 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDISF: Disentangled Iterative Surface Fitting for Contact-stable Grasp Planning with Grasp Pose Alignment to the Object Center of Mass
Dec 31, 2025In this work, we address the limitation of surface fitting-based grasp planning algorithm, which primarily focuses on geometric alignment between the gripper and object surface while overlooking the stability of contact point distribution, often resulting in unstable grasps due to inadequate contact configurations. To overcome this limitation, we propose a novel surface fitting algorithm that integrates contact stability while preserving geometric compatibility. Inspired by human grasping behavior, our method disentangles the grasp pose optimization into three sequential steps: (1) rotation optimization to align contact normals, (2) translation refinement to improve the alignment between the gripper frame origin and the object Center of Mass (CoM), and (3) gripper aperture adjustment to optimize contact point distribution. We validate our approach in simulation across 15 objects under both Known-shape (with clean CAD-derived dataset) and Observed-shape (with YCB object dataset) settings, including cross-platform grasp execution on three robot--gripper platforms. We further validate the method in real-world grasp experiments on a UR3e robot. Overall, DISF reduces CoM misalignment while maintaining geometric compatibility, translating into higher grasp success in both simulation and real-world execution compared to baselines. Additional videos and supplementary results are available on our project page: https://tomoya-yamanokuchi.github.io/disf-ras-project-page/
Disentangled Iterative Surface Fitting for Contact-stable Grasp Planning
Feb 17, 2025In this work, we address the limitation of surface fitting-based grasp planning algorithm, which primarily focuses on geometric alignment between the gripper and object surface while overlooking the stability of contact point distribution, often resulting in unstable grasps due to inadequate contact configurations. To overcome this limitation, we propose a novel surface fitting algorithm that integrates contact stability while preserving geometric compatibility. Inspired by human grasping behavior, our method disentangles the grasp pose optimization into three sequential steps: (1) rotation optimization to align contact normals, (2) translation refinement to improve Center of Mass (CoM) alignment, and (3) gripper aperture adjustment to optimize contact point distribution. We validate our approach through simulations on ten YCB dataset objects, demonstrating an 80% improvement in grasp success over conventional surface fitting methods that disregard contact stability. Further details can be found on our project page: https://tomoya-yamanokuchi.github.io/disf-project-page/.
Weber-Fechner Law in Temporal Difference learning derived from Control as Inference
Dec 30, 2024



This paper investigates a novel nonlinear update rule based on temporal difference (TD) errors in reinforcement learning (RL). The update rule in the standard RL states that the TD error is linearly proportional to the degree of updates, treating all rewards equally without no bias. On the other hand, the recent biological studies revealed that there are nonlinearities in the TD error and the degree of updates, biasing policies optimistic or pessimistic. Such biases in learning due to nonlinearities are expected to be useful and intentionally leftover features in biological learning. Therefore, this research explores a theoretical framework that can leverage the nonlinearity between the degree of the update and TD errors. To this end, we focus on a control as inference framework, since it is known as a generalized formulation encompassing various RL and optimal control methods. In particular, we investigate the uncomputable nonlinear term needed to be approximately excluded in the derivation of the standard RL from control as inference. By analyzing it, Weber-Fechner law (WFL) is found, namely, perception (a.k.a. the degree of updates) in response to stimulus change (a.k.a. TD error) is attenuated by increase in the stimulus intensity (a.k.a. the value function). To numerically reveal the utilities of WFL on RL, we then propose a practical implementation using a reward-punishment framework and modifying the definition of optimality. Analysis of this implementation reveals that two utilities can be expected i) to increase rewards to a certain level early, and ii) to sufficiently suppress punishment. We finally investigate and discuss the expected utilities through simulations and robot experiments. As a result, the proposed RL algorithm with WFL shows the expected utilities that accelerate the reward-maximizing startup and continue to suppress punishments during learning.
