 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExternal Photoreflective Tactile Sensing Based on Surface Deformation Measurement
Nov 09, 2025We present a tactile sensing method enabled by the mechanical compliance of soft robots; an externally attachable photoreflective module reads surface deformation of silicone skin to estimate contact force without embedding tactile transducers. Locating the sensor off the contact interface reduces damage risk, preserves softness, and simplifies fabrication and maintenance. We first characterize the optical sensing element and the compliant skin, thendetermine the design of a prototype tactile sensor. Compression experiments validate the approach, exhibiting a monotonic force output relationship consistent with theory, low hysteresis, high repeatability over repeated cycles, and small response indentation speeds. We further demonstrate integration on a soft robotic gripper, where the module reliably detects grasp events. Compared with liquid filled or wireembedded tactile skins, the proposed modular add on architecture enhances durability, reduces wiring complexity, and supports straightforward deployment across diverse robot geometries. Because the sensing principle reads skin strain patterns, it also suggests extensions to other somatosensory cues such as joint angle or actuator state estimation from surface deformation. Overall, leveraging surface compliance with an external optical module provides a practical and robust route to equip soft robots with force perception while preserving structural flexibility and manufacturability, paving the way for robotic applications and safe human robot collaboration.
Correspondence of high-dimensional emotion structures elicited by video clips between humans and Multimodal LLMs
May 19, 2025Recent studies have revealed that human emotions exhibit a high-dimensional, complex structure. A full capturing of this complexity requires new approaches, as conventional models that disregard high dimensionality risk overlooking key nuances of human emotions. Here, we examined the extent to which the latest generation of rapidly evolving Multimodal Large Language Models (MLLMs) capture these high-dimensional, intricate emotion structures, including capabilities and limitations. Specifically, we compared self-reported emotion ratings from participants watching videos with model-generated estimates (e.g., Gemini or GPT). We evaluated performance not only at the individual video level but also from emotion structures that account for inter-video relationships. At the level of simple correlation between emotion structures, our results demonstrated strong similarity between human and model-inferred emotion structures. To further explore whether the similarity between humans and models is at the signle item level or the coarse-categorical level, we applied Gromov Wasserstein Optimal Transport. We found that although performance was not necessarily high at the strict, single-item level, performance across video categories that elicit similar emotions was substantial, indicating that the model could infer human emotional experiences at the category level. Our results suggest that current state-of-the-art MLLMs broadly capture the complex high-dimensional emotion structures at the category level, as well as their apparent limitations in accurately capturing entire structures at the single-item level.
Decentralized Collective World Model for Emergent Communication and Coordination
Apr 04, 2025



We propose a fully decentralized multi-agent world model that enables both symbol emergence for communication and coordinated behavior through temporal extension of collective predictive coding. Unlike previous research that focuses on either communication or coordination separately, our approach achieves both simultaneously. Our method integrates world models with communication channels, enabling agents to predict environmental dynamics, estimate states from partial observations, and share critical information through bidirectional message exchange with contrastive learning for message alignment. Using a two-agent trajectory drawing task, we demonstrate that our communication-based approach outperforms non-communicative models when agents have divergent perceptual capabilities, achieving the second-best coordination after centralized models. Importantly, our distributed approach with constraints preventing direct access to other agents' internal states facilitates the emergence of more meaningful symbol systems that accurately reflect environmental states. These findings demonstrate the effectiveness of decentralized communication for supporting coordination while developing shared representations of the environment.
