 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Mental Workload through On-Demand Human Assistance for Physical Action Failures in LLM-based Multi-Robot Coordination
Mar 30, 2026Multi-robot coordination based on large language models (LLMs) has attracted growing attention, since LLMs enable the direct translation of natural language instructions into robot action plans by decomposing tasks and generating high-level plans. However, recovering from physical execution failures remains difficult, and tasks often stagnate due to the repetition of the same unsuccessful actions. While frameworks for remote robot operation using Mixed Reality were proposed, there have been few attempts to implement remote error resolution specifically for physical failures in multi-robot environments. In this study, we propose REPAIR (Robot Execution with Planned And Interactive Recovery), a human-in-the-loop framework that integrates remote error resolution into LLM-based multi-robot planning. In this method, robots execute tasks autonomously; however, when an irrecoverable failure occurs, the LLM requests assistance from an operator, enabling task continuity through remote intervention. Evaluations using a multi-robot trash collection task in a real-world environment confirmed that REPAIR significantly improves task progress (the number of items cleared within a time limit) compared to fully autonomous methods. Furthermore, for easily collectable items, it achieved task progress equivalent to full remote control. The results also suggested that the mental workload on the operator may differ in terms of physical demand and effort. The project website is https://emergentsystemlabstudent.github.io/REPAIR/.
EasyControlEdge: A Foundation-Model Fine-Tuning for Edge Detection
Feb 18, 2026We propose EasyControlEdge, adapting an image-generation foundation model to edge detection. In real-world edge detection (e.g., floor-plan walls, satellite roads/buildings, and medical organ boundaries), crispness and data efficiency are crucial, yet producing crisp raw edge maps with limited training samples remains challenging. Although image-generation foundation models perform well on many downstream tasks, their pretrained priors for data-efficient transfer and iterative refinement for high-frequency detail preservation remain underexploited for edge detection. To enable crisp and data-efficient edge detection using these capabilities, we introduce an edge-specialized adaptation of image-generation foundation models. To better specialize the foundation model for edge detection, we incorporate an edge-oriented objective with an efficient pixel-space loss. At inference, we introduce guidance based on unconditional dynamics, enabling a single model to control the edge density through a guidance scale. Experiments on BSDS500, NYUDv2, BIPED, and CubiCasa compare against state-of-the-art methods and show consistent gains, particularly under no-post-processing crispness evaluation and with limited training data.
Toward Ownership Understanding of Objects: Active Question Generation with Large Language Model and Probabilistic Generative Model
Sep 16, 2025Robots operating in domestic and office environments must understand object ownership to correctly execute instructions such as ``Bring me my cup.'' However, ownership cannot be reliably inferred from visual features alone. To address this gap, we propose Active Ownership Learning (ActOwL), a framework that enables robots to actively generate and ask ownership-related questions to users. ActOwL employs a probabilistic generative model to select questions that maximize information gain, thereby acquiring ownership knowledge efficiently to improve learning efficiency. Additionally, by leveraging commonsense knowledge from Large Language Models (LLM), objects are pre-classified as either shared or owned, and only owned objects are targeted for questioning. Through experiments in a simulated home environment and a real-world laboratory setting, ActOwL achieved significantly higher ownership clustering accuracy with fewer questions than baseline methods. These findings demonstrate the effectiveness of combining active inference with LLM-guided commonsense reasoning, advancing the capability of robots to acquire ownership knowledge for practical and socially appropriate task execution.
Multi-Robot Task Planning for Multi-Object Retrieval Tasks with Distributed On-Site Knowledge via Large Language Models
Sep 16, 2025



It is crucial to efficiently execute instructions such as "Find an apple and a banana" or "Get ready for a field trip," which require searching for multiple objects or understanding context-dependent commands. This study addresses the challenging problem of determining which robot should be assigned to which part of a task when each robot possesses different situational on-site knowledge-specifically, spatial concepts learned from the area designated to it by the user. We propose a task planning framework that leverages large language models (LLMs) and spatial concepts to decompose natural language instructions into subtasks and allocate them to multiple robots. We designed a novel few-shot prompting strategy that enables LLMs to infer required objects from ambiguous commands and decompose them into appropriate subtasks. In our experiments, the proposed method achieved 47/50 successful assignments, outperforming random (28/50) and commonsense-based assignment (26/50). Furthermore, we conducted qualitative evaluations using two actual mobile manipulators. The results demonstrated that our framework could handle instructions, including those involving ad hoc categories such as "Get ready for a field trip," by successfully performing task decomposition, assignment, sequential planning, and execution.
Co-Creative Learning via Metropolis-Hastings Interaction between Humans and AI
Jun 18, 2025



