 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCancer Subtyping by Improved Transcriptomic Features Using Vector Quantized Variational Autoencoder
Paper and Code
Jul 20, 2022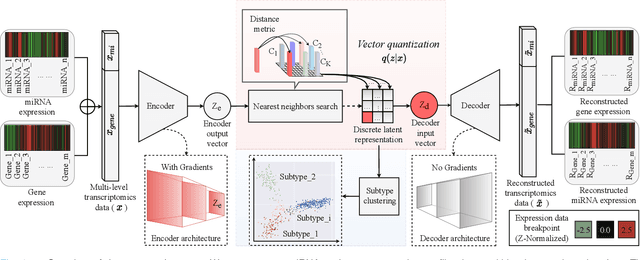
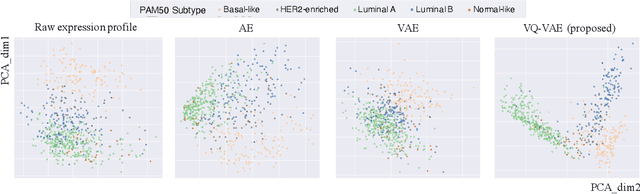
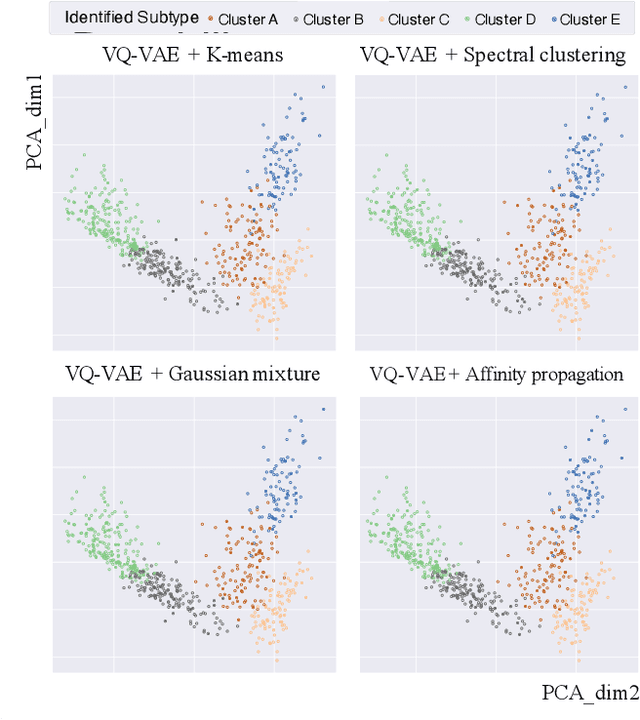
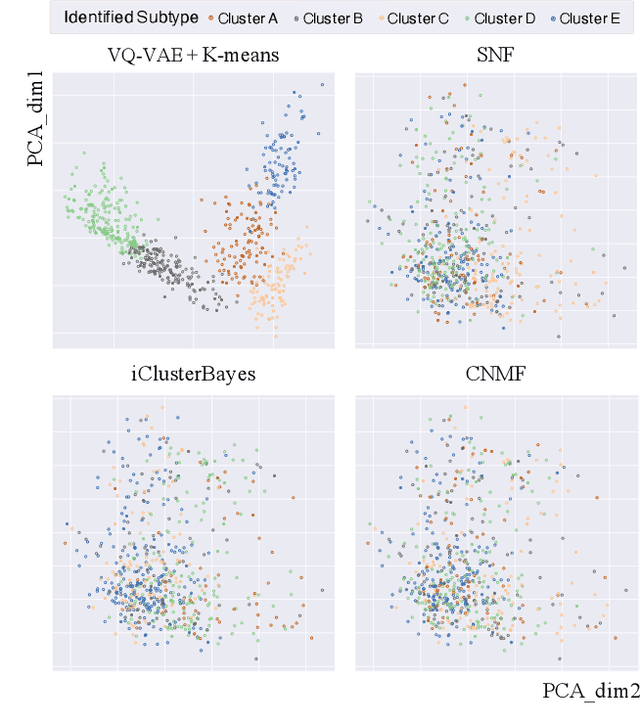
Defining and separating cancer subtypes is essential for facilitating personalized therapy modality and prognosis of patients. The definition of subtypes has been constantly recalibrated as a result of our deepened understanding. During this recalibration, researchers often rely on clustering of cancer data to provide an intuitive visual reference that could reveal the intrinsic characteristics of subtypes. The data being clustered are often omics data such as transcriptomics that have strong correlations to the underlying biological mechanism. However, while existing studies have shown promising results, they suffer from issues associated with omics data: sample scarcity and high dimensionality. As such, existing methods often impose unrealistic assumptions to extract useful features from the data while avoiding overfitting to spurious correlations. In this paper, we propose to leverage a recent strong generative model, Vector Quantized Variational AutoEncoder (VQ-VAE), to tackle the data issues and extract informative latent features that are crucial to the quality of subsequent clustering by retaining only information relevant to reconstructing the input. VQ-VAE does not impose strict assumptions and hence its latent features are better representations of the input, capable of yielding superior clustering performance with any mainstream clustering method. Extensive experiments and medical analysis on multiple datasets comprising 10 distinct cancers demonstrate the VQ-VAE clustering results can significantly and robustly improve prognosis over prevalent subtyping systems.