 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable In-hand Manipulation for a Lightweight Four-motor Prosthetic Hand
Jan 12, 2026Electric prosthetic hands should be lightweight to decrease the burden on the user, shaped like human hands for cosmetic purposes, and designed with motors enclosed inside to protect them from damage and dirt. Additionally, in-hand manipulation is necessary to perform daily activities such as transitioning between different postures, particularly through rotational movements, such as reorienting a pen into a writing posture after picking it up from a desk. We previously developed PLEXUS hand (Precision-Lateral dEXteroUS manipulation hand), a lightweight (311 g) prosthetic hand driven by four motors. This prosthetic performed reorientation between precision and lateral grasps with various objects. However, its controller required predefined object widths and was limited to handling lightweight objects (of weight up to 34 g). This study addresses these limitations by employing motor current feedback. Combined with the hand's previously optimized single-axis thumb, this approach achieves more stable manipulation by estimating the object's width and adjusting the index finger position to maintain stable object holding during the reorientation. Experimental validation using primitive objects of various widths (5-30 mm) and shapes (cylinders and prisms) resulted in a 100% success rate with lightweight objects and maintained a high success rate (>=80) even with heavy aluminum prisms (of weight up to 289 g). By contrast, the performance without index finger coordination dropped to just 40% on the heaviest 289 g prism. The hand also successfully executed several daily tasks, including closing bottle caps and orienting a pen for writing.
SCU-Hand: Soft Conical Universal Robotic Hand for Scooping Granular Media from Containers of Various Sizes
May 07, 2025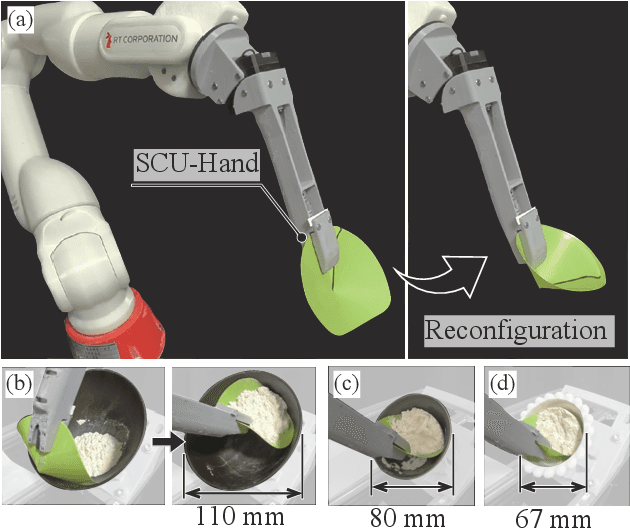
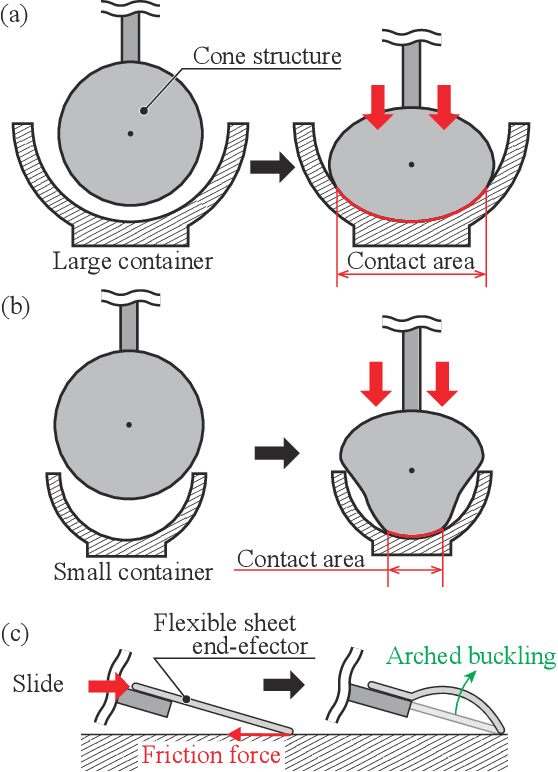
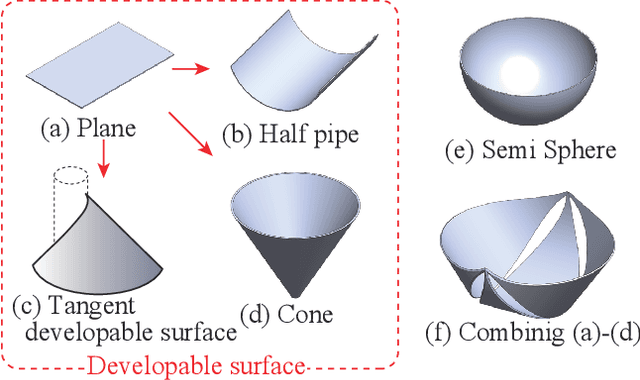
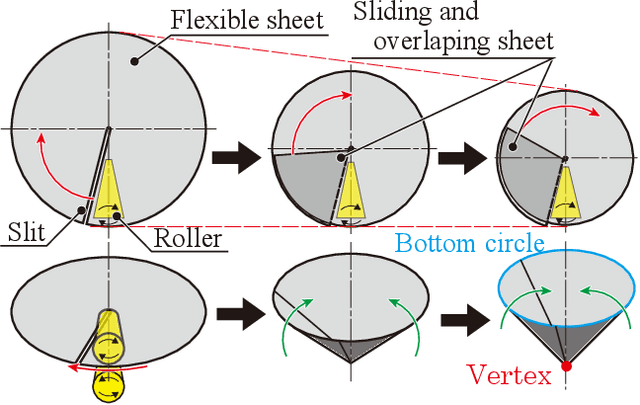
Automating small-scale experiments in materials science presents challenges due to the heterogeneous nature of experimental setups. This study introduces the SCU-Hand (Soft Conical Universal Robot Hand), a novel end-effector designed to automate the task of scooping powdered samples from various container sizes using a robotic arm. The SCU-Hand employs a flexible, conical structure that adapts to different