 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeODEBrain: Continuous-Time EEG Graph for Modeling Dynamic Brain Networks
Feb 26, 2026Modeling neural population dynamics is crucial for foundational neuroscientific research and various clinical applications. Conventional latent variable methods typically model continuous brain dynamics through discretizing time with recurrent architecture, which necessarily results in compounded cumulative prediction errors and failure of capturing instantaneous, nonlinear characteristics of EEGs. We propose ODEBRAIN, a Neural ODE latent dynamic forecasting framework to overcome these challenges by integrating spatio-temporal-frequency features into spectral graph nodes, followed by a Neural ODE modeling the continuous latent dynamics. Our design ensures that latent representations can capture stochastic variations of complex brain states at any given time point. Extensive experiments verify that ODEBRAIN can improve significantly over existing methods in forecasting EEG dynamics with enhanced robustness and generalization capabilities.
RepSPD: Enhancing SPD Manifold Representation in EEGs via Dynamic Graphs
Feb 26, 2026Decoding brain activity from electroencephalography (EEG) is crucial for neuroscience and clinical applications. Among recent advances in deep learning for EEG, geometric learning stands out as its theoretical underpinnings on symmetric positive definite (SPD) allows revealing structural connectivity analysis in a physics-grounded manner. However, current SPD-based methods focus predominantly on statistical aggregation of EEGs, with frequency-specific synchronization and local topological structures of brain regions neglected. Given this, we propose RepSPD, a novel geometric deep learning (GDL)-based model. RepSPD implements a cross-attention mechanism on the Riemannian manifold to modulate the geometric attributes of SPD with graph-derived functional connectivity features. On top of this, we introduce a global bidirectional alignment strategy to reshape tangent-space embeddings, mitigating geometric distortions caused by curvature and thereby enhancing geometric consistency. Extensive experiments demonstrate that our proposed framework significantly outperforms existing EEG representation methods, exhibiting superior robustness and generalization capabilities.
Object-Centric World Models for Causality-Aware Reinforcement Learning
Nov 18, 2025World models have been developed to support sample-efficient deep reinforcement learning agents. However, it remains challenging for world models to accurately replicate environments that are high-dimensional, non-stationary, and composed of multiple objects with rich interactions since most world models learn holistic representations of all environmental components. By contrast, humans perceive the environment by decomposing it into discrete objects, facilitating efficient decision-making. Motivated by this insight, we propose \emph{Slot Transformer Imagination with CAusality-aware reinforcement learning} (STICA), a unified framework in which object-centric Transformers serve as the world model and causality-aware policy and value networks. STICA represents each observation as a set of object-centric tokens, together with tokens for the agent action and the resulting reward, enabling the world model to predict token-level dynamics and interactions. The policy and value networks then estimate token-level cause--effect relations and use them in the attention layers, yielding causality-guided decision-making. Experiments on object-rich benchmarks demonstrate that STICA consistently outperforms state-of-the-art agents in both sample efficiency and final performance.
Image Interpolation with Score-based Riemannian Metrics of Diffusion Models
Apr 28, 2025Diffusion models excel in content generation by implicitly learning the data manifold, yet they lack a practical method to leverage this manifold - unlike other deep generative models equipped with latent spaces. This paper introduces a novel framework that treats the data space of pre-trained diffusion models as a Riemannian manifold, with a metric derived from the score function. Experiments with MNIST and Stable Diffusion show that this geometry-aware approach yields image interpolations that are more realistic, less noisy, and more faithful to prompts than existing methods, demonstrating its potential for improved content generation and editing.
Learning Hamiltonian Density Using DeepONet
Feb 27, 2025

In recent years, deep learning for modeling physical phenomena which can be described by partial differential equations (PDEs) have received significant attention. For example, for learning Hamiltonian mechanics, methods based on deep neural networks such as Hamiltonian Neural Networks (HNNs) and their variants have achieved progress. However, existing methods typically depend on the discretization of data, and the determination of required differential operators is often necessary. Instead, in this work, we propose an operator learning approach for modeling wave equations. In particular, we present a method to compute the variational derivatives that are needed to formulate the equations using the automatic differentiation algorithm. The experiments demonstrated that the proposed method is able to learn the operator that defines the Hamiltonian density of waves from data with unspecific discretization without determination of the differential operators.
