 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymmetric Behavior Regularization via Taylor Expansion of Symmetry
Aug 06, 2025



This paper introduces symmetric divergences to behavior regularization policy optimization (BRPO) to establish a novel offline RL framework. Existing methods focus on asymmetric divergences such as KL to obtain analytic regularized policies and a practical minimization objective. We show that symmetric divergences do not permit an analytic policy as regularization and can incur numerical issues as loss. We tackle these challenges by the Taylor series of $f$-divergence. Specifically, we prove that an analytic policy can be obtained with a finite series. For loss, we observe that symmetric divergences can be decomposed into an asymmetry and a conditional symmetry term, Taylor-expanding the latter alleviates numerical issues. Summing together, we propose Symmetric $f$ Actor-Critic (S$f$-AC), the first practical BRPO algorithm with symmetric divergences. Experimental results on distribution approximation and MuJoCo verify that S$f$-AC performs competitively.
Towards Physiologically Sensible Predictions via the Rule-based Reinforcement Learning Layer
Jan 31, 2025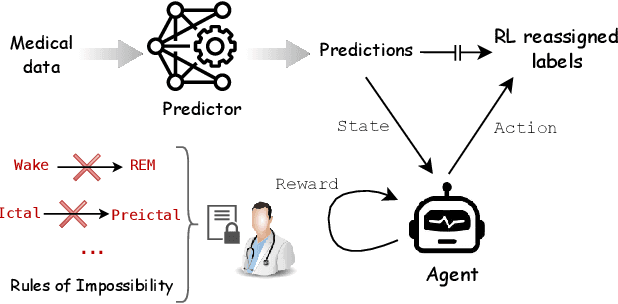
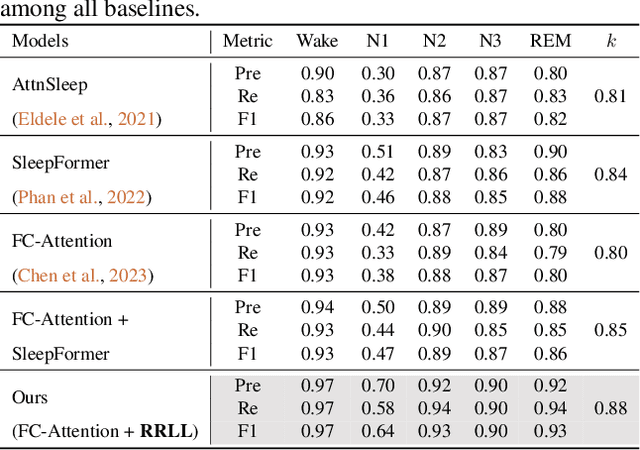
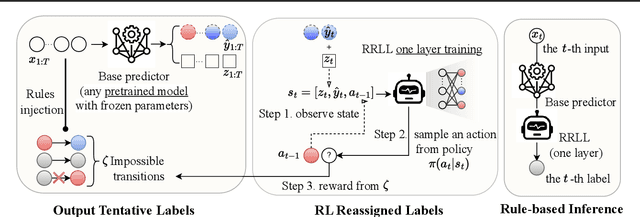
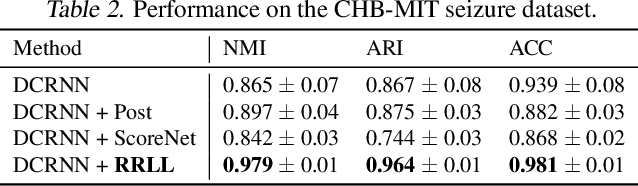
This paper adds to the growing literature of reinforcement learning (RL) for healthcare by proposing a novel paradigm: augmenting any predictor with Rule-based RL Layer (RRLL) that corrects the model's physiologically impossible predictions. Specifically, RRLL takes as input states predicted labels and outputs corrected labels as actions. The reward of the state-action pair is evaluated by a set of general rules. RRLL is efficient, general and lightweight: it does not require heavy expert knowledge like prior work but only a set of impossible transitions. This set is much smaller than all possible transitions; yet it can effectively reduce physiologically impossible mistakes made by the state-of-the-art predictor models. We verify the utility of RRLL on a variety of important healthcare classification problems and observe significant improvements using the same setup, with only the domain-specific set of impossibility changed. In-depth analysis shows that RRLL indeed improves accuracy by effectively reducing the presence of physiologically impossible predictions.
