 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridged SBI: Correcting Biased Low-Fidelity Posteriors for Cost-Efficient High-Fidelity Inference
Jun 08, 2026Accurate calibration of particle-based simulators is crucial for robotic earthwork simulation, but analytical calibration is challenging due to this task's highly nonlinear particle dynamics and the black-box nature of conventional simulators. Although simulation-based inference (SBI) can estimate posterior distributions over simulation parameters solely from forward simulations, applying SBI directly to high-fidelity (HF) particle simulators is often computationally prohibitive. Low-fidelity (LF) simulators with coarser particles can reduce this cost, but changes in particle size and particle count shift the parameter values needed to reproduce the same observation, producing biased LF posteriors. We propose Bridged SBI, which leverages a biased but informative LF posterior to guide HF inference. This method first uses inexpensive LF simulations to identify a coarse high-density parameter region, and then it learns a local residual bridge to transport LF posterior samples toward HF-consistent regions by correcting the LF--HF discrepancy. We analyze how sequential multi-fidelity SBI (Naive-MF) can suffer from LF-induced posterior miscoverage when it directly relies on the LF posterior without discrepancy correction. We then show that Bridged SBI is designed to alleviate this issue by explicitly modeling the LF--HF discrepancy through residual correction. Experiments on both sim-to-sim particle-parameter calibration and real-to-sim calibration with real soil observation show that Bridged SBI produces more accurate and reliable HF posteriors than HF-only SBI or the Naive-MF baseline, especially under limited HF simulation costs.
Autonomous Obstacle Removal for Excavators through Policy Learning with Particle Simulation
Jun 08, 2026Autonomous obstacle removal from the ground is an important earthwork task, but this is difficult to automate because an excavator must adapt its excavation trajectories over repeated cycles as soil-obstacle conditions change. Learning such state-dependent behavior requires a training environment that reproduces accumulated soil-obstacle interactions, including contact states, terrain deformation, and obstacle visibility. Accordingly, particle-based simulation is suitable for the relevant policy learning. However, particle simulation is computationally expensive, and repeated excavation cycles further increase the learning cost. We observe that the burial condition of an obstacle governs both task difficulty and simulation cost: deeper burial makes obstacle removal harder while also requiring more particles for accurate simulation. This observation motivates a burial-conditioned curriculum learning strategy. We propose a time-efficient sim-to-real policy learning framework in which the policy observes terrain and obstacle information from RGB-D measurements and then outputs a parameterized excavation trajectory; in this process, the simulator reproduces in a real-world excavator the same observation-action interface it uses under controllable burial conditions. The curriculum begins with shallow burial conditions and progressively increases burial depth while adjusting particle count, thus simultaneously controlling task difficulty and simulation cost. Experiments show that the proposed framework successfully learns an effective obstacle-removal policy, whereas baseline methods fail even after a full week of training. The proposed curriculum achieves effective performance within three days and achieves successful transfer to a real 12-ton excavator operating on open ground with various steel obstacles, thus demonstrating robust obstacle removal.
ViSA: Visited-State Augmentation for Generalized Goal-Space Contrastive Reinforcement Learning
Mar 16, 2026Goal-Conditioned Reinforcement Learning (GCRL) is a framework for learning a policy that can reach arbitrarily given goals. In particular, Contrastive Reinforcement Learning (CRL) provides a framework for policy updates using an approximation of the value function estimated via contrastive learning, achieving higher sample efficiency compared to conventional methods. However, since CRL treats the visited state as a pseudo-goal during learning, it can accurately estimate the value function only for limited goals. To address this issue, we propose a novel data augmentation approach for CRL called ViSA (Visited-State Augmentation). ViSA consists of two components: 1) generating augmented state samples, with the aim of augmenting hard-to-visit state samples during on-policy exploration, and 2) learning consistent embedding space, which uses an augmented state as auxiliary information to regularize the embedding space by reformulating the objective function of the embedding space based on mutual information. We evaluate ViSA in simulation and real-world robotic tasks and show improved goal-space generalization, which permits accurate value estimation for hard-to-visit goals. Further details can be found on the project page: \href{https://issa-n.github.io/projectPage_ViSA/}{\texttt{https://issa-n.github.io/projectPage\_ViSA/}}