Poisson-Dirac Neural Networks for Modeling Coupled Dynamical Systems across Domains
Oct 15, 2024
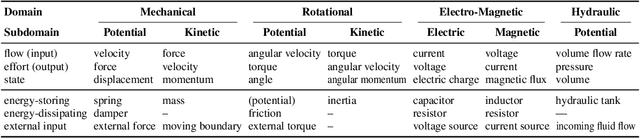
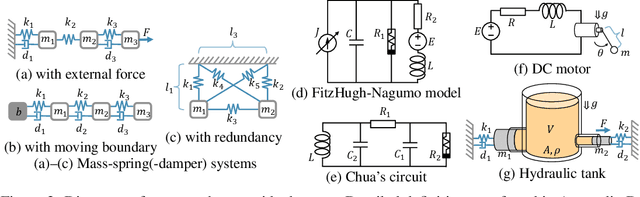
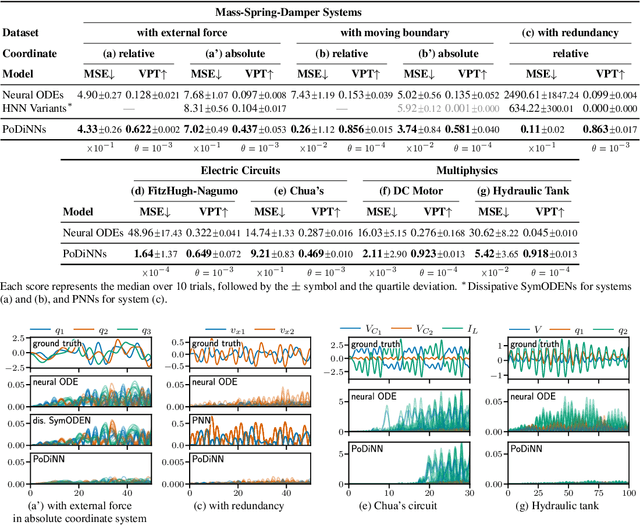
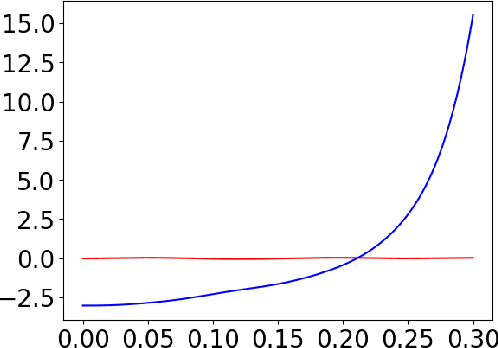
Deep learning has achieved great success in modeling dynamical systems, providing data-driven simulators to predict complex phenomena, even without known governing equations. However, existing models have two major limitations: their narrow focus on mechanical systems and their tendency to treat systems as monolithic. These limitations reduce their applicability to dynamical systems in other domains, such as electrical and hydraulic systems, and to coupled systems. To address these limitations, we propose Poisson-Dirac Neural Networks (PoDiNNs), a novel framework based on the Dirac structure that unifies the port-Hamiltonian and Poisson formulations from geometric mechanics. This framework enables a unified representation of various dynamical systems across multiple domains as well as their interactions and degeneracies arising from couplings. Our experiments demonstrate that PoDiNNs offer improved accuracy and interpretability in modeling unknown coupled dynamical systems from data.
Good Lattice Training: Physics-Informed Neural Networks Accelerated by Number Theory
Jul 26, 2023



Physics-informed neural networks (PINNs) offer a novel and efficient approach to solving partial differential equations (PDEs). Their success lies in the physics-informed loss, which trains a neural network to satisfy a given PDE at specific points and to approximate the solution. However, the solutions to PDEs are inherently infinite-dimensional, and the distance between the output and the solution is defined by an integral over the domain. Therefore, the physics-informed loss only provides a finite approximation, and selecting appropriate collocation points becomes crucial to suppress the discretization errors, although this aspect has often been overlooked. In this paper, we propose a new technique called good lattice training (GLT) for PINNs, inspired by number theoretic methods for numerical analysis. GLT offers a set of collocation points that are effective even with a small number of points and for multi-dimensional spaces. Our experiments demonstrate that GLT requires 2--20 times fewer collocation points (resulting in lower computational cost) than uniformly random sampling or Latin hypercube sampling, while achieving competitive performance.