Fat-to-Thin Policy Optimization: Offline RL with Sparse Policies
Jan 24, 2025



Sparse continuous policies are distributions that can choose some actions at random yet keep strictly zero probability for the other actions, which are radically different from the Gaussian. They have important real-world implications, e.g. in modeling safety-critical tasks like medicine. The combination of offline reinforcement learning and sparse policies provides a novel paradigm that enables learning completely from logged datasets a safety-aware sparse policy. However, sparse policies can cause difficulty with the existing offline algorithms which require evaluating actions that fall outside of the current support. In this paper, we propose the first offline policy optimization algorithm that tackles this challenge: Fat-to-Thin Policy Optimization (FtTPO). Specifically, we maintain a fat (heavy-tailed) proposal policy that effectively learns from the dataset and injects knowledge to a thin (sparse) policy, which is responsible for interacting with the environment. We instantiate FtTPO with the general $q$-Gaussian family that encompasses both heavy-tailed and sparse policies and verify that it performs favorably in a safety-critical treatment simulation and the standard MuJoCo suite. Our code is available at \url{https://github.com/lingweizhu/fat2thin}.
$\mathbb{BEHR}$NOULLI: A Binary EHR Data-Oriented Medication Recommendation System
Aug 18, 2024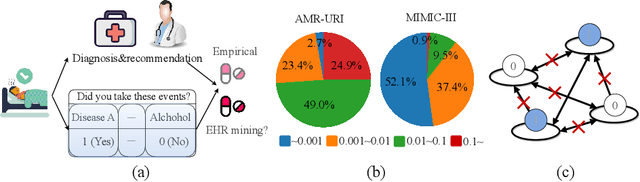
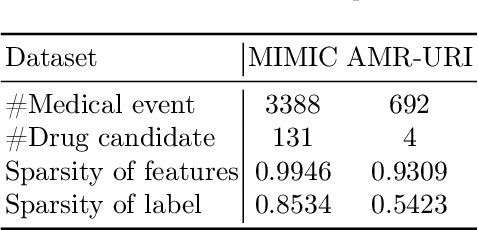
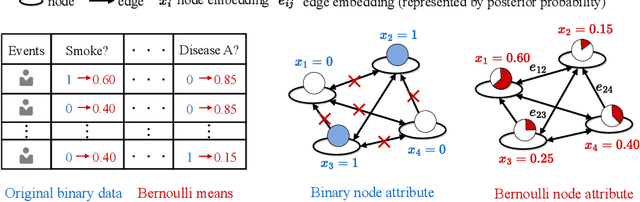

The medical community believes binary medical event outcomes in EHR data contain sufficient information for making a sensible recommendation. However, there are two challenges to effectively utilizing such data: (1) modeling the relationship between massive 0,1 event outcomes is difficult, even with expert knowledge; (2) in practice, learning can be stalled by the binary values since the equally important 0 entries propagate no learning signals. Currently, there is a large gap between the assumed sufficient information and the reality that no promising results have been shown by utilizing solely the binary data: visiting or secondary information is often necessary to reach acceptable performance. In this paper, we attempt to build the first successful binary EHR data-oriented drug recommendation system by tackling the two difficulties, making sensible drug recommendations solely using the binary EHR medical records. To this end, we take a statistical perspective to view the EHR data as a sample from its cohorts and transform them into continuous Bernoulli probabilities. The transformed entries not only model a deterministic binary event with a distribution but also allow reflecting \emph{event-event} relationship by conditional probability. A graph neural network is learned on top of the transformation. It captures event-event correlations while emphasizing \emph{event-to-patient} features. Extensive results demonstrate that the proposed method achieves state-of-the-art performance on large-scale databases, outperforming baseline methods that use secondary information by a large margin. The source code is available at \url{https://github.com/chenzRG/BEHRMecom}
q-exponential family for policy optimization
Aug 14, 2024Policy optimization methods benefit from a simple and tractable policy functional, usually the Gaussian for continuous action spaces. In this paper, we consider a broader policy family that remains tractable: the $q$-exponential family. This family of policies is flexible, allowing the specification of both heavy-tailed policies ($q>1$) and light-tailed policies ($q<1$). This paper examines the interplay between $q$-exponential policies for several actor-critic algorithms conducted on both online and offline problems. We find that heavy-tailed policies are more effective in general and can consistently improve on Gaussian. In particular, we find the Student's t-distribution to be more stable than the Gaussian across settings and that a heavy-tailed $q$-Gaussian for Tsallis Advantage Weighted Actor-Critic consistently performs well in offline benchmark problems. Our code is available at \url{https://github.com/lingweizhu/qexp}.