container geometries through deformation, maintaining consistent contact without complex force sensing or machine learning-based control methods. Its reconfigurable mechanism allows for size adjustment, enabling efficient scooping from diverse container types. By combining soft robotics principles with a sheet-morphing design, our end-effector achieves high flexibility while retaining the necessary stiffness for effective powder manipulation. We detail the design principles, fabrication process, and experimental validation of the SCU-Hand. Experimental validation showed that the scooping capacity is about 20% higher than that of a commercial tool, with a scooping performance of more than 95% for containers of sizes between 67 mm to 110 mm. This research contributes to laboratory automation by offering a cost-effective, easily implementable solution for automating tasks such as materials synthesis and characterization processes.
System 0/1/2/3: Quad-process theory for multi-timescale embodied collective cognitive systems
Mar 08, 2025



This paper introduces the System 0/1/2/3 framework as an extension of dual-process theory, employing a quad-process model of cognition. Expanding upon System 1 (fast, intuitive thinking) and System 2 (slow, deliberative thinking), we incorporate System 0, which represents pre-cognitive embodied processes, and System 3, which encompasses collective intelligence and symbol emergence. We contextualize this model within Bergson's philosophy by adopting multi-scale time theory to unify the diverse temporal dynamics of cognition. System 0 emphasizes morphological computation and passive dynamics, illustrating how physical embodiment enables adaptive behavior without explicit neural processing. Systems 1 and 2 are explained from a constructive perspective, incorporating neurodynamical and AI viewpoints. In System 3, we introduce collective predictive coding to explain how societal-level adaptation and symbol emergence operate over extended timescales. This comprehensive framework ranges from rapid embodied reactions to slow-evolving collective intelligence, offering a unified perspective on cognition across multiple timescales, levels of abstraction, and forms of human intelligence. The System 0/1/2/3 model provides a novel theoretical foundation for understanding the interplay between adaptive and cognitive processes, thereby opening new avenues for research in cognitive science, AI, robotics, and collective intelligence.