Deep Curvilinear Editing: Commutative and Nonlinear Image Manipulation for Pretrained Deep Generative Model
Nov 26, 2022Semantic editing of images is the fundamental goal of computer vision. Although deep learning methods, such as generative adversarial networks (GANs), are capable of producing high-quality images, they often do not have an inherent way of editing generated images semantically. Recent studies have investigated a way of manipulating the latent variable to determine the images to be generated. However, methods that assume linear semantic arithmetic have certain limitations in terms of the quality of image editing, whereas methods that discover nonlinear semantic pathways provide non-commutative editing, which is inconsistent when applied in different orders. This study proposes a novel method called deep curvilinear editing (DeCurvEd) to determine semantic commuting vector fields on the latent space. We theoretically demonstrate that owing to commutativity, the editing of multiple attributes depends only on the quantities and not on the order. Furthermore, we experimentally demonstrate that compared to previous methods, the nonlinear and commutative nature of DeCurvEd facilitates the disentanglement of image attributes and provides higher-quality editing.
FINDE: Neural Differential Equations for Finding and Preserving Invariant Quantities
Oct 01, 2022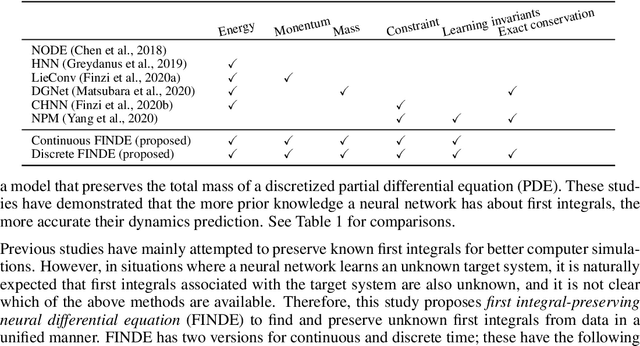

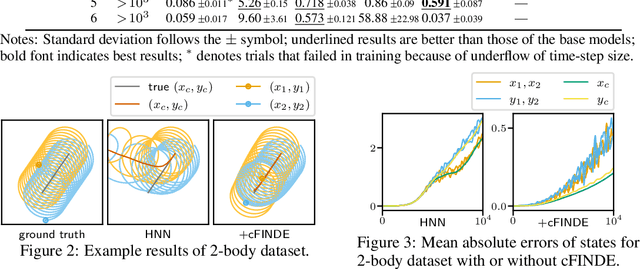
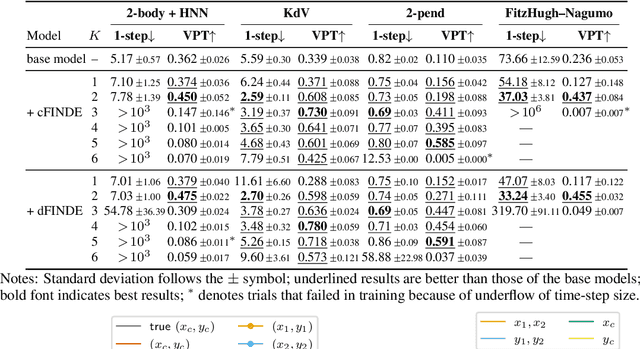
Many real-world dynamical systems are associated with first integrals (a.k.a. invariant quantities), which are quantities that remain unchanged over time. The discovery and understanding of first integrals are fundamental and important topics both in the natural sciences and in industrial applications. First integrals arise from the conservation laws of system energy, momentum, and mass, and from constraints on states; these are typically related to specific geometric structures of the governing equations. Existing neural networks designed to ensure such first integrals have shown excellent accuracy in modeling from data. However, these models incorporate the underlying structures, and in most situations where neural networks learn unknown systems, these structures are also unknown. This limitation needs to be overcome for scientific discovery and modeling of unknown systems. To this end, we propose first integral-preserving neural differential equation (FINDE). By leveraging the projection method and the discrete gradient method, FINDE finds and preserves first integrals from data, even in the absence of prior knowledge about underlying structures. Experimental results demonstrate that FINDE can predict future states of target systems much longer and find various quantities consistent with well-known first integrals in a unified manner.