Drugs Resistance Analysis from Scarce Health Records via Multi-task Graph Representation
Mar 08, 2023



Clinicians prescribe antibiotics by looking at the patient's health record with an experienced eye. However, the therapy might be rendered futile if the patient has drug resistance. Determining drug resistance requires time-consuming laboratory-level testing while applying clinicians' heuristics in an automated way is difficult due to the categorical or binary medical events that constitute health records. In this paper, we propose a novel framework for rapid clinical intervention by viewing health records as graphs whose nodes are mapped from medical events and edges as correspondence between events in given a time window. A novel graph-based model is then proposed to extract informative features and yield automated drug resistance analysis from those high-dimensional and scarce graphs. The proposed method integrates multi-task learning into a common feature extracting graph encoder for simultaneous analyses of multiple drugs as well as stabilizing learning. On a massive dataset comprising over 110,000 patients with urinary tract infections, we verify the proposed method is capable of attaining superior performance on the drug resistance prediction problem. Furthermore, automated drug recommendations resemblant to laboratory-level testing can also be made based on the model resistance analysis.
Generalized Munchausen Reinforcement Learning using Tsallis KL Divergence
Jan 27, 2023



Many policy optimization approaches in reinforcement learning incorporate a Kullback-Leilbler (KL) divergence to the previous policy, to prevent the policy from changing too quickly. This idea was initially proposed in a seminal paper on Conservative Policy Iteration, with approximations given by algorithms like TRPO and Munchausen Value Iteration (MVI). We continue this line of work by investigating a generalized KL divergence -- called the Tsallis KL divergence -- which use the $q$-logarithm in the definition. The approach is a strict generalization, as $q = 1$ corresponds to the standard KL divergence; $q > 1$ provides a range of new options. We characterize the types of policies learned under the Tsallis KL, and motivate when $q >1$ could be beneficial. To obtain a practical algorithm that incorporates Tsallis KL regularization, we extend MVI, which is one of the simplest approaches to incorporate KL regularization. We show that this generalized MVI($q$) obtains significant improvements over the standard MVI($q = 1$) across 35 Atari games.
Cyclic Policy Distillation: Sample-Efficient Sim-to-Real Reinforcement Learning with Domain Randomization
Jul 29, 2022
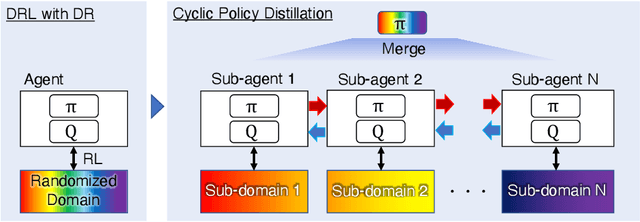

Deep reinforcement learning with domain randomization learns a control policy in various simulations with randomized physical and sensor model parameters to become transferable to the real world in a zero-shot setting. However, a huge number of samples are often required to learn an effective policy when the range of randomized parameters is extensive due to the instability of policy updates. To alleviate this problem, we propose a sample-efficient method named Cyclic Policy Distillation (CPD). CPD divides the range of randomized parameters into several small sub-domains and assigns a local policy to each sub-domain. Then, the learning of local policies is performed while {\it cyclically} transitioning the target sub-domain to neighboring sub-domains and exploiting the learned values/policies of the neighbor sub-domains with a monotonic policy-improvement scheme. Finally, all of the learned local policies are distilled into a global policy for sim-to-real transfer. The effectiveness and sample efficiency of CPD are demonstrated through simulations with four tasks (Pendulum from OpenAIGym and Pusher, Swimmer, and HalfCheetah from Mujoco), and a real-robot ball-dispersal task.
