchical control structure that allows the upper-level trajectory planner to output appropriate goal-conditioned trajectories, we demonstrate that a robot model is able to generate diverse motions. We evaluate the proposed method on a bipedal inverted pendulum robot model and confirm that combining goal-conditioned terminal value learning with an upper-level trajectory planner enables real-time control; thus, the robot successfully tracks a target trajectory on sloped terrain.
Hierarchical Learning Framework for Whole-Body Model Predictive Control of a Real Humanoid Robot
Sep 13, 2024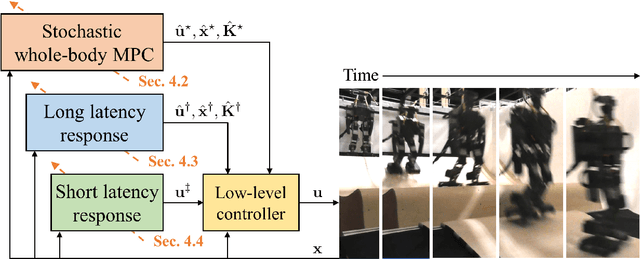
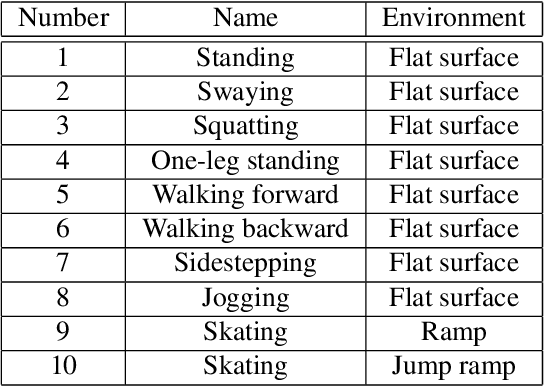
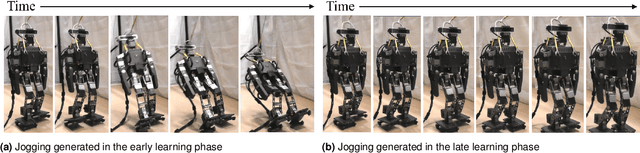

The simulation-to-real gap problem and the high computational burden of whole-body Model Predictive Control (whole-body MPC) continue to present challenges in generating a wide variety of movements using whole-body MPC for real humanoid robots. This paper presents a biologically-inspired hierarchical learning framework as a potential solution to the aforementioned problems. The proposed three-layer hierarchical framework enables the generation of multi-contact, dynamic behaviours even with low-frequency policy updates of whole-body MPC. The upper layer is responsible for learning an accurate dynamics model with the objective of reducing the discrepancy between the analytical model and the real system. This enables the computation of effective control policies using whole-body MPC. Subsequently, the middle and lower layers are tasked with learning additional policies to generate high-frequency control inputs. In order to learn an accurate dynamics model in the upper layer, an augmented model using a deep residual network is trained by model-based reinforcement learning with stochastic whole-body MPC. The proposed framework was evaluated in 10 distinct motion learning scenarios, including jogging on a flat surface and skating on curved surfaces. The results demonstrate that a wide variety of motions can be successfully generated on a real humanoid robot using whole-body MPC through learning with the proposed framework.
Phase-Amplitude Reduction-Based Imitation Learning
Jun 06, 2024In this study, we propose the use of the phase-amplitude reduction method to construct an imitation learning framework. Imitating human movement trajectories is recognized as a promising strategy for generating a range of human-like robot movements. Unlike previous dynamical system-based imitation learning approaches, our proposed method allows the robot not only to imitate a limit cycle trajectory but also to replicate the transient movement from the initial or disturbed state to the limit cycle. Consequently, our method offers a safer imitation learning approach that avoids generating unpredictable motions immediately after disturbances or from a specified initial state. We first validated our proposed method by reconstructing a simple limit-cycle attractor. We then compared the proposed approach with a conventional method on a lemniscate trajectory tracking task with a simulated robot arm. Our findings confirm that our proposed method can more accurately generate transient movements to converge on a target periodic attractor compared to the previous standard approach. Subsequently, we applied our method to a real robot arm to imitate periodic human movements.