System 0/1/2/3: Quad-process theory for multi-timescale embodied collective cognitive systems
Mar 08, 2025



This paper introduces the System 0/1/2/3 framework as an extension of dual-process theory, employing a quad-process model of cognition. Expanding upon System 1 (fast, intuitive thinking) and System 2 (slow, deliberative thinking), we incorporate System 0, which represents pre-cognitive embodied processes, and System 3, which encompasses collective intelligence and symbol emergence. We contextualize this model within Bergson's philosophy by adopting multi-scale time theory to unify the diverse temporal dynamics of cognition. System 0 emphasizes morphological computation and passive dynamics, illustrating how physical embodiment enables adaptive behavior without explicit neural processing. Systems 1 and 2 are explained from a constructive perspective, incorporating neurodynamical and AI viewpoints. In System 3, we introduce collective predictive coding to explain how societal-level adaptation and symbol emergence operate over extended timescales. This comprehensive framework ranges from rapid embodied reactions to slow-evolving collective intelligence, offering a unified perspective on cognition across multiple timescales, levels of abstraction, and forms of human intelligence. The System 0/1/2/3 model provides a novel theoretical foundation for understanding the interplay between adaptive and cognitive processes, thereby opening new avenues for research in cognitive science, AI, robotics, and collective intelligence.
Creative Agents: Simulating the Systems Model of Creativity with Generative Agents
Nov 26, 2024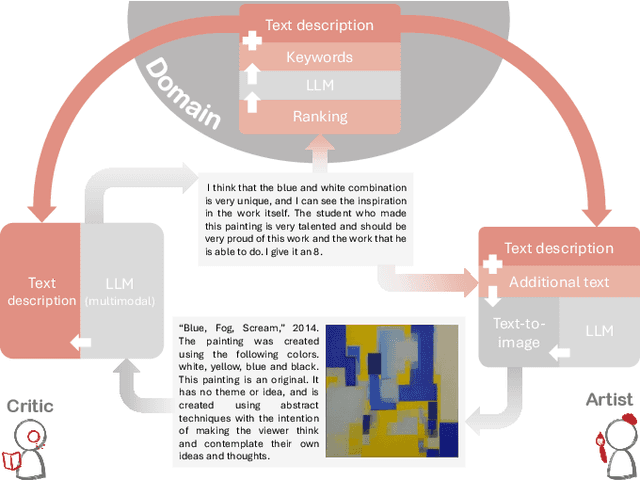
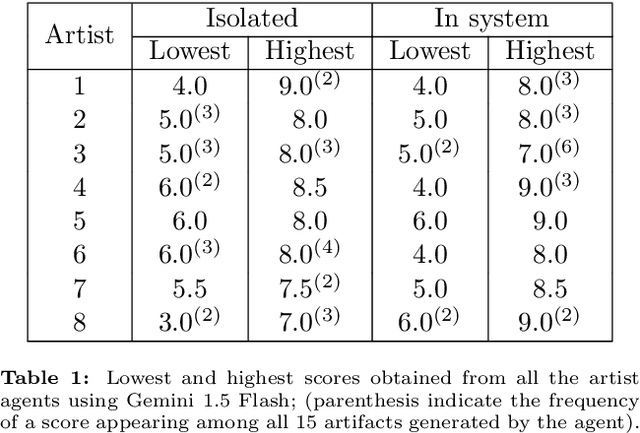
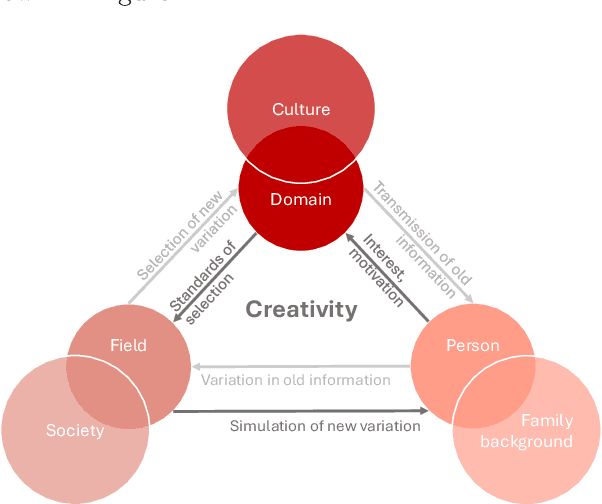
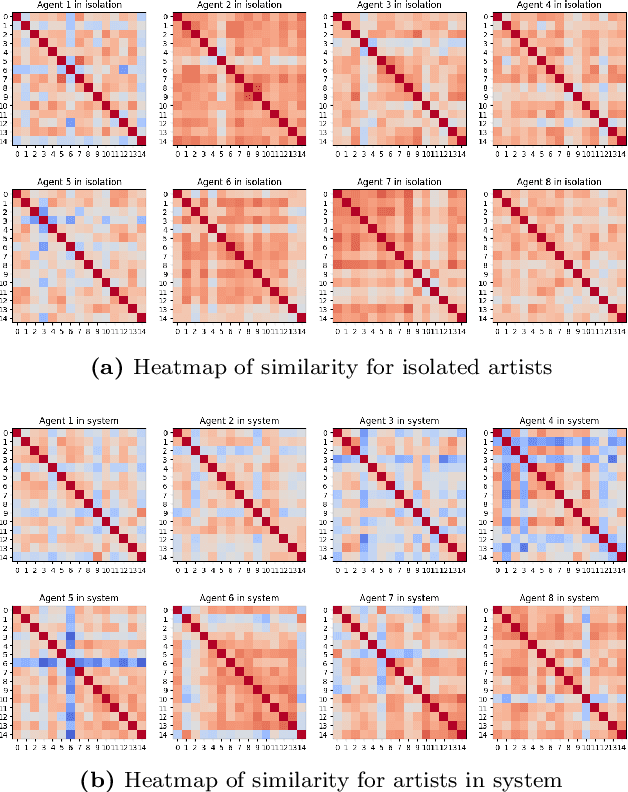
With the growing popularity of generative AI for images, video, and music, we witnessed models rapidly improve in quality and performance. However, not much attention is paid towards enabling AI's ability to "be creative". In this study, we implemented and simulated the systems model of creativity (proposed by Csikszentmihalyi) using virtual agents utilizing large language models (LLMs) and text