Visuo-Tactile Zero-Shot Object Recognition with Vision-Language Model
Sep 14, 2024
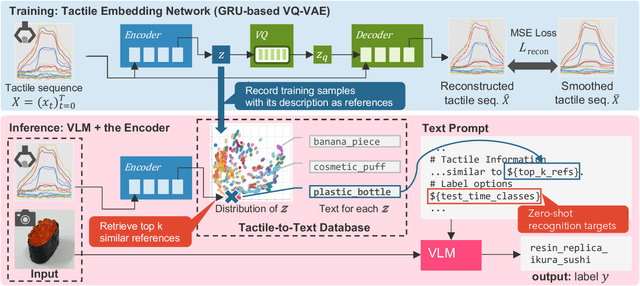
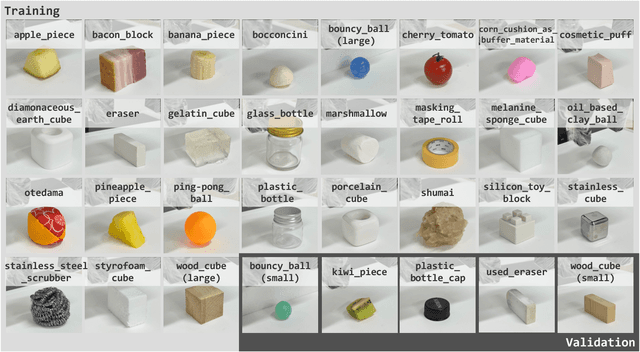
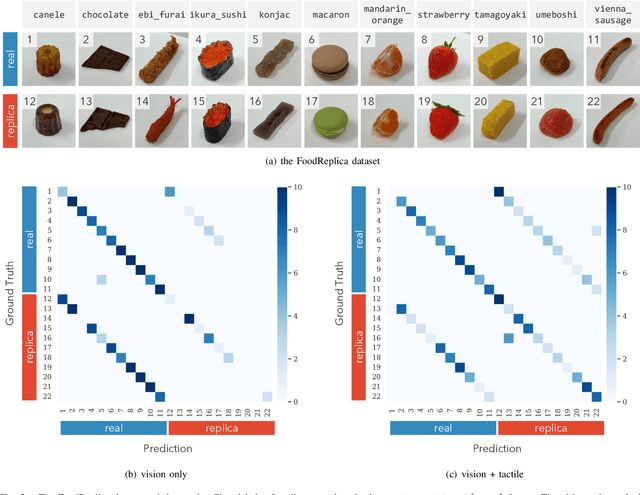
Tactile perception is vital, especially when distinguishing visually similar objects. We propose an approach to incorporate tactile data into a Vision-Language Model (VLM) for visuo-tactile zero-shot object recognition. Our approach leverages the zero-shot capability of VLMs to infer tactile properties from the names of tactilely similar objects. The proposed method translates tactile data into a textual description solely by annotating object names for each tactile sequence during training, making it adaptable to various contexts with low training costs. The proposed method was evaluated on the FoodReplica and Cube datasets, demonstrating its effectiveness in recognizing objects that are difficult to distinguish by vision alone.
Swarm Body: Embodied Swarm Robots
Mar 01, 2024
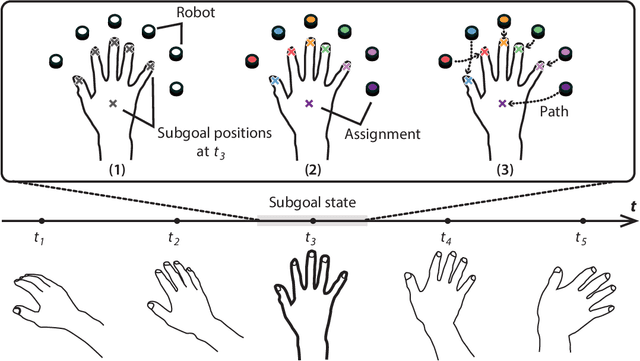

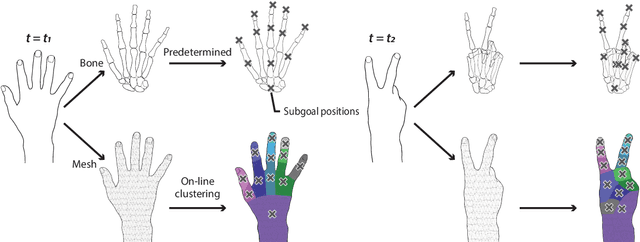
The human brain's plasticity allows for the integration of artificial body parts into the human body. Leveraging this, embodied systems realize intuitive interactions with the environment. We introduce a novel concept: embodied swarm robots. Swarm robots constitute a collective of robots working in harmony to achieve a common objective, in our case, serving as functional body parts. Embodied swarm robots can dynamically alter their shape, density, and the correspondences between body parts and individual robots. We contribute an investigation of the influence on embodiment of swarm robot-specific factors derived from these characteristics, focusing on a hand. Our paper is the first to examine these factors through virtual reality (VR) and real-world robot studies to provide essential design considerations and applications of embodied swarm robots. Through quantitative and qualitative analysis, we identified a system configuration to achieve the embodiment of swarm robots.
