 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Obstacle Removal for Excavators through Policy Learning with Particle Simulation
Jun 08, 2026Autonomous obstacle removal from the ground is an important earthwork task, but this is difficult to automate because an excavator must adapt its excavation trajectories over repeated cycles as soil-obstacle conditions change. Learning such state-dependent behavior requires a training environment that reproduces accumulated soil-obstacle interactions, including contact states, terrain deformation, and obstacle visibility. Accordingly, particle-based simulation is suitable for the relevant policy learning. However, particle simulation is computationally expensive, and repeated excavation cycles further increase the learning cost. We observe that the burial condition of an obstacle governs both task difficulty and simulation cost: deeper burial makes obstacle removal harder while also requiring more particles for accurate simulation. This observation motivates a burial-conditioned curriculum learning strategy. We propose a time-efficient sim-to-real policy learning framework in which the policy observes terrain and obstacle information from RGB-D measurements and then outputs a parameterized excavation trajectory; in this process, the simulator reproduces in a real-world excavator the same observation-action interface it uses under controllable burial conditions. The curriculum begins with shallow burial conditions and progressively increases burial depth while adjusting particle count, thus simultaneously controlling task difficulty and simulation cost. Experiments show that the proposed framework successfully learns an effective obstacle-removal policy, whereas baseline methods fail even after a full week of training. The proposed curriculum achieves effective performance within three days and achieves successful transfer to a real 12-ton excavator operating on open ground with various steel obstacles, thus demonstrating robust obstacle removal.
Bridged SBI: Correcting Biased Low-Fidelity Posteriors for Cost-Efficient High-Fidelity Inference
Jun 08, 2026Accurate calibration of particle-based simulators is crucial for robotic earthwork simulation, but analytical calibration is challenging due to this task's highly nonlinear particle dynamics and the black-box nature of conventional simulators. Although simulation-based inference (SBI) can estimate posterior distributions over simulation parameters solely from forward simulations, applying SBI directly to high-fidelity (HF) particle simulators is often computationally prohibitive. Low-fidelity (LF) simulators with coarser particles can reduce this cost, but changes in particle size and particle count shift the parameter values needed to reproduce the same observation, producing biased LF posteriors. We propose Bridged SBI, which leverages a biased but informative LF posterior to guide HF inference. This method first uses inexpensive LF simulations to identify a coarse high-density parameter region, and then it learns a local residual bridge to transport LF posterior samples toward HF-consistent regions by correcting the LF--HF discrepancy. We analyze how sequential multi-fidelity SBI (Naive-MF) can suffer from LF-induced posterior miscoverage when it directly relies on the LF posterior without discrepancy correction. We then show that Bridged SBI is designed to alleviate this issue by explicitly modeling the LF--HF discrepancy through residual correction. Experiments on both sim-to-sim particle-parameter calibration and real-to-sim calibration with real soil observation show that Bridged SBI produces more accurate and reliable HF posteriors than HF-only SBI or the Naive-MF baseline, especially under limited HF simulation costs.
ViSA: Visited-State Augmentation for Generalized Goal-Space Contrastive Reinforcement Learning
Mar 16, 2026Goal-Conditioned Reinforcement Learning (GCRL) is a framework for learning a policy that can reach arbitrarily given goals. In particular, Contrastive Reinforcement Learning (CRL) provides a framework for policy updates using an approximation of the value function estimated via contrastive learning, achieving higher sample efficiency compared to conventional methods. However, since CRL treats the visited state as a pseudo-goal during learning, it can accurately estimate the value function only for limited goals. To address this issue, we propose a novel data augmentation approach for CRL called ViSA (Visited-State Augmentation). ViSA consists of two components: 1) generating augmented state samples, with the aim of augmenting hard-to-visit state samples during on-policy exploration, and 2) learning consistent embedding space, which uses an augmented state as auxiliary information to regularize the embedding space by reformulating the objective function of the embedding space based on mutual information. We evaluate ViSA in simulation and real-world robotic tasks and show improved goal-space generalization, which permits accurate value estimation for hard-to-visit goals. Further details can be found on the project page: \href{https://issa-n.github.io/projectPage_ViSA/}{\texttt{https://issa-n.github.io/projectPage\_ViSA/}}
Robust Sim-to-Real Cloth Untangling through Reduced-Resolution Observations via Adaptive Force-Difference Quantization
Mar 14, 2026Robotic cloth untangling requires progressively disentangling fabric by adapting pulling actions to changing contact and tension conditions. Because large-scale real-world training is impractical due to cloth damage and hardware wear, sim-to-real policy transfer is a promising solution. However, cloth manipulation is highly sensitive to interaction dynamics, and policies that depend on precise force magnitudes often fail after transfer because similar force responses cannot be reproduced due to the reality gap. We observe that untangling is largely characterized by qualitative tension transitions rather than exact force values. This indicates that directly minimizing the sim-to-real gap in raw force measurements does not necessarily align with the task structure. We therefore hypothesize that emphasizing coarse force-change patterns while suppressing fine environment-dependent variations can improve robustness of sim-to-real transfer. Based on this insight, we propose Adaptive Force-Difference Quantization (ADQ), which reduces observation resolution by representing force inputs as discretized temporal differences and learning state-dependent quantization thresholds adaptively. This representation mitigates overfitting to environment-specific force characteristics and facilitates direct sim-to-real transfer. Experiments in both simulation and real-world cloth untangling demonstrate that ADQ achieves higher success rates and exhibits greater robustness in sim-to-real transfer than policies using raw force inputs. Supplementary video is available at https://youtu.be/ZeoBs-t0AWc