Robust Sim-to-Real Cloth Untangling through Reduced-Resolution Observations via Adaptive Force-Difference Quantization
Mar 14, 2026Robotic cloth untangling requires progressively disentangling fabric by adapting pulling actions to changing contact and tension conditions. Because large-scale real-world training is impractical due to cloth damage and hardware wear, sim-to-real policy transfer is a promising solution. However, cloth manipulation is highly sensitive to interaction dynamics, and policies that depend on precise force magnitudes often fail after transfer because similar force responses cannot be reproduced due to the reality gap. We observe that untangling is largely characterized by qualitative tension transitions rather than exact force values. This indicates that directly minimizing the sim-to-real gap in raw force measurements does not necessarily align with the task structure. We therefore hypothesize that emphasizing coarse force-change patterns while suppressing fine environment-dependent variations can improve robustness of sim-to-real transfer. Based on this insight, we propose Adaptive Force-Difference Quantization (ADQ), which reduces observation resolution by representing force inputs as discretized temporal differences and learning state-dependent quantization thresholds adaptively. This representation mitigates overfitting to environment-specific force characteristics and facilitates direct sim-to-real transfer. Experiments in both simulation and real-world cloth untangling demonstrate that ADQ achieves higher success rates and exhibits greater robustness in sim-to-real transfer than policies using raw force inputs. Supplementary video is available at https://youtu.be/ZeoBs-t0AWc
DeReCo: Decoupling Representation and Coordination Learning for Object-Adaptive Decentralized Multi-Robot Cooperative Transport
Mar 09, 2026Generalizing decentralized multi-robot cooperative transport across objects with diverse shapes and physical properties remains a fundamental challenge. Under decentralized execution, two key challenges arise: object-dependent representation learning under partial observability and coordination learning in multi-agent reinforcement learning (MARL) under non-stationarity. A typical approach jointly optimizes object-dependent representations and coordinated policies in an end-to-end manner while randomizing object shapes and physical properties during training. However, this joint optimization tightly couples representation and coordination learning, introducing bidirectional interference: inaccurate representations under partial observability destabilize coordination learning, while non-stationarity in MARL further degrades representation learning, resulting in sample-inefficient training. To address this structural coupling, we propose DeReCo, a novel MARL framework that decouples representation and coordination learning for object-adaptive multi-robot cooperative transport, improving sample efficiency and generalization across objects and transport scenarios. DeReCo adopts a three-stage training strategy: (1) centralized coordination learning with privileged object information, (2) reconstruction of object-dependent representations from local observations, and (3) progressive removal of privileged information for decentralized execution. This decoupling mitigates interference between representation and coordination learning and enables stable and sample-efficient training. Experimental results show that DeReCo outperforms baselines in simulation on three training objects, generalizes to six unseen objects with varying masses and friction coefficients, and achieves superior performance on two unseen objects in real-robot experiments.
Prolonging Tool Life: Learning Skillful Use of General-purpose Tools through Lifespan-guided Reinforcement Learning
Jul 23, 2025



In inaccessible environments with uncertain task demands, robots often rely on general-purpose tools that lack predefined usage strategies. These tools are not tailored for particular operations, making their longevity highly sensitive to how they are used. This creates a fundamental challenge: how can a robot learn a tool-use policy that both completes the task and prolongs the tool's lifespan? In this work, we address this challenge by introducing a reinforcement learning (RL) framework that incorporates tool lifespan as a factor during policy optimization. Our framework leverages Finite Element Analysis (FEA) and Miner's Rule to estimate Remaining Useful Life (RUL) based on accumulated stress, and integrates the RUL into the RL reward to guide policy learning toward lifespan-guided behavior. To handle the fact that RUL can only be estimated after task execution, we introduce an Adaptive Reward Normalization (ARN) mechanism that dynamically adjusts reward scaling based on estimated RULs, ensuring stable learning signals. We validate our method across simulated and real-world tool use tasks, including Object-Moving and Door-Opening with multiple general-purpose tools. The learned policies consistently prolong tool lifespan (up to 8.01x in simulation) and transfer effectively to real-world settings, demonstrating the practical value of learning lifespan-guided tool use strategies.