Unsupervised Neural Motion Retargeting for Humanoid Teleoperation
Jun 02, 2024



This study proposes an approach to human-to-humanoid teleoperation using GAN-based online motion retargeting, which obviates the need for the construction of pairwise datasets to identify the relationship between the human and the humanoid kinematics. Consequently, it can be anticipated that our proposed teleoperation system will reduce the complexity and setup requirements typically associated with humanoid controllers, thereby facilitating the development of more accessible and intuitive teleoperation systems for users without robotics knowledge. The experiments demonstrated the efficacy of the proposed method in retargeting a range of upper-body human motions to humanoid, including a body jab motion and a basketball shoot motion. Moreover, the human-in-the-loop teleoperation performance was evaluated by measuring the end-effector position errors between the human and the retargeted humanoid motions. The results demonstrated that the error was comparable to those of conventional motion retargeting methods that require pairwise motion datasets. Finally, a box pick-and-place task was conducted to demonstrate the usability of the developed humanoid teleoperation system.
A Policy Adaptation Method for Implicit Multitask Reinforcement Learning Problems
Aug 31, 2023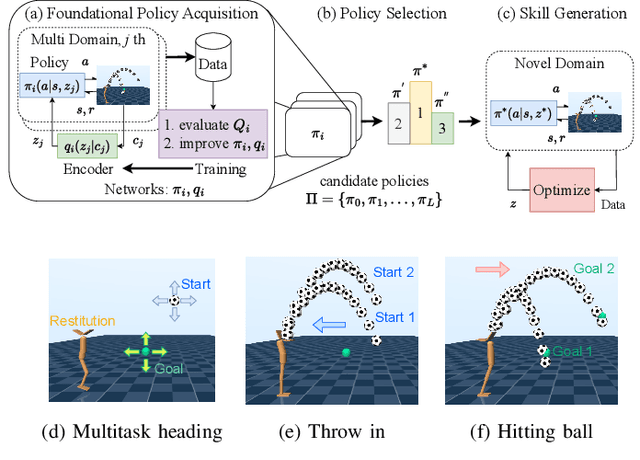
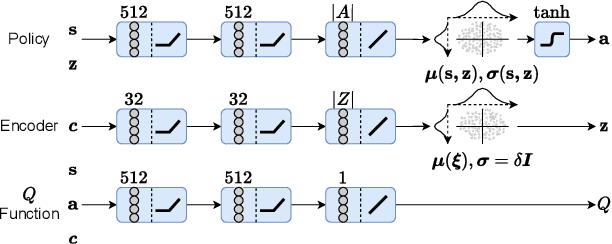
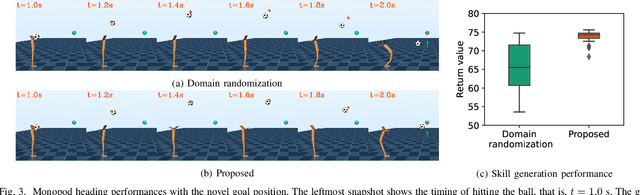
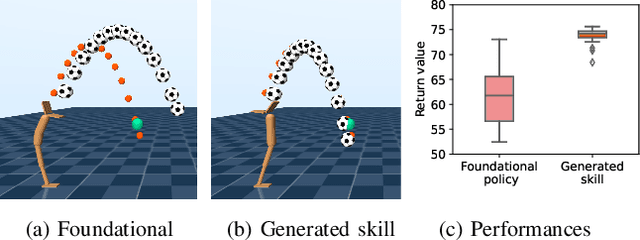
In dynamic motion generation tasks, including contact and collisions, small changes in policy parameters can lead to extremely different returns. For example, in soccer, the ball can fly in completely different directions with a similar heading motion by slightly changing the hitting position or the force applied to the ball or when the friction of the ball varies. However, it is difficult to imagine that completely different skills are needed for heading a ball in different directions. In this study, we proposed a multitask reinforcement learning algorithm for adapting a policy to implicit changes in goals or environments in a single motion category with different reward functions or physical parameters of the environment. We evaluated the proposed method on the ball heading task using a monopod robot model. The results showed that the proposed method can adapt to implicit changes in the goal positions or the coefficients of restitution of the ball, whereas the standard domain randomization approach cannot cope with different task settings.