We propose co-creative learning as a novel paradigm where humans and AI, i.e., biological and artificial agents, mutually integrate their partial perceptual information and knowledge to construct shared external representations, a process we interpret as symbol emergence. Unlike traditional AI teaching based on unilateral knowledge transfer, this addresses the challenge of integrating information from inherently different modalities. We empirically test this framework using a human-AI interaction model based on the Metropolis-Hastings naming game (MHNG), a decentralized Bayesian inference mechanism. In an online experiment, 69 participants played a joint attention naming game (JA-NG) with one of three computer agent types (MH-based, always-accept, or always-reject) under partial observability. Results show that human-AI pairs with an MH-based agent significantly improved categorization accuracy through interaction and achieved stronger convergence toward a shared sign system. Furthermore, human acceptance behavior aligned closely with the MH-derived acceptance probability. These findings provide the first empirical evidence for co-creative learning emerging in human-AI dyads via MHNG-based interaction. This suggests a promising path toward symbiotic AI systems that learn with humans, rather than from them, by dynamically aligning perceptual experiences, opening a new venue for symbiotic AI alignment.
Reward-Independent Messaging for Decentralized Multi-Agent Reinforcement Learning
May 28, 2025In multi-agent reinforcement learning (MARL), effective communication improves agent performance, particularly under partial observability. We propose MARL-CPC, a framework that enables communication among fully decentralized, independent agents without parameter sharing. MARL-CPC incorporates a message learning model based on collective predictive coding (CPC) from emergent communication research. Unlike conventional methods that treat messages as part of the action space and assume cooperation, MARL-CPC links messages to state inference, supporting communication in non-cooperative, reward-independent settings. We introduce two algorithms -Bandit-CPC and IPPO-CPC- and evaluate them in non-cooperative MARL tasks. Benchmarks show that both outperform standard message-as-action approaches, establishing effective communication even when messages offer no direct benefit to the sender. These results highlight MARL-CPC's potential for enabling coordination in complex, decentralized environments.
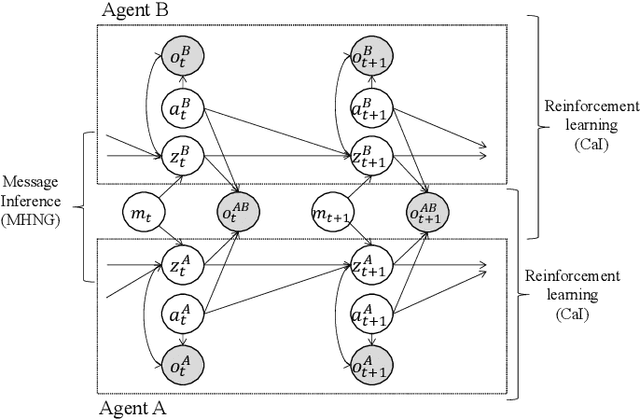
Metropolis-Hastings Captioning Game: Knowledge Fusion of Vision Language Models via Decentralized Bayesian Inference
Apr 13, 2025We propose the Metropolis-Hastings Captioning Game (MHCG), a method to fuse knowledge of multiple vision-language models (VLMs) by learning from each other. Although existing methods that combine multiple models suffer from inference costs and architectural constraints, MHCG avoids these problems by performing decentralized Bayesian inference through a process resembling a language game. The knowledge fusion process establishes communication between two VLM agents alternately captioning images and learning from each other. We conduct two image-captioning experiments with two VLMs, each pre-trained on a different dataset. The first experiment demonstrates that MHCG achieves consistent improvement in reference-free evaluation metrics. The second experiment investigates how MHCG contributes to sharing VLMs' category-level vocabulary by observing the occurrence of the vocabulary in the generated captions.
Decentralized Collective World Model for Emergent Communication and Coordination
Apr 04, 2025



We propose a fully decentralized multi-agent world model that enables both symbol emergence for communication and coordinated behavior through temporal extension of collective predictive coding. Unlike previous research that focuses on either communication or coordination separately, our approach achieves both simultaneously. Our method integrates world models with communication channels, enabling agents to predict environmental dynamics, estimate states from partial observations, and share critical information through bidirectional message exchange with contrastive learning for message alignment. Using a two-agent trajectory drawing task, we demonstrate that our communication-based approach outperforms non-communicative models when agents have divergent perceptual capabilities, achieving the second-best coordination after centralized models. Importantly, our distributed approach with constraints preventing direct access to other agents' internal states facilitates the emergence of more meaningful symbol systems that accurately reflect environmental states. These findings demonstrate the effectiveness of decentralized communication for supporting coordination while developing shared representations of the environment.
System 0/1/2/3: Quad-process theory for multi-timescale embodied collective cognitive systems
Mar 08, 2