 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Sim-to-Real Cloth Untangling through Reduced-Resolution Observations via Adaptive Force-Difference Quantization
Mar 14, 2026Robotic cloth untangling requires progressively disentangling fabric by adapting pulling actions to changing contact and tension conditions. Because large-scale real-world training is impractical due to cloth damage and hardware wear, sim-to-real policy transfer is a promising solution. However, cloth manipulation is highly sensitive to interaction dynamics, and policies that depend on precise force magnitudes often fail after transfer because similar force responses cannot be reproduced due to the reality gap. We observe that untangling is largely characterized by qualitative tension transitions rather than exact force values. This indicates that directly minimizing the sim-to-real gap in raw force measurements does not necessarily align with the task structure. We therefore hypothesize that emphasizing coarse force-change patterns while suppressing fine environment-dependent variations can improve robustness of sim-to-real transfer. Based on this insight, we propose Adaptive Force-Difference Quantization (ADQ), which reduces observation resolution by representing force inputs as discretized temporal differences and learning state-dependent quantization thresholds adaptively. This representation mitigates overfitting to environment-specific force characteristics and facilitates direct sim-to-real transfer. Experiments in both simulation and real-world cloth untangling demonstrate that ADQ achieves higher success rates and exhibits greater robustness in sim-to-real transfer than policies using raw force inputs. Supplementary video is available at https://youtu.be/ZeoBs-t0AWc
Cooperative Grasping and Transportation using Multi-agent Reinforcement Learning with Ternary Force Representation
Nov 21, 2024



Cooperative grasping and transportation require effective coordination to complete the task. This study focuses on the approach leveraging force-sensing feedback, where robots use sensors to detect forces applied by others on an object to achieve coordination. Unlike explicit communication, it avoids delays and interruptions; however, force-sensing is highly sensitive and prone to interference from variations in grasping environment, such as changes in grasping force, grasping pose, object size and geometry, which can interfere with force signals, subsequently undermining coordination. We propose multi-agent reinforcement learning (MARL) with ternary force representation, a force representation that maintains consistent representation against variations in grasping environment. The simulation and real-world experiments demonstrate the robustness of the proposed method to changes in grasping force, object size and geometry as well as inherent sim2real gap.
Self-Supervised Learning of Grasping Arbitrary Objects On-the-Move
Nov 15, 2024

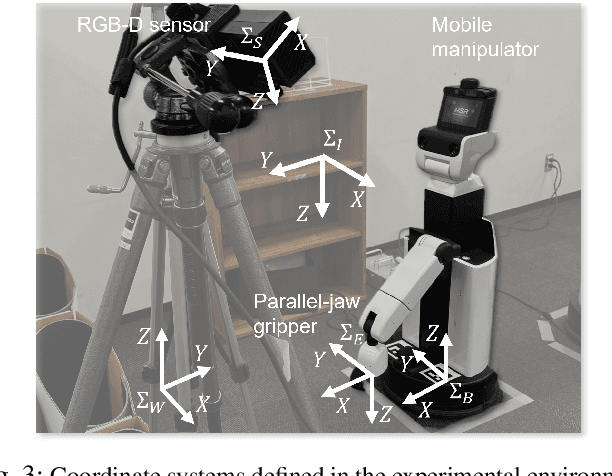

Mobile grasping enhances manipulation efficiency by utilizing robots' mobility. This study aims to enable a commercial off-the-shelf robot for mobile grasping, requiring precise timing and pose adjustments. Self-supervised learning can develop a generalizable policy to adjust the robot's velocity and determine grasp position and orientation based on the target object's shape and pose. Due to mobile grasping's complexity, action primitivization and step-by-step learning are crucial to avoid data sparsity in learning from trial and error. This study simplifies mobile grasping into two grasp action primitives and a moving action primitive, which can be operated with limited degrees of freedom for the manipulator. This study introduces three fully convolutional neural network (FCN) models to predict static grasp primitive, dynamic grasp primitive, and residual moving velocity error from visual inputs. A two-stage grasp learning approach facilitates seamless FCN model learning. The ablation study demonstrated that the proposed method achieved the highest grasping accuracy and pick-and-place efficiency. Furthermore, randomizing object shapes and environments in the simulation effectively achieved generalizable mobile grasping.
Robust Iterative Value Conversion: Deep Reinforcement Learning for Neurochip-driven Edge Robots
Aug 23, 2024