Learning to Shape by Grinding: Cutting-surface-aware Model-based Reinforcement Learning
Aug 04, 2023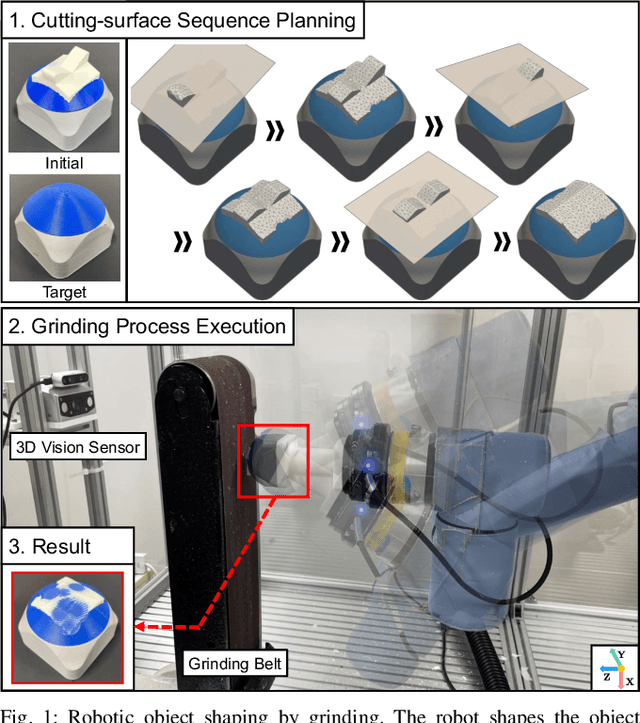
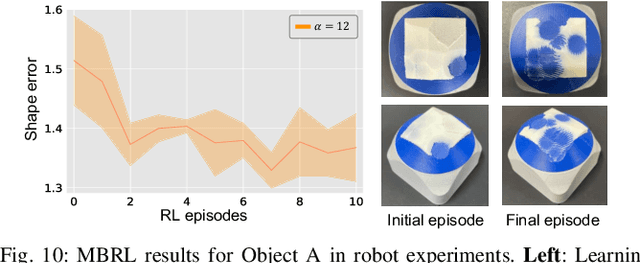
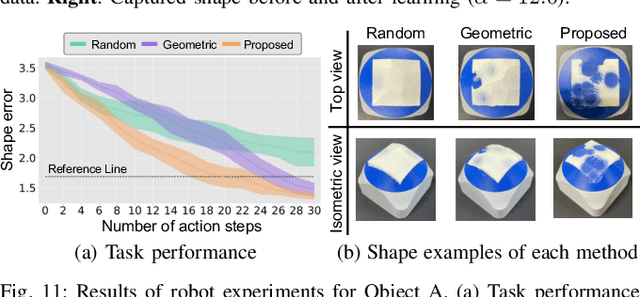
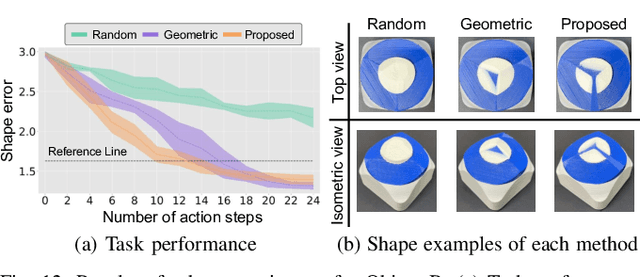
Object shaping by grinding is a crucial industrial process in which a rotating grinding belt removes material. Object-shape transition models are essential to achieving automation by robots; however, learning such a complex model that depends on process conditions is challenging because it requires a significant amount of data, and the irreversible nature of the removal process makes data collection expensive. This paper proposes a cutting-surface-aware Model-Based Reinforcement Learning (MBRL) method for robotic grinding. Our method employs a cutting-surface-aware model as the object's shape transition model, which in turn is composed of a geometric cutting model and a cutting-surface-deviation model, based on the assumption that the robot action can specify the cutting surface made by the tool. Furthermore, according to the grinding resistance theory, the cutting-surface-deviation model does not require raw shape information, making the model's dimensions smaller and easier to learn than a naive shape transition model directly mapping the shapes. Through evaluation and comparison by simulation and real robot experiments, we confirm that our MBRL method can achieve high data efficiency for learning object shaping by grinding and also provide generalization capability for initial and target shapes that differ from the training data.