Cancer Subtyping by Improved Transcriptomic Features Using Vector Quantized Variational Autoencoder
Jul 20, 2022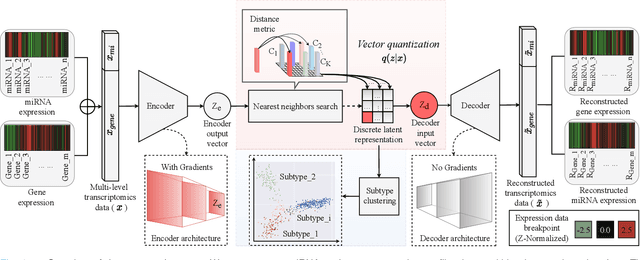
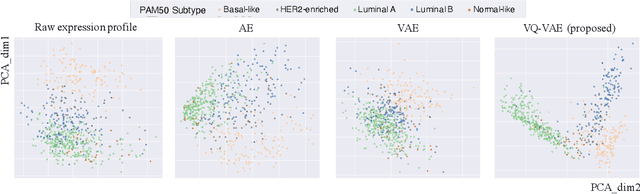
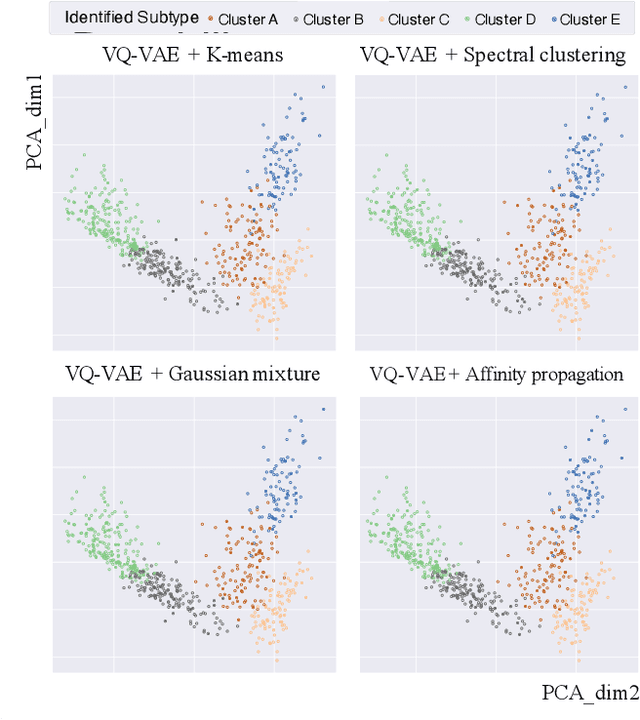
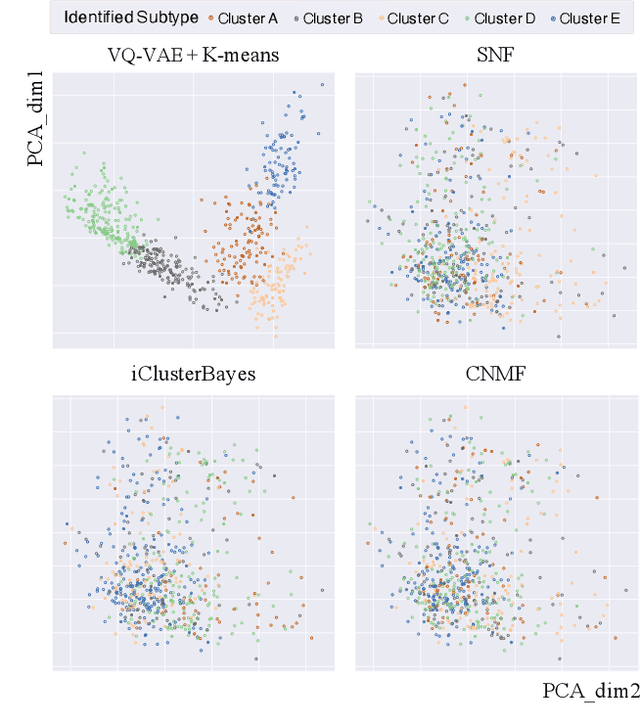
Defining and separating cancer subtypes is essential for facilitating personalized therapy modality and prognosis of patients. The definition of subtypes has been constantly recalibrated as a result of our deepened understanding. During this recalibration, researchers often rely on clustering of cancer data to provide an intuitive visual reference that could reveal the intrinsic characteristics of subtypes. The data being clustered are often omics data such as transcriptomics that have strong correlations to the underlying biological mechanism. However, while existing studies have shown promising results, they suffer from issues associated with omics data: sample scarcity and high dimensionality. As such, existing methods often impose unrealistic assumptions to extract useful features from the data while avoiding overfitting to spurious correlations. In this paper, we propose to leverage a recent strong generative model, Vector Quantized Variational AutoEncoder (VQ-VAE), to tackle the data issues and extract informative latent features that are crucial to the quality of subsequent clustering by retaining only information relevant to reconstructing the input. VQ-VAE does not impose strict assumptions and hence its latent features are better representations of the input, capable of yielding superior clustering performance with any mainstream clustering method. Extensive experiments and medical analysis on multiple datasets comprising 10 distinct cancers demonstrate the VQ-VAE clustering results can significantly and robustly improve prognosis over prevalent subtyping systems.