Cancer Subtyping by Improved Transcriptomic Features Using Vector Quantized Variational Autoencoder
Jul 20, 2022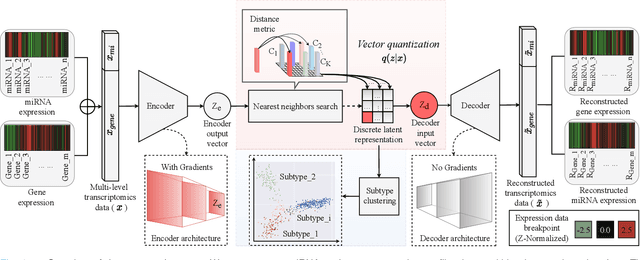
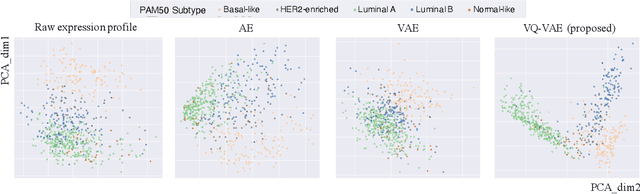
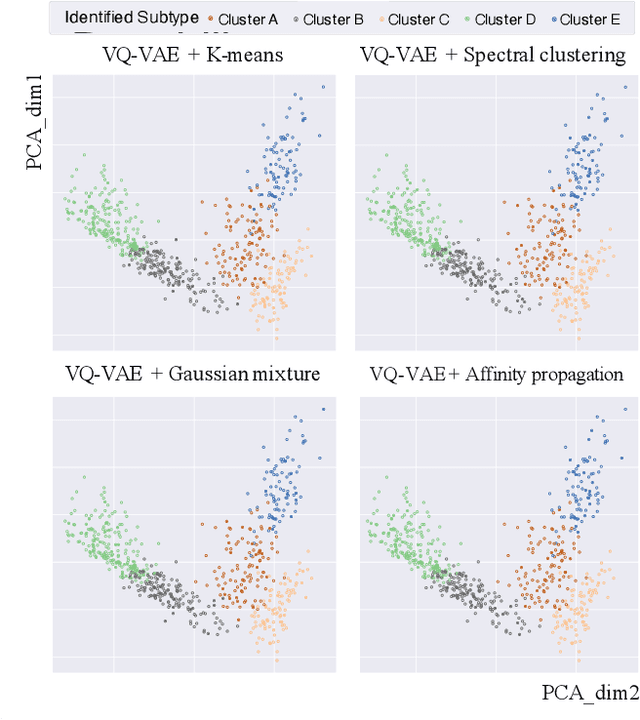
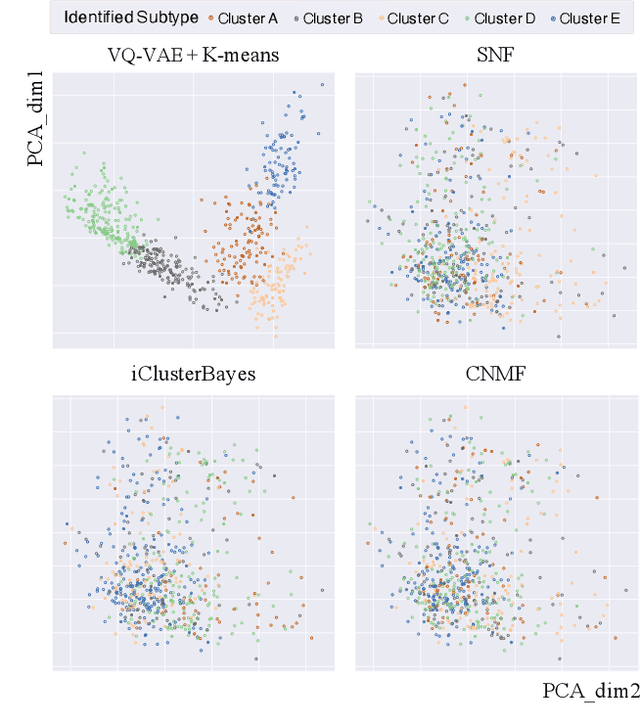
Defining and separating cancer subtypes is essential for facilitating personalized therapy modality and prognosis of patients. The definition of subtypes has been constantly recalibrated as a result of our deepened understanding. During this recalibration, researchers often rely on clustering of cancer data to provide an intuitive visual reference that could reveal the intrinsic characteristics of subtypes. The data being clustered are often omics data such as transcriptomics that have strong correlations to the underlying biological mechanism. However, while existing studies have shown promising results, they suffer from issues associated with omics data: sample scarcity and high dimensionality. As such, existing methods often impose unrealistic assumptions to extract useful features from the data while avoiding overfitting to spurious correlations. In this paper, we propose to leverage a recent strong generative model, Vector Quantized Variational AutoEncoder (VQ-VAE), to tackle the data issues and extract informative latent features that are crucial to the quality of subsequent clustering by retaining only information relevant to reconstructing the input. VQ-VAE does not impose strict assumptions and hence its latent features are better representations of the input, capable of yielding superior clustering performance with any mainstream clustering method. Extensive experiments and medical analysis on multiple datasets comprising 10 distinct cancers demonstrate the VQ-VAE clustering results can significantly and robustly improve prognosis over prevalent subtyping systems.