DAPPER: Discriminability-Aware Policy-to-Policy Preference-Based Reinforcement Learning for Query-Efficient Robot Skill Acquisition
May 09, 2025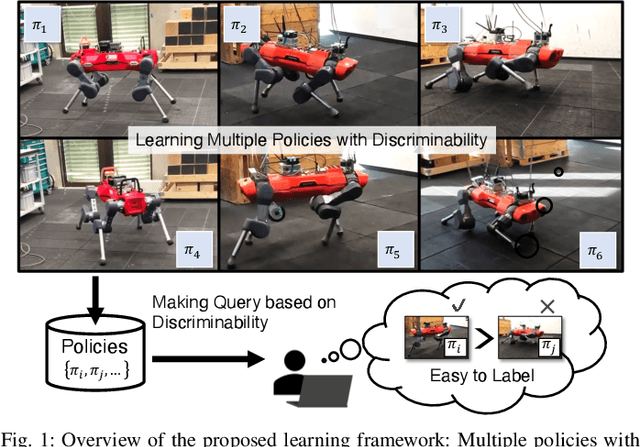
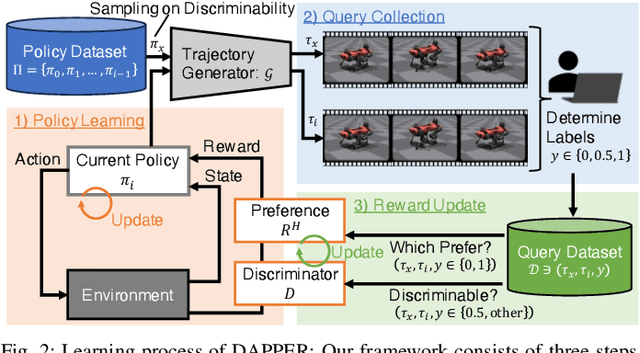

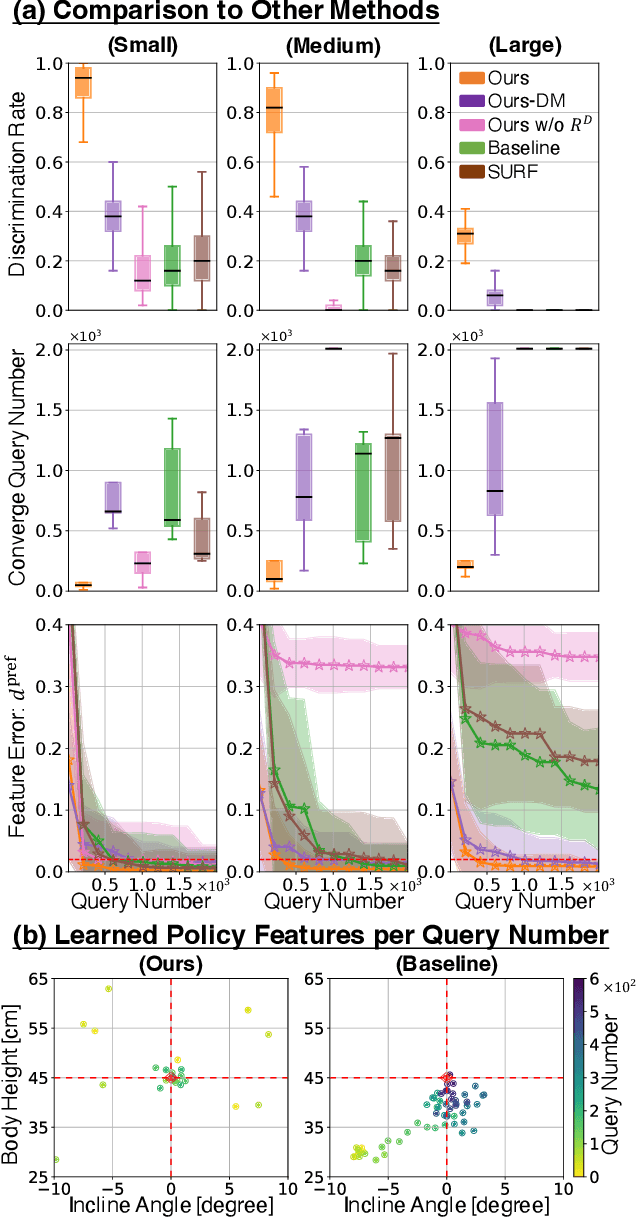
Preference-based Reinforcement Learning (PbRL) enables policy learning through simple queries comparing trajectories from a single policy. While human responses to these queries make it possible to learn policies aligned with human preferences, PbRL suffers from low query efficiency, as policy bias limits trajectory diversity and reduces the number of discriminable queries available for learning preferences. This paper identifies preference discriminability, which quantifies how easily a human can judge which trajectory is closer to their ideal behavior, as a key metric for improving query efficiency. To address this, we move beyond comparisons within a single policy and instead generate queries by comparing trajectories from multiple policies, as training them from scratch promotes diversity without policy bias. We propose Discriminability-Aware Policy-to-Policy Preference-Based Efficient Reinforcement Learning (DAPPER), which integrates preference discriminability with trajectory diversification achieved by multiple policies. DAPPER trains new policies from scratch after each reward update and employs a discriminator that learns to estimate preference discriminability, enabling the prioritized sampling of more discriminable queries. During training, it jointly maximizes the preference reward and preference discriminability score, encouraging the discovery of highly rewarding and easily distinguishable policies. Experiments in simulated and real-world legged robot environments demonstrate that DAPPER outperforms previous methods in query efficiency, particularly under challenging preference discriminability conditions.