prompts. For comparison, the simulations were conducted with the "virtual artists" being: 1)isolated and 2)placed in a multi-agent system. Both scenarios were compared by analyzing the variations and overall "creativity" in the generated artifacts (measured via a user study and LLM). Our results suggest that the generative agents may perform better in the framework of the systems model of creativity.
LiP-LLM: Integrating Linear Programming and dependency graph with Large Language Models for multi-robot task planning
Oct 28, 2024



This study proposes LiP-LLM: integrating linear programming and dependency graph with large language models (LLMs) for multi-robot task planning. In order for multiple robots to perform tasks more efficiently, it is necessary to manage the precedence dependencies between tasks. Although multi-robot decentralized and centralized task planners using LLMs have been proposed, none of these studies focus on precedence dependencies from the perspective of task efficiency or leverage traditional optimization methods. It addresses key challenges in managing dependencies between skills and optimizing task allocation. LiP-LLM consists of three steps: skill list generation and dependency graph generation by LLMs, and task allocation using linear programming. The LLMs are utilized to generate a comprehensive list of skills and to construct a dependency graph that maps the relationships and sequential constraints among these skills. To ensure the feasibility and efficiency of skill execution, the skill list is generated by calculated likelihood, and linear programming is used to optimally allocate tasks to each robot. Experimental evaluations in simulated environments demonstrate that this method outperforms existing task planners, achieving higher success rates and efficiency in executing complex, multi-robot tasks. The results indicate the potential of combining LLMs with optimization techniques to enhance the capabilities of multi-robot systems in executing coordinated tasks accurately and efficiently. In an environment with two robots, a maximum success rate difference of 0.82 is observed in the language instruction group with a change in the object name.