A neurochip is a device that reproduces the signal processing mechanisms of brain neurons and calculates Spiking Neural Networks (SNNs) with low power consumption and at high speed. Thus, neurochips are attracting attention from edge robot applications, which suffer from limited battery capacity. This paper aims to achieve deep reinforcement learning (DRL) that acquires SNN policies suitable for neurochip implementation. Since DRL requires a complex function approximation, we focus on conversion techniques from Floating Point NN (FPNN) because it is one of the most feasible SNN techniques. However, DRL requires conversions to SNNs for every policy update to collect the learning samples for a DRL-learning cycle, which updates the FPNN policy and collects the SNN policy samples. Accumulative conversion errors can significantly degrade the performance of the SNN policies. We propose Robust Iterative Value Conversion (RIVC) as a DRL that incorporates conversion error reduction and robustness to conversion errors. To reduce them, FPNN is optimized with the same number of quantization bits as an SNN. The FPNN output is not significantly changed by quantization. To robustify the conversion error, an FPNN policy that is applied with quantization is updated to increase the gap between the probability of selecting the optimal action and other actions. This step prevents unexpected replacements of the policy's optimal actions. We verified RIVC's effectiveness on a neurochip-driven robot. The results showed that RIVC consumed 1/15 times less power and increased the calculation speed by five times more than an edge CPU (quad-core ARM Cortex-A72). The previous framework with no countermeasures against conversion errors failed to train the policies. Videos from our experiments are available: https://youtu.be/Q5Z0-BvK1Tc.
Goal-Aware Generative Adversarial Imitation Learning from Imperfect Demonstration for Robotic Cloth Manipulation
Sep 21, 2022



Generative Adversarial Imitation Learning (GAIL) can learn policies without explicitly defining the reward function from demonstrations. GAIL has the potential to learn policies with high-dimensional observations as input, e.g., images. By applying GAIL to a real robot, perhaps robot policies can be obtained for daily activities like washing, folding clothes, cooking, and cleaning. However, human demonstration data are often imperfect due to mistakes, which degrade the performance of the resulting policies. We address this issue by focusing on the following features: 1) many robotic tasks are goal-reaching tasks, and 2) labeling such goal states in demonstration data is relatively easy. With these in mind, this paper proposes Goal-Aware Generative Adversarial Imitation Learning (GA-GAIL), which trains a policy by introducing a second discriminator to distinguish the goal state in parallel with the first discriminator that indicates the demonstration data. This extends a standard GAIL framework to more robustly learn desirable policies even from imperfect demonstrations through a goal-state discriminator that promotes achieving the goal state. Furthermore, GA-GAIL employs the Entropy-maximizing Deep P-Network (EDPN) as a generator, which considers both the smoothness and causal entropy in the policy update, to achieve stable policy learning from two discriminators. Our proposed method was successfully applied to two real-robotic cloth-manipulation tasks: turning a handkerchief over and folding clothes. We confirmed that it learns cloth-manipulation policies without task-specific reward function design. Video of the real experiments are available at https://youtu.be/h_nII2ooUrE.
Cyclic Policy Distillation: Sample-Efficient Sim-to-Real Reinforcement Learning with Domain Randomization
Jul 29, 2022
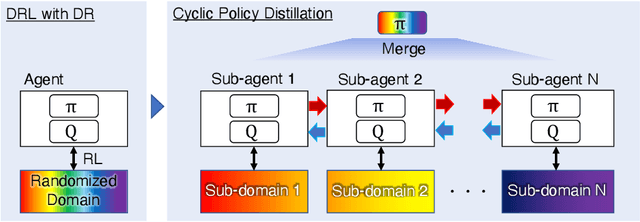