Vision-Language Interpreter for Robot Task Planning
Nov 02, 2023



Large language models (LLMs) are accelerating the development of language-guided robot planners. Meanwhile, symbolic planners offer the advantage of interpretability. This paper proposes a new task that bridges these two trends, namely, multimodal planning problem specification. The aim is to generate a problem description (PD), a machine-readable file used by the planners to find a plan. By generating PDs from language instruction and scene observation, we can drive symbolic planners in a language-guided framework. We propose a Vision-Language Interpreter (ViLaIn), a new framework that generates PDs using state-of-the-art LLM and vision-language models. ViLaIn can refine generated PDs via error message feedback from the symbolic planner. Our aim is to answer the question: How accurately can ViLaIn and the symbolic planner generate valid robot plans? To evaluate ViLaIn, we introduce a novel dataset called the problem description generation (ProDG) dataset. The framework is evaluated with four new evaluation metrics. Experimental results show that ViLaIn can generate syntactically correct problems with more than 99% accuracy and valid plans with more than 58% accuracy.
Quasistatic contact-rich manipulation via linear complementarity quadratic programming
Oct 25, 2022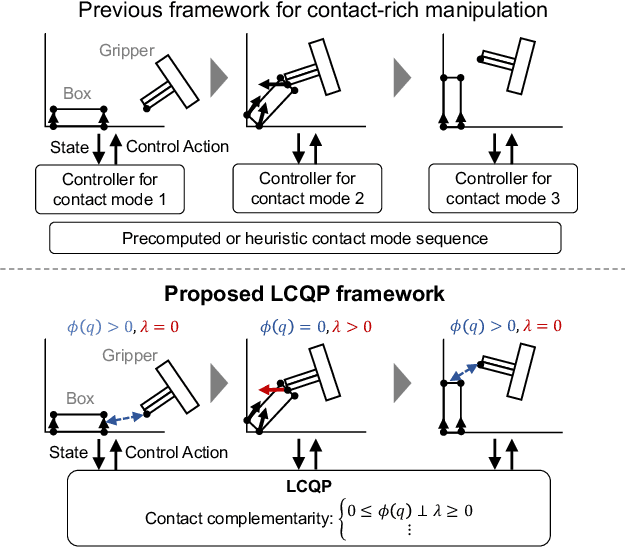
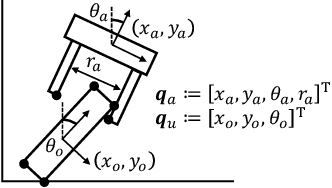
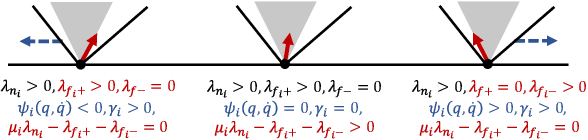
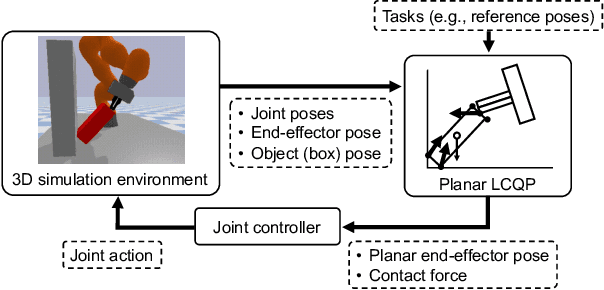
Contact-rich manipulation is challenging due to dynamically-changing physical constraints by the contact mode changes undergone during manipulation. This paper proposes a versatile local planning and control framework for contact-rich manipulation that determines the continuous control action under variable contact modes online. We model the physical characteristics of contact-rich manipulation by quasistatic dynamics and complementarity constraints. We then propose a linear complementarity quadratic program (LCQP) to efficiently determine the control action that implicitly includes the decisions on the contact modes under these constraints. In the LCQP, we relax the complementarity constraints to alleviate ill-conditioned problems that are typically caused by measure noises or model miss-matches. We conduct dynamical simulations on a 3D physical simulator and demonstrate that the proposed method can achieve various contact-rich manipulation tasks by determining the control action including the contact modes in real-time.