Predictive Reachability for Embodiment Selection in Mobile Manipulation Behaviors
Oct 28, 2024



Mobile manipulators require coordinated control between navigation and manipulation to accomplish tasks. Typically, coordinated mobile manipulation behaviors have base navigation to approach the goal followed by arm manipulation to reach the desired pose. Selecting the embodiment between the base and arm can be determined based on reachability. Previous methods evaluate reachability by computing inverse kinematics and activate arm motions once solutions are identified. In this study, we introduce a new approach called predictive reachability that decides reachability based on predicted arm motions. Our model utilizes a hierarchical policy framework built upon a world model. The world model allows the prediction of future trajectories and the evaluation of reachability. The hierarchical policy selects the embodiment based on the predicted reachability and plans accordingly. Unlike methods that require prior knowledge about robots and environments for inverse kinematics, our method only relies on image-based observations. We evaluate our approach through basic reaching tasks across various environments. The results demonstrate that our method outperforms previous model-based approaches in both sample efficiency and performance, while enabling more reasonable embodiment selection based on predictive reachability.
Constructive Approach to Bidirectional Causation between Qualia Structure and Language Emergence
Sep 14, 2024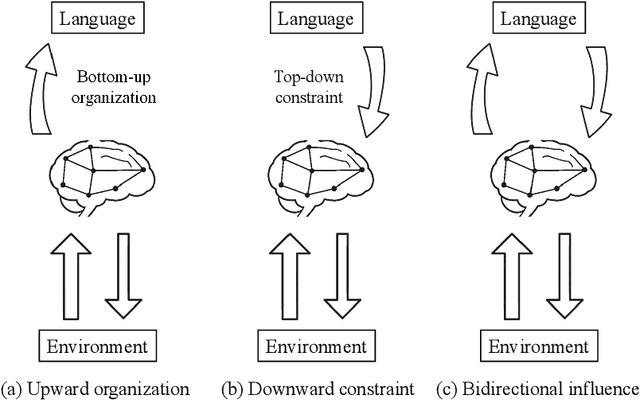

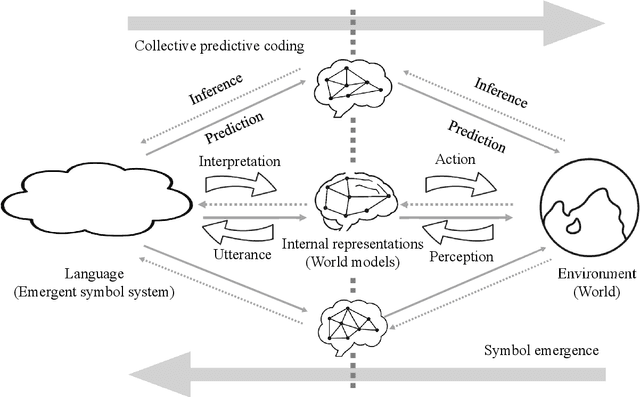
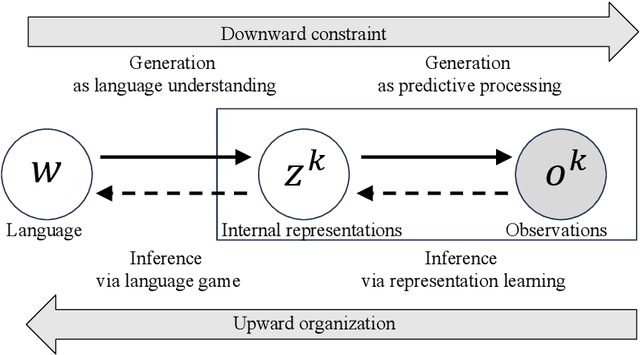
This paper presents a novel perspective on the bidirectional causation between language emergence and relational structure of subjective experiences, termed qualia structure, and lays out the constructive approach to the intricate dependency between the two. We hypothesize that languages with distributional semantics, e.g., syntactic-semantic structures, may have emerged through the process of aligning internal representations among individuals, and such alignment of internal representations facilitates more structured language. This mutual dependency is suggested by the recent advancements in AI and symbol emergence robotics, and collective predictive coding (CPC) hypothesis, in particular. Computational studies show that neural network-based language models form systematically structured internal representations, and multimodal language models can share representations between language and perceptual information. This perspective suggests that language emergence serves not only as a mechanism creating a communication tool but also as a mechanism for allowing people to realize shared understanding of qualitative experiences. The paper discusses the implications of this bidirectional causation in the context of consciousness studies, linguistics, and cognitive science, and outlines future constructive research directions to further explore this dynamic relationship between language emergence and qualia structure.
