 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyclic Policy Distillation: Sample-Efficient Sim-to-Real Reinforcement Learning with Domain Randomization
Paper and Code

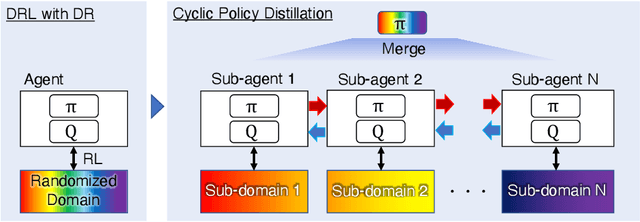

Deep reinforcement learning with domain randomization learns a control policy in various simulations with randomized physical and sensor model parameters to become transferable to the real world in a zero-shot setting. However, a huge number of samples are often required to learn an effective policy when the range of randomized parameters is extensive due to the instability of policy updates. To alleviate this problem, we propose a sample-efficient method named Cyclic Policy Distillation (CPD). CPD divides the range of randomized parameters into several small sub-domains and assigns a local policy to each sub-domain. Then, the learning of local policies is performed while {\it cyclically} transitioning the target sub-domain to neighboring sub-domains and exploiting the learned values/policies of the neighbor sub-domains with a monotonic policy-improvement scheme. Finally, all of the learned local policies are distilled into a global policy for sim-to-real transfer. The effectiveness and sample efficiency of CPD are demonstrated through simulations with four tasks (Pendulum from OpenAIGym and Pusher, Swimmer, and HalfCheetah from Mujoco), and a real-robot ball-dispersal task.