An analytical diabolo model for robotic learning and control
Nov 18, 2020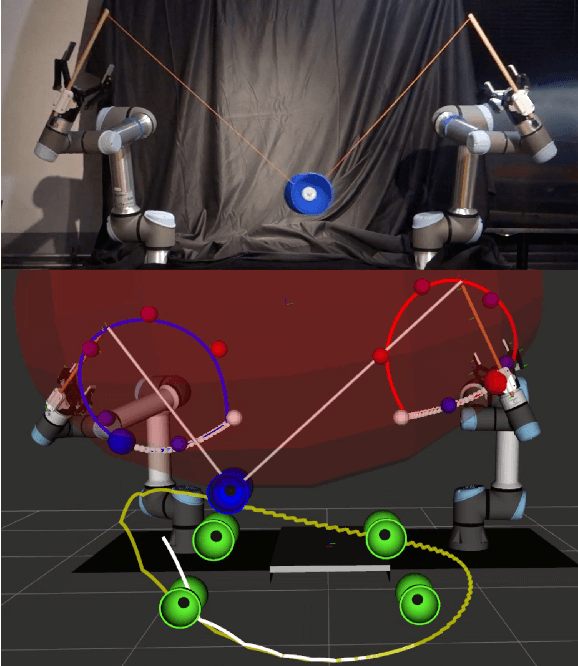

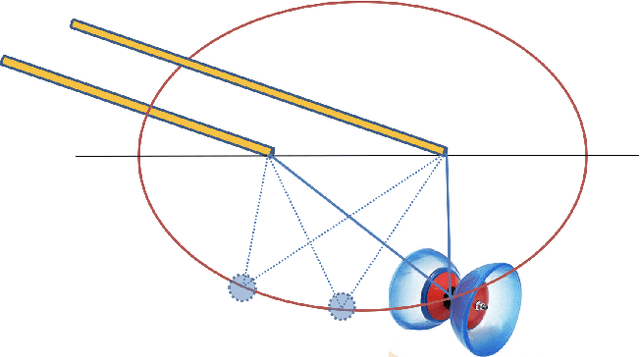
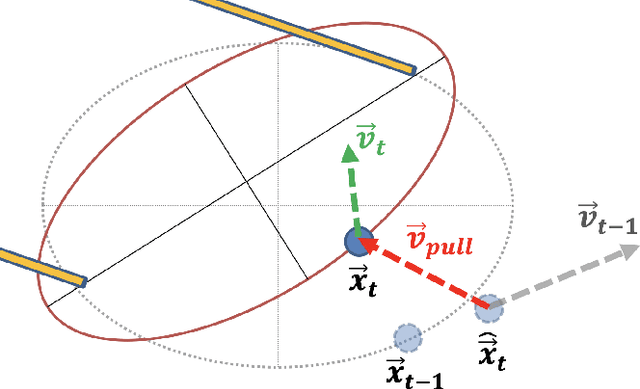
In this paper, we present a diabolo model that can be used for training agents in simulation to play diabolo, as well as running it on a real dual robot arm system. We first derive an analytical model of the diabolo-string system and compare its accuracy using data recorded via motion capture, which we release as a public dataset of skilled play with diabolos of different dynamics. We show that our model outperforms a deep-learning-based predictor, both in terms of precision and physically consistent behavior. Next, we describe a method based on optimal control to generate robot trajectories that produce the desired diabolo trajectory, as well as a system to transform higher-level actions into robot motions. Finally, we test our method on a real robot system by playing the diabolo, and throwing it to and catching it from a human player.