DeReCo: Decoupling Representation and Coordination Learning for Object-Adaptive Decentralized Multi-Robot Cooperative Transport
Mar 09, 2026Generalizing decentralized multi-robot cooperative transport across objects with diverse shapes and physical properties remains a fundamental challenge. Under decentralized execution, two key challenges arise: object-dependent representation learning under partial observability and coordination learning in multi-agent reinforcement learning (MARL) under non-stationarity. A typical approach jointly optimizes object-dependent representations and coordinated policies in an end-to-end manner while randomizing object shapes and physical properties during training. However, this joint optimization tightly couples representation and coordination learning, introducing bidirectional interference: inaccurate representations under partial observability destabilize coordination learning, while non-stationarity in MARL further degrades representation learning, resulting in sample-inefficient training. To address this structural coupling, we propose DeReCo, a novel MARL framework that decouples representation and coordination learning for object-adaptive multi-robot cooperative transport, improving sample efficiency and generalization across objects and transport scenarios. DeReCo adopts a three-stage training strategy: (1) centralized coordination learning with privileged object information, (2) reconstruction of object-dependent representations from local observations, and (3) progressive removal of privileged information for decentralized execution. This decoupling mitigates interference between representation and coordination learning and enables stable and sample-efficient training. Experimental results show that DeReCo outperforms baselines in simulation on three training objects, generalizes to six unseen objects with varying masses and friction coefficients, and achieves superior performance on two unseen objects in real-robot experiments.
Task-Relevant and Irrelevant Region-Aware Augmentation for Generalizable Vision-Based Imitation Learning in Agricultural Manipulation
Mar 05, 2026Vision-based imitation learning has shown promise for robotic manipulation; however, its generalization remains limited in practical agricultural tasks. This limitation stems from scarce demonstration data and substantial visual domain gaps caused by i) crop-specific appearance diversity and ii) background variations. To address this limitation, we propose Dual-Region Augmentation for Imitation Learning (DRAIL), a region-aware augmentation framework designed for generalizable vision-based imitation learning in agricultural manipulation. DRAIL explicitly separates visual observations into task-relevant and task-irrelevant regions. The task-relevant region is augmented in a domain-knowledge-driven manner to preserve essential visual characteristics, while the task-irrelevant region is aggressively randomized to suppress spurious background correlations. By jointly handling both sources of visual variation, DRAIL promotes learning policies that rely on task-essential features rather than incidental visual cues. We evaluate DRAIL on diffusion policy-based visuomotor controllers through robot experiments on artificial vegetable harvesting and real lettuce defective leaf picking preparation tasks. The results show consistent improvements in success rates under unseen visual conditions compared to baseline methods. Further attention analysis and representation generalization metrics indicate that the learned policies rely more on task-essential visual features, resulting in enhanced robustness and generalization.
CoLF: Learning Consistent Leader-Follower Policies for Vision-Language-Guided Multi-Robot Cooperative Transport
Feb 08, 2026In this study, we address vision-language-guided multi-robot cooperative transport, where each robot grounds natural-language instructions from onboard camera observations. A key challenge in this decentralized setting is perceptual misalignment across robots, where viewpoint differences and language ambiguity can yield inconsistent interpretations and degrade cooperative transport. To mitigate this problem, we adopt a dependent leader-follower design, where one robot serves as the leader and the other as the follower. Although such a leader-follower structure appears straightforward, learning with independent and symmetric agents often yields symmetric or unstable behaviors without explicit inductive biases. To address this challenge, we propose Consistent Leader-Follower (CoLF), a multi-agent reinforcement learning (MARL) framework for stable leader-follower role differentiation. CoLF consists of two key components: (1) an asymmetric policy design that induces leader-follower role differentiation, and (2) a mutual-information-based training objective that maximizes a variational lower bound, encouraging the follower to predict the leader's action from its local observation. The leader and follower policies are jointly optimized under the centralized training and decentralized execution (CTDE) framework to balance task execution and consistent cooperative behaviors. We validate CoLF in both simulation and real-robot experiments using two quadruped robots. The demonstration video is available at https://sites.google.com/view/colf/.