Goal Estimation-based Adaptive Shared Control for Brain-Machine Interfaces Remote Robot Navigation
Jul 25, 2024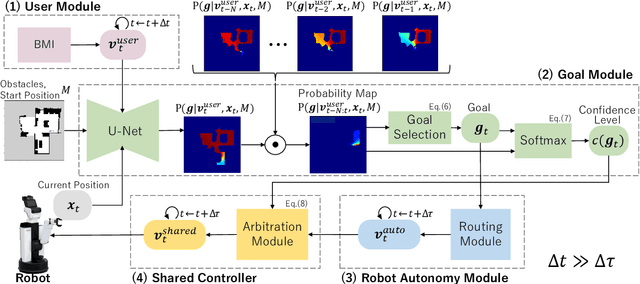
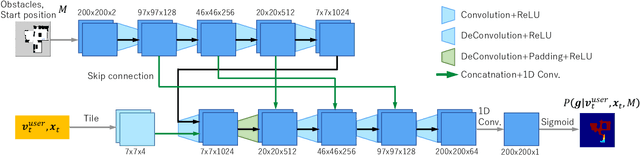
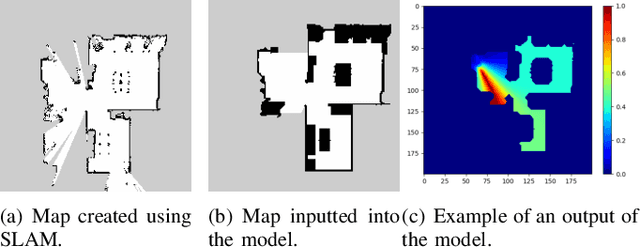

In this study, we propose a shared control method for teleoperated mobile robots using brain-machine interfaces (BMI). The control commands generated through BMI for robot operation face issues of low input frequency, discreteness, and uncertainty due to noise. To address these challenges, our method estimates the user's intended goal from their commands and uses this goal to generate auxiliary commands through the autonomous system that are both at a higher input frequency and more continuous. Furthermore, by defining the confidence level of the estimation, we adaptively calculated the weights for combining user and autonomous commands, thus achieving shared control.
Data-Efficient Approach to Humanoid Control via Fine-Tuning a Pre-Trained GPT on Action Data
May 29, 2024



There are several challenges in developing a model for multi-tasking humanoid control. Reinforcement learning and imitation learning approaches are quite popular in this domain. However, there is a trade-off between the two. Reinforcement learning is not the best option for training a humanoid to perform multiple behaviors due to training time and model size, and imitation learning using kinematics data alone is not appropriate to realize the actual physics of the motion. Training models to perform multiple complex tasks take long training time due to high DoF and complexities of the movements. Although training models offline would be beneficial, another issue is the size of the dataset, usually being quite large to encapsulate multiple movements. Many papers have implemented state of the art deep learning models such as transformers to control humanoid characters and predict their motion based on a large dataset of recorded/reference motion. In this paper, we train a GPT on a large dataset of noisy expert policy rollout observations from a humanoid motion dataset as a pre-trained model and fine tune that model on a smaller dataset of noisy expert policy rollout observations and actions to autoregressively generate physically plausible motion trajectories. We show that it is possible to train a GPT-based foundation model on a smaller dataset in shorter training time to control a humanoid in a realistic physics environment to perform human-like movements.