Switching Isotropic and Directional Exploration with Parameter Space Noise in Deep Reinforcement Learning
Sep 27, 2018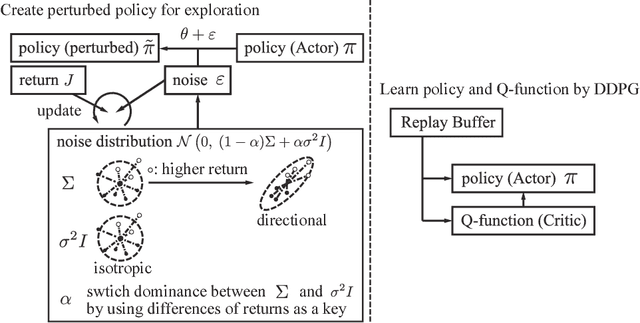
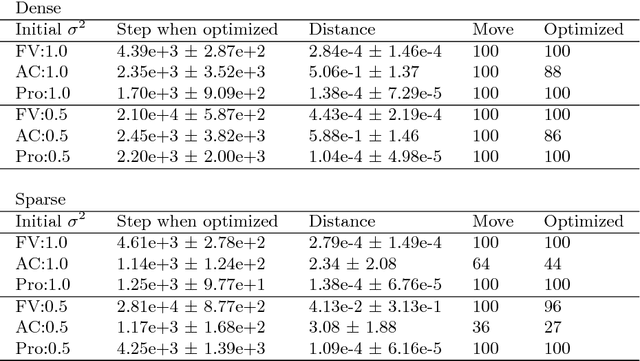
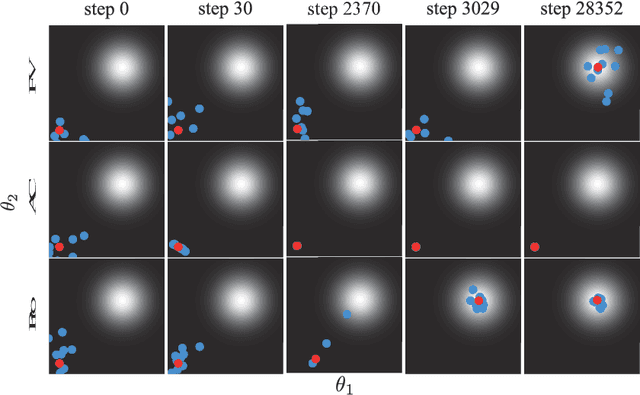
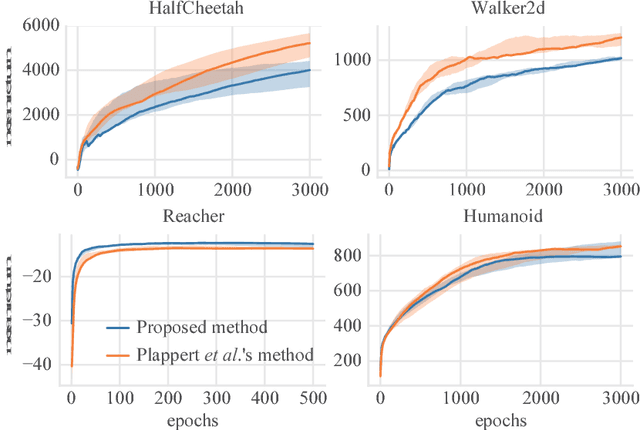
This paper proposes an exploration method for deep reinforcement learning based on parameter space noise. Recent studies have experimentally shown that parameter space noise results in better exploration than the commonly used action space noise. Previous methods devised a way to update the diagonal covariance matrix of a noise distribution and did not consider the direction of the noise vector and its correlation. In addition, fast updates of the noise distribution are required to facilitate policy learning. We propose a method that deforms the noise distribution according to the accumulated returns and the noises that have led to the returns. Moreover, this method switches isotropic exploration and directional exploration in parameter space with regard to obtained rewards. We validate our exploration strategy in the OpenAI Gym continuous environments and modified environments with sparse rewards. The proposed method achieves results that are competitive with a previous method at baseline tasks. Moreover, our approach exhibits better performance in sparse reward environments by exploration with the switching strategy.