DISF: Disentangled Iterative Surface Fitting for Contact-stable Grasp Planning with Grasp Pose Alignment to the Object Center of Mass
Dec 31, 2025In this work, we address the limitation of surface fitting-based grasp planning algorithm, which primarily focuses on geometric alignment between the gripper and object surface while overlooking the stability of contact point distribution, often resulting in unstable grasps due to inadequate contact configurations. To overcome this limitation, we propose a novel surface fitting algorithm that integrates contact stability while preserving geometric compatibility. Inspired by human grasping behavior, our method disentangles the grasp pose optimization into three sequential steps: (1) rotation optimization to align contact normals, (2) translation refinement to improve the alignment between the gripper frame origin and the object Center of Mass (CoM), and (3) gripper aperture adjustment to optimize contact point distribution. We validate our approach in simulation across 15 objects under both Known-shape (with clean CAD-derived dataset) and Observed-shape (with YCB object dataset) settings, including cross-platform grasp execution on three robot--gripper platforms. We further validate the method in real-world grasp experiments on a UR3e robot. Overall, DISF reduces CoM misalignment while maintaining geometric compatibility, translating into higher grasp success in both simulation and real-world execution compared to baselines. Additional videos and supplementary results are available on our project page: https://tomoya-yamanokuchi.github.io/disf-ras-project-page/
Tracing Energy Flow: Learning Tactile-based Grasping Force Control to Prevent Slippage in Dynamic Object Interaction
Dec 24, 2025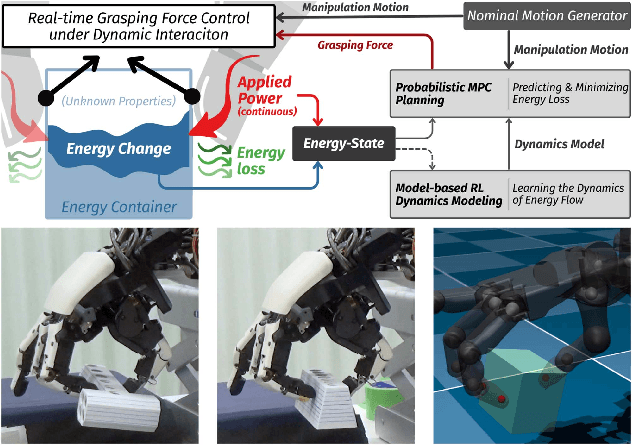
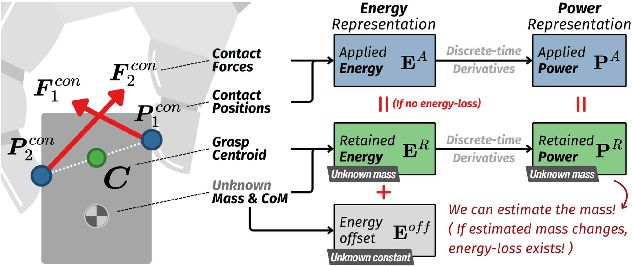
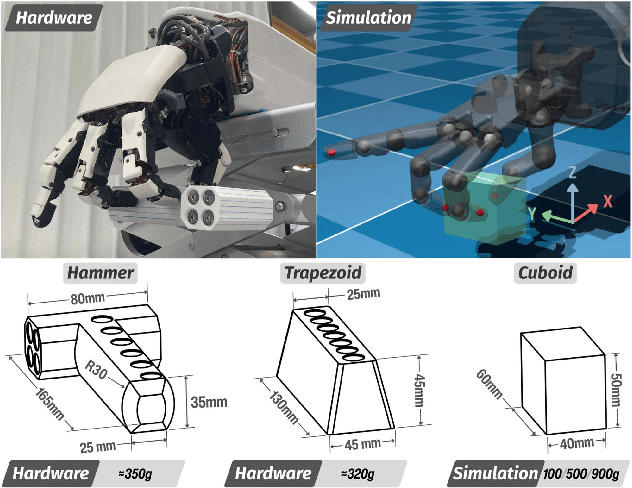
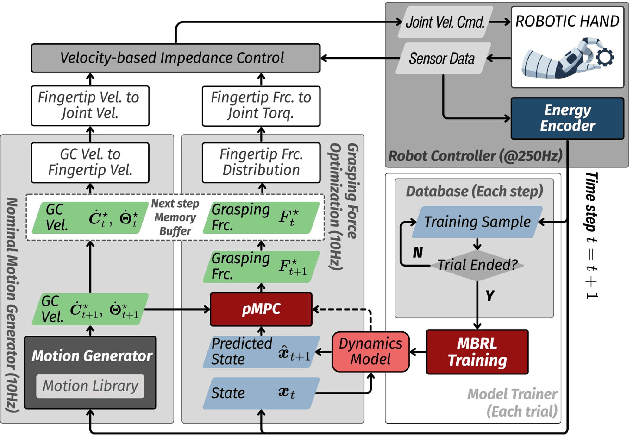
Regulating grasping force to reduce slippage during dynamic object interaction remains a fundamental challenge in robotic manipulation, especially when objects are manipulated by multiple rolling contacts, have unknown properties (such as mass or surface conditions), and when external sensing is unreliable. In contrast, humans can quickly regulate grasping force by touch, even without visual cues. Inspired by this ability, we aim to enable robotic hands to rapidly explore objects and learn tactile-driven grasping force control under motion and limited sensing. We propose a physics-informed energy abstraction