Randomized-to-Canonical Model Predictive Control for Real-world Visual Robotic Manipulation
Jul 05, 2022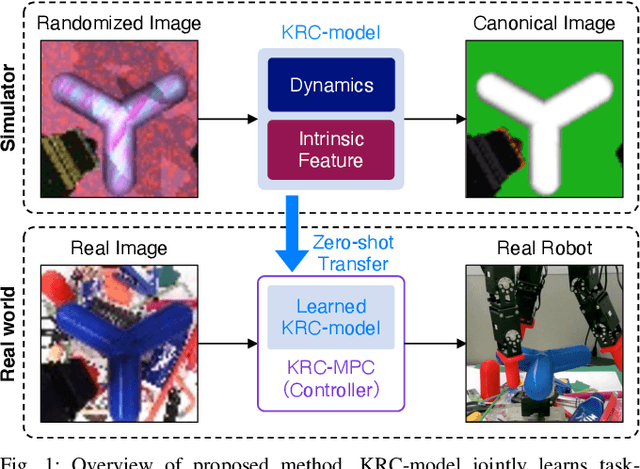
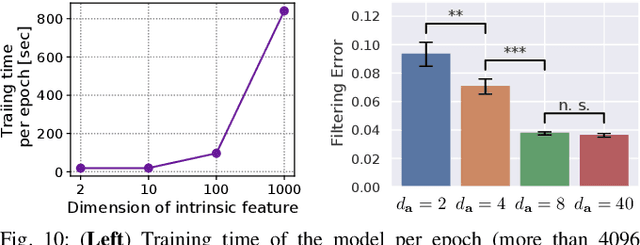
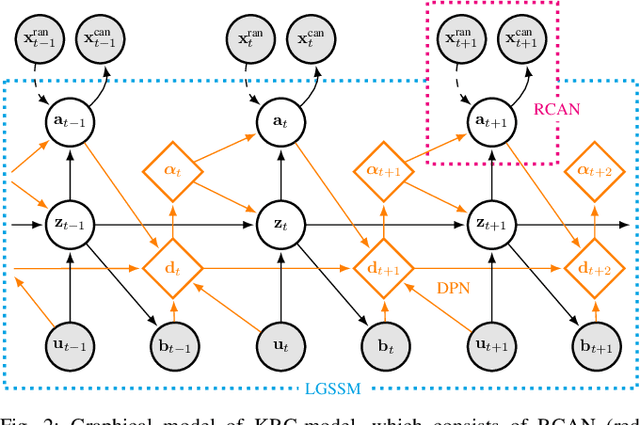
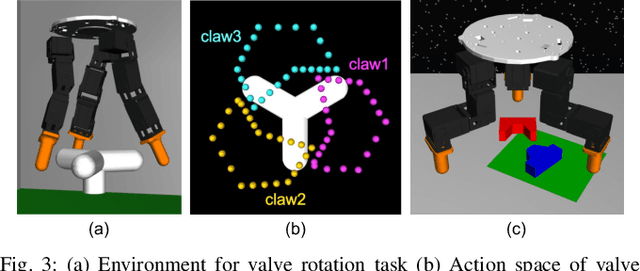
Many works have recently explored Sim-to-real transferable visual model predictive control (MPC). However, such works are limited to one-shot transfer, where real-world data must be collected once to perform the sim-to-real transfer, which remains a significant human effort in transferring the models learned in simulations to new domains in the real world. To alleviate this problem, we first propose a novel model-learning framework called Kalman Randomized-to-Canonical Model (KRC-model). This framework is capable of extracting task-relevant intrinsic features and their dynamics from randomized images. We then propose Kalman Randomized-to-Canonical Model Predictive Control (KRC-MPC) as a zero-shot sim-to-real transferable visual MPC using KRC-model. The effectiveness of our method is evaluated through a valve rotation task by a robot hand in both simulation and the real world, and a block mating task in simulation. The experimental results show that KRC-MPC can be applied to various real domains and tasks in a zero-shot manner.