Progressive-Resolution Policy Distillation: Leveraging Coarse-Resolution Simulation for Time-Efficient Fine-Resolution Policy Learning
Dec 10, 2024



In earthwork and construction, excavators often encounter large rocks mixed with various soil conditions, requiring skilled operators. This paper presents a framework for achieving autonomous excavation using reinforcement learning (RL) through a rock excavation simulator. In the simulation, resolution can be defined by the particle size/number in the whole soil space. Fine-resolution simulations closely mimic real-world behavior but demand significant calculation time and challenging sample collection, while coarse-resolution simulations enable faster sample collection but deviate from real-world behavior. To combine the advantages of both resolutions, we explore using policies developed in coarse-resolution simulations for pre-training in fine-resolution simulations. To this end, we propose a novel policy learning framework called Progressive-Resolution Policy Distillation (PRPD), which progressively transfers policies through some middle-resolution simulations with conservative policy transfer to avoid domain gaps that could lead to policy transfer failure. Validation in a rock excavation simulator and nine real-world rock environments demonstrated that PRPD reduced sampling time to less than 1/7 while maintaining task success rates comparable to those achieved through policy learning in a fine-resolution simulation.
Robust Iterative Value Conversion: Deep Reinforcement Learning for Neurochip-driven Edge Robots
Aug 23, 2024



A neurochip is a device that reproduces the signal processing mechanisms of brain neurons and calculates Spiking Neural Networks (SNNs) with low power consumption and at high speed. Thus, neurochips are attracting attention from edge robot applications, which suffer from limited battery capacity. This paper aims to achieve deep reinforcement learning (DRL) that acquires SNN policies suitable for neurochip implementation. Since DRL requires a complex function approximation, we focus on conversion techniques from Floating Point NN (FPNN) because it is one of the most feasible SNN techniques. However, DRL requires conversions to SNNs for every policy update to collect the learning samples for a DRL-learning cycle, which updates the FPNN policy and collects the SNN policy samples. Accumulative conversion errors can significantly degrade the performance of the SNN policies. We propose Robust Iterative Value Conversion (RIVC) as a DRL that incorporates conversion error reduction and robustness to conversion errors. To reduce them, FPNN is optimized with the same number of quantization bits as an SNN. The FPNN output is not significantly changed by quantization. To robustify the conversion error, an FPNN policy that is applied with quantization is updated to increase the gap between the probability of selecting the optimal action and other actions. This step prevents unexpected replacements of the policy's optimal actions. We verified RIVC's effectiveness on a neurochip-driven robot. The results showed that RIVC consumed 1/15 times less power and increased the calculation speed by five times more than an edge CPU (quad-core ARM Cortex-A72). The previous framework with no countermeasures against conversion errors failed to train the policies. Videos from our experiments are available: https://youtu.be/Q5Z0-BvK1Tc.
Cyclic Policy Distillation: Sample-Efficient Sim-to-Real Reinforcement Learning with Domain Randomization
Jul 29, 2022
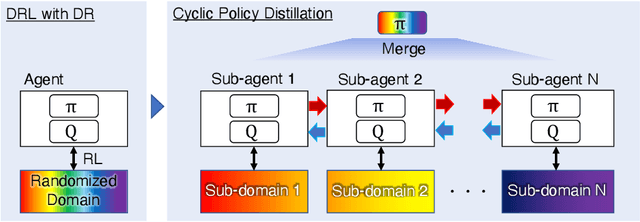

Deep reinforcement learning with domain randomization learns a control policy in various simulations with randomized physical and sensor model parameters to become transferable to the real world in a zero-shot setting. However, a huge number of samples are often required to learn an effective policy when the range of randomized parameters is extensive due to the instability of policy updates. To alleviate this problem, we propose a sample-efficient method named Cyclic Policy Distillation (CPD). CPD divides the range of randomized parameters into several small sub-domains and assigns a local policy to each sub-domain. Then, the learning of local policies is performed while {\it cyclically} transitioning the target sub-domain to neighboring sub-domains and exploiting the learned values/policies of the neighbor sub-domains with a monotonic policy-improvement scheme. Finally, all of the learned local policies are distilled into a global policy for sim-to-real transfer. The effectiveness and sample efficiency of CPD are demonstrated through simulations with four tasks (Pendulum from OpenAIGym and Pusher, Swimmer, and HalfCheetah from Mujoco), and a real-robot ball-dispersal task.