Randomized-to-Canonical Model Predictive Control for Real-world Visual Robotic Manipulation
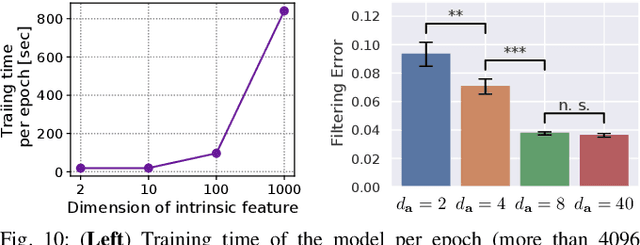
Jul 05, 2022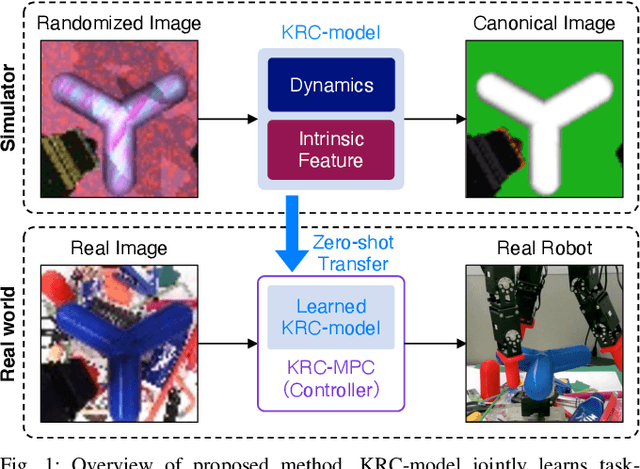
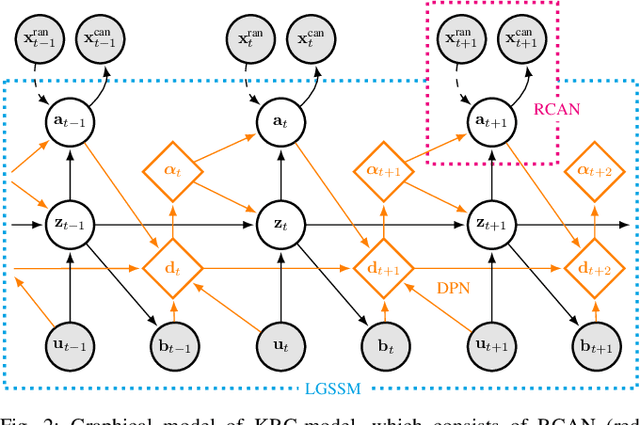
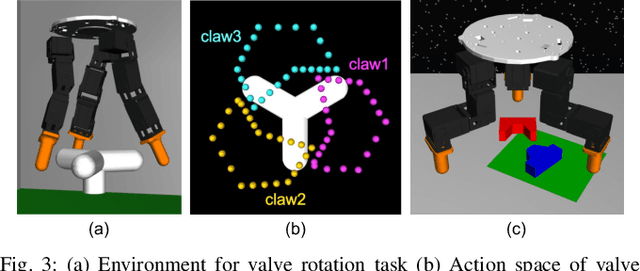
Many works have recently explored Sim-to-real transferable visual model predictive control (MPC). However, such works are limited to one-shot transfer, where real-world data must be collected once to perform the sim-to-real transfer, which remains a significant human effort in transferring the models learned in simulations to new domains in the real world. To alleviate this problem, we first propose a novel model-learning framework called Kalman Randomized-to-Canonical Model (KRC-model). This framework is capable of extracting task-relevant intrinsic features and their dynamics from randomized images. We then propose Kalman Randomized-to-Canonical Model Predictive Control (KRC-MPC) as a zero-shot sim-to-real transferable visual MPC using KRC-model. The effectiveness of our method is evaluated through a valve rotation task by a robot hand in both simulation and the real world, and a block mating task in simulation. The experimental results show that KRC-MPC can be applied to various real domains and tasks in a zero-shot manner.