 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyMPs: One-Shot Vision-Language Guided Motion Generation by Sequencing DMPs for Occlusion-Rich Tasks
Apr 14, 2025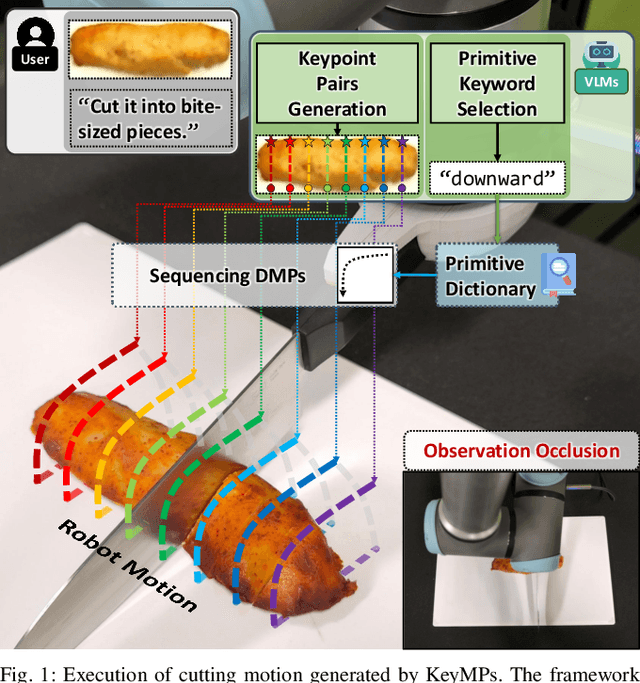
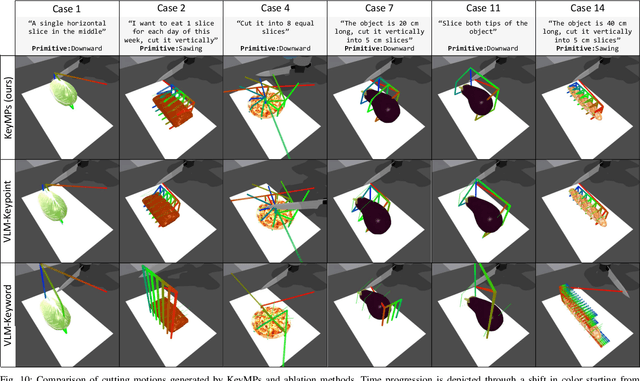
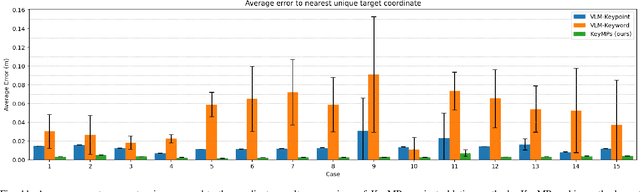
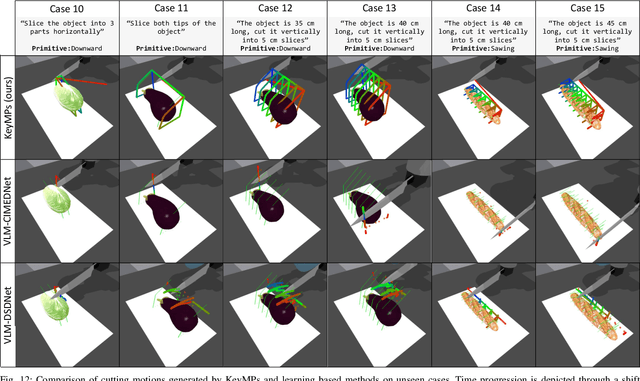
Dynamic Movement Primitives (DMPs) provide a flexible framework wherein smooth robotic motions are encoded into modular parameters. However, they face challenges in integrating multimodal inputs commonly used in robotics like vision and language into their framework. To fully maximize DMPs' potential, enabling them to handle multimodal inputs is essential. In addition, we also aim to extend DMPs' capability to handle object-focused tasks requiring one-shot complex motion generation, as observation occlusion could easily happen mid-execution in such tasks (e.g., knife occlusion in cake icing, hand occlusion in dough kneading, etc.). A promising approach is to leverage Vision-Language Models (VLMs), which process multimodal data and can grasp high-level concepts. However, they typically lack enough knowledge and capabilities to directly infer low-level motion details and instead only serve as a bridge between high-level instructions and low-level control. To address this limitation, we propose Keyword Labeled Primitive Selection and Keypoint Pairs Generation Guided Movement Primitives (KeyMPs), a framework that combines VLMs with sequencing of DMPs. KeyMPs use VLMs' high-level reasoning capability to select a reference primitive through keyword labeled primitive selection and VLMs' spatial awareness to generate spatial scaling parameters used for sequencing DMPs by generalizing the overall motion through keypoint pairs generation, which together enable one-shot