that models the object as a virtual energy container. The inconsistency between the fingers' applied power and the object's retained energy provides a physically grounded signal for inferring slip-aware stability. Building on this abstraction, we employ model-based learning and planning to efficiently model energy dynamics from tactile sensing and perform real-time grasping force optimization. Experiments in both simulation and hardware demonstrate that our method can learn grasping force control from scratch within minutes, effectively reduce slippage, and extend grasp duration across diverse motion-object pairs, all without relying on external sensing or prior object knowledge.
DIPP: Discriminative Impact Point Predictor for Catching Diverse In-Flight Objects
Sep 18, 2025
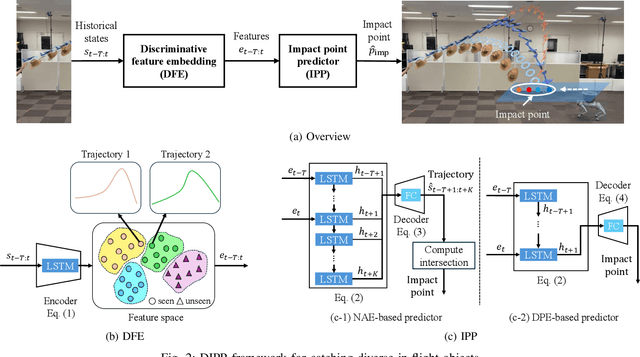

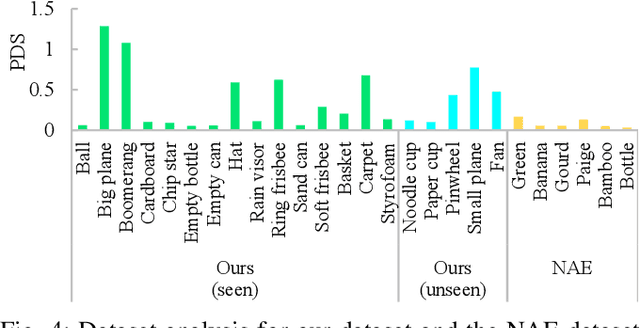
In this study, we address the problem of in-flight object catching using a quadruped robot with a basket. Our objective is to accurately predict the impact point, defined as the object's landing position. This task poses two key challenges: the absence of public datasets capturing diverse objects under unsteady aerodynamics, which are essential for training reliable predictors; and the difficulty of accurate early-stage impact point prediction when trajectories appear similar across objects. To overcome these issues, we construct a real-world dataset of 8,000 trajectories from 20 objects, providing a foundation for advancing in-flight object catching under complex aerodynamics. We then propose the Discriminative Impact Point Predictor (DIPP), consisting of two modules: (i) a Discriminative Feature Embedding (DFE) that separates trajectories by dynamics to enable early-stage discrimination and generalization, and (ii) an Impact Point Predictor (IPP) that estimates the impact point from these features. Two IPP variants are implemented: an Neural Acceleration Estimator (NAE)-based method that predicts trajectories and derives the impact point, and a Direct Point Estimator (DPE)-based method that directly outputs it. Experimental results show that our dataset is more diverse and complex than existing dataset, and that our method outperforms baselines on both 15 seen and 5 unseen objects. Furthermore, we show that improved early-stage prediction enhances catching success in simulation and demonstrate the effectiveness of our approach through real-world experiments. The demonstration is available at https://sites.google.com/view/robot-catching-2025.