Automated Cancer Subtyping via Vector Quantization Mutual Information Maximization
Jun 22, 2022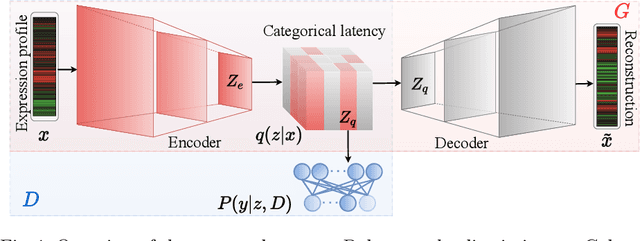
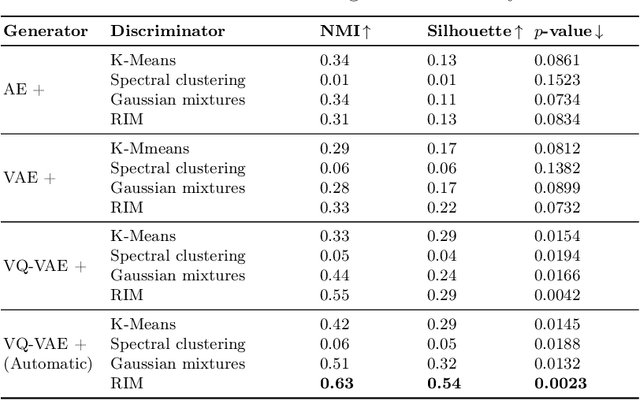
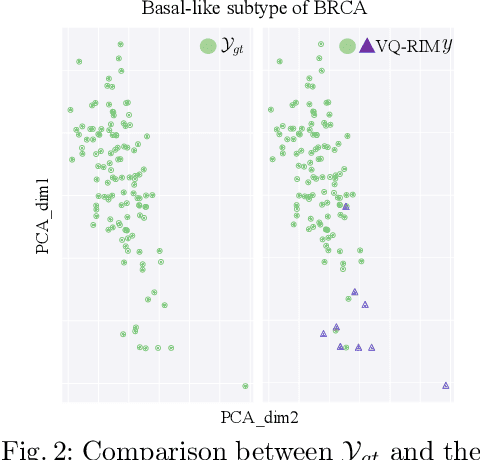
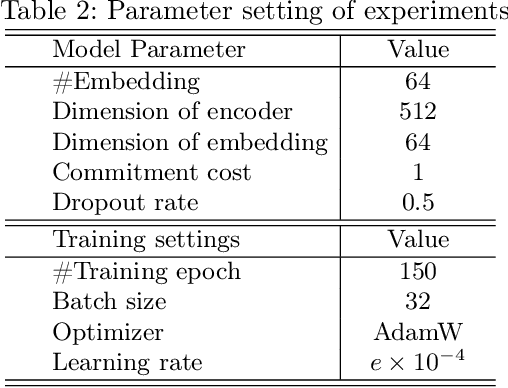
Cancer subtyping is crucial for understanding the nature of tumors and providing suitable therapy. However, existing labelling methods are medically controversial, and have driven the process of subtyping away from teaching signals. Moreover, cancer genetic expression profiles are high-dimensional, scarce, and have complicated dependence, thereby posing a serious challenge to existing subtyping models for outputting sensible clustering. In this study, we propose a novel clustering method for exploiting genetic expression profiles and distinguishing subtypes in an unsupervised manner. The proposed method adaptively learns categorical correspondence from latent representations of expression profiles to the subtypes output by the model. By maximizing the problem -- agnostic mutual information between input expression profiles and output subtypes, our method can automatically decide a suitable number of subtypes. Through experiments, we demonstrate that our proposed method can refine existing controversial labels, and, by further medical analysis, this refinement is proven to have a high correlation with cancer survival rates.