Deep reinforcement learning with domain randomization learns a control policy in various simulations with randomized physical and sensor model parameters to become transferable to the real world in a zero-shot setting. However, a huge number of samples are often required to learn an effective policy when the range of randomized parameters is extensive due to the instability of policy updates. To alleviate this problem, we propose a sample-efficient method named Cyclic Policy Distillation (CPD). CPD divides the range of randomized parameters into several small sub-domains and assigns a local policy to each sub-domain. Then, the learning of local policies is performed while {\it cyclically} transitioning the target sub-domain to neighboring sub-domains and exploiting the learned values/policies of the neighbor sub-domains with a monotonic policy-improvement scheme. Finally, all of the learned local policies are distilled into a global policy for sim-to-real transfer. The effectiveness and sample efficiency of CPD are demonstrated through simulations with four tasks (Pendulum from OpenAIGym and Pusher, Swimmer, and HalfCheetah from Mujoco), and a real-robot ball-dispersal task.
Randomized-to-Canonical Model Predictive Control for Real-world Visual Robotic Manipulation
Jul 05, 2022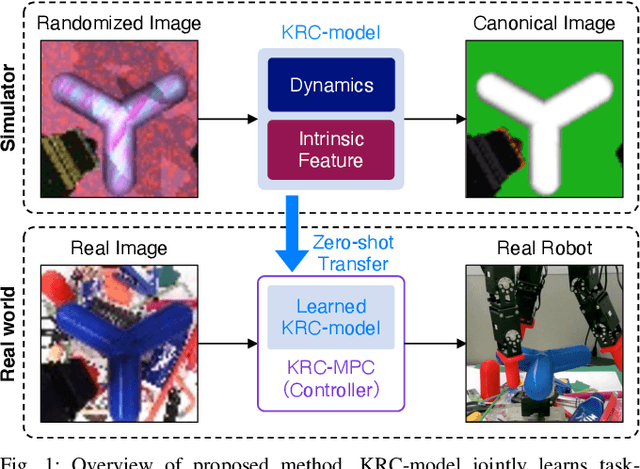
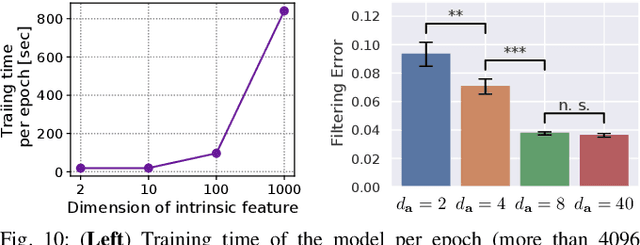
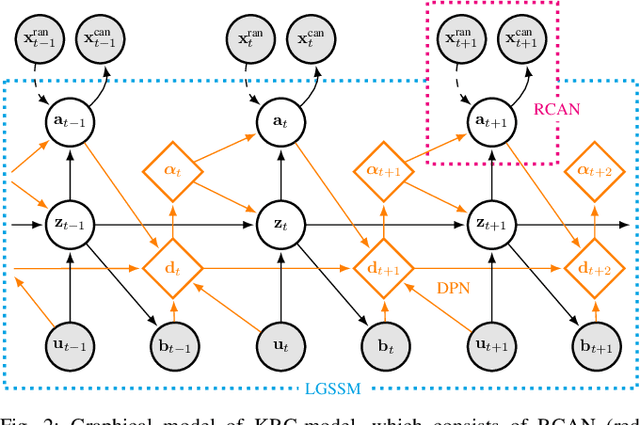
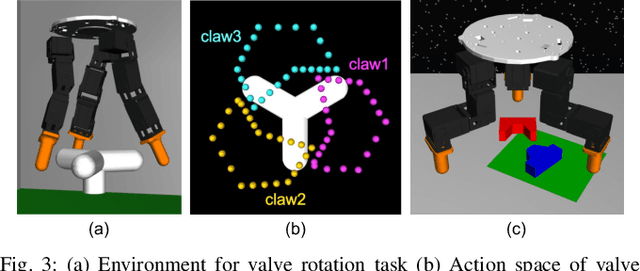
Many works have recently explored Sim-to-real transferable visual model predictive control (MPC). However, such works are limited to one-shot transfer, where real-world data must be collected once to perform the sim-to-real transfer, which remains a significant human effort in transferring the models learned in simulations to new domains in the real world. To alleviate this problem, we first propose a novel model-learning framework called Kalman Randomized-to-Canonical Model (KRC-model). This framework is capable of extracting task-relevant intrinsic features and their dynamics from randomized images. We then propose Kalman Randomized-to-Canonical Model Predictive Control (KRC-MPC) as a zero-shot sim-to-real transferable visual MPC using KRC-model. The effectiveness of our method is evaluated through a valve rotation task by a robot hand in both simulation and the real world, and a block mating task in simulation. The experimental results show that KRC-MPC can be applied to various real domains and tasks in a zero-shot manner.
Binarized P-Network: Deep Reinforcement Learning of Robot Control from Raw Images on FPGA
Sep 15, 2021This paper explores a Deep Reinforcement Learning (DRL) approach for designing image-based control for edge robots to be implemented on Field Programmable Gate Arrays (FPGAs). Although FPGAs are more power-efficient than CPUs and GPUs, a typical DRL method cannot be applied since they are composed of many Logic Blocks (LBs) for high-speed logical operations but low-speed real-number operations. To cope with this problem, we propose a novel DRL algorithm called Binarized P-Network (BPN), which learns image-input control policies using Binarized Convolutional Neural Networks (BCNNs). To alleviate the instability of reinforcement learning caused by a BCNN with low function approximation accuracy, our BPN adopts a robust value update scheme called Conservative Value Iteration, which is tolerant of function approximation errors. We confirmed the BPN's effectiveness through applications to a visual tracking task in simulation and real-robot experiments with FPGA.