vision-language guided motion generation that aligns with the intent expressed in the multimodal input. We validate our approach through an occlusion-rich manipulation task, specifically object cutting experiments in both simulated and real-world environments, demonstrating superior performance over other DMP-based methods that integrate VLMs support.
EgoOops: A Dataset for Mistake Action Detection from Egocentric Videos with Procedural Texts
Oct 07, 2024


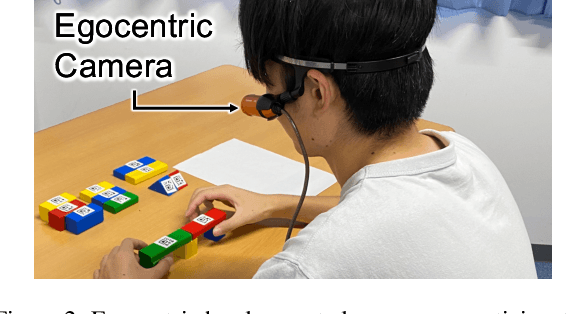
Mistake action detection from egocentric videos is crucial for developing intelligent archives that detect workers' errors and provide feedback. Previous studies have been limited to specific domains, focused on detecting mistakes from videos without procedural texts, and analyzed whether actions are mistakes. To address these limitations, in this paper, we propose the EgoOops dataset, which includes egocentric videos, procedural texts, and three types of annotations: video-text alignment, mistake labels, and descriptions for mistakes. EgoOops covers five procedural domains and includes 50 egocentric videos. The video-text alignment allows the model to detect mistakes based on both videos and procedural texts. The mistake labels and descriptions enable detailed analysis of real-world mistakes. Based on EgoOops, we tackle two tasks: video-text alignment and mistake detection. For video-text alignment, we enhance the recent StepFormer model with an additional loss for fine-tuning. Based on the alignment results, we propose a multi-modal classifier to predict mistake labels. In our experiments, the proposed methods achieve higher performance than the baselines. In addition, our ablation study demonstrates the effectiveness of combining videos and texts. We will release the dataset and codes upon publication.
Automatic Construction of a Large-Scale Corpus for Geoparsing Using Wikipedia Hyperlinks
Mar 25, 2024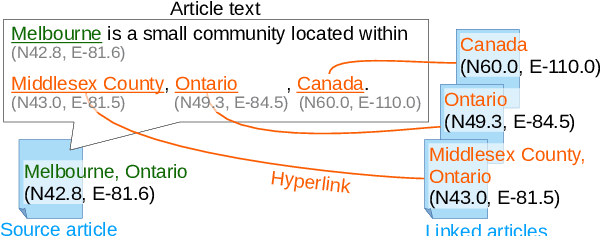
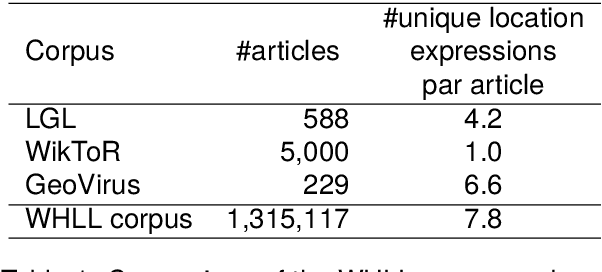

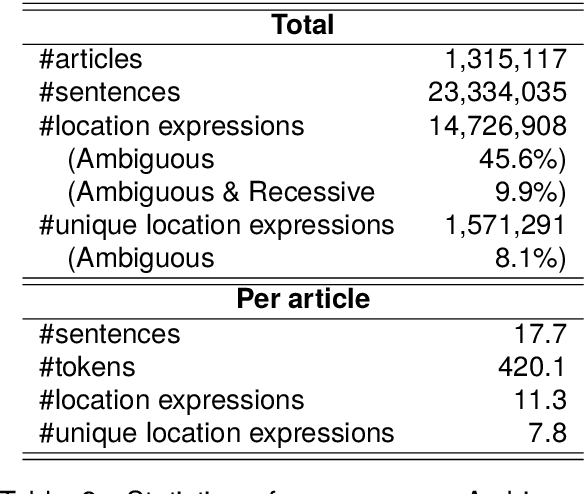
Geoparsing is the task of estimating the latitude and longitude (coordinates) of location expressions in texts. Geoparsing must deal with the ambiguity of the expressions that indicate multiple locations with the same notation. For evaluating geoparsing systems, several corpora have been proposed in previous work. However, these corpora are small-scale and suffer from the coverage of location expressions on general domains. In this paper, we propose Wikipedia Hyperlink-based Location Linking (WHLL), a novel method to construct a large-scale corpus for geoparsing from Wikipedia articles. WHLL leverages hyperlinks in Wikipedia to annotate multiple location expressions with coordinates. With this method, we constructed the WHLL corpus, a new large-scale corpus for geoparsing. The WHLL corpus consists of 1.3M articles, each containing about 7.8 unique location expressions. 45.6% of location expressions are ambiguous and refer to more than one location with the same notation. In each article, location expressions of the article title and those hyperlinks to other articles are assigned with coordinates. By utilizing hyperlinks, we can accurately assign location expressions with coordinates even with ambiguous location expressions in the texts. Experimental results show that there remains room for improvement by disambiguating location expressions.
Vision-Language Interpreter for Robot Task Planning
Nov 02, 2023



Large language models (LLMs) are accelerating the development of language-guided robot planners. Meanwhile, symbolic planners offer the advantage of interpretability. This paper proposes a new task that bridges these two trends, namely, multimodal planning problem specification. The aim is to generate a problem description (PD), a machine-readable file used by the planners to find a plan. By generating PDs from language instruction and scene observation, we can drive symbolic planners in a language-guided framework. We propose a Vision-Language Interpreter (ViLaIn), a new framework that generates PDs using state-of-the-art LLM and vision-language models. ViLaIn can refine generated PDs via error message feedback from the symbolic planner. Our aim is to answer the question: How accurately can ViLaIn and the symbolic planner generate valid robot plans? To evaluate ViLaIn, we introduce a novel dataset called the problem description generation (ProDG) dataset. The framework is evaluated with four new evaluation metrics. Experimental results show that ViLaIn can generate syntactically correct problems with more than 99% accuracy and valid plans with more than 58% accuracy.
Towards Flow Graph Prediction of Open-Domain Procedural Texts
May 31, 2023Machine comprehension of procedural texts is essential for reasoning about the steps and automating the procedures. However, this requires identifying entities within a text and resolving the relationships between the entities. Previous work focused on the cooking domain and proposed a framework to convert a recipe text into a flow graph (FG) representation. In this work, we propose a framework based on the recipe FG for flow graph prediction of open-domain procedural texts. To investigate flow graph prediction performance in non-cooking domains, we introduce the wikiHow-FG corpus from articles on wikiHow, a website of how-to instruction articles. In experiments, we consider using the existing recipe corpus and performing domain adaptation from the cooking to the target domain. Experimental results show that the domain adaptation models achieve higher performance than those trained only on the cooking or target domain data.
Visual Recipe Flow: A Dataset for Learning Visual State Changes of Objects with Recipe Flows
Sep 13, 2022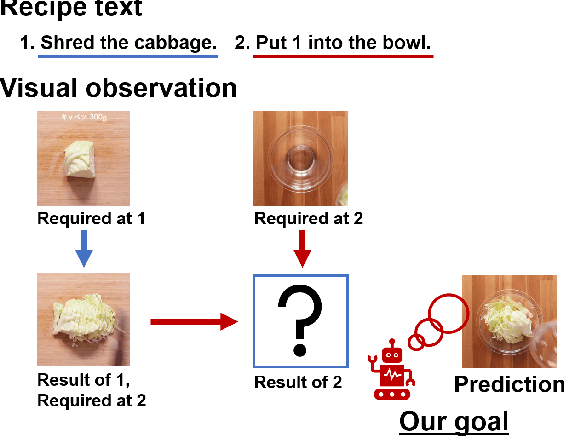

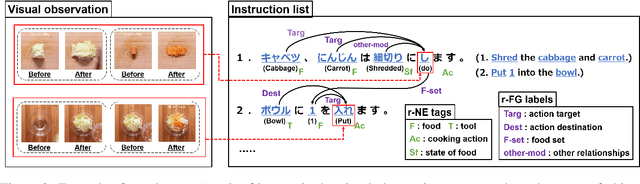
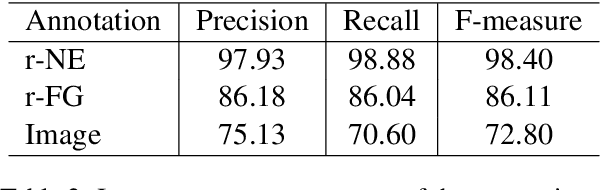
We present a new multimodal dataset called Visual Recipe Flow, which enables us to learn each cooking action result in a recipe text. The dataset consists of object state changes and the workflow of the recipe text. The state change is represented as an image pair, while the workflow is represented as a recipe flow graph (r-FG). The image pairs are grounded in the r-FG, which provides the cross-modal relation. With our dataset, one can try a range of applications, from multimodal commonsense reasoning and procedural text generation.
Neural Text Generation with Artificial Negative Examples
Dec 28, 2020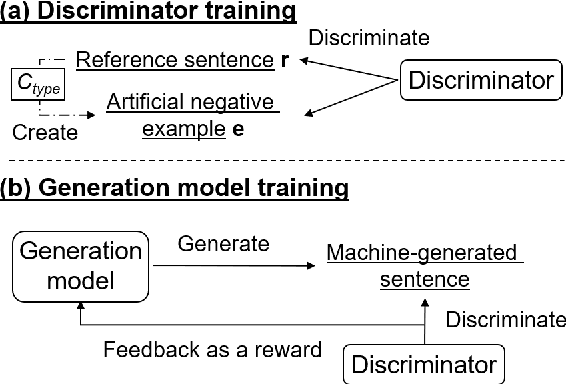



Neural text generation models conditioning on given input (e.g. machine translation and image captioning) are usually trained by maximum likelihood estimation of target text. However, the trained models suffer from various types of errors at inference time. In this paper, we propose to suppress an arbitrary type of errors by training the text generation model in a reinforcement learning framework, where we use a trainable reward function that is capable of discriminating between references and sentences containing the targeted type of errors. We create such negative examples by artificially injecting the targeted errors to the references. In experiments, we focus on two error types, repeated and dropped tokens in model-generated text. The experimental results show that our method can suppress the generation errors and achieve significant improvements on two machine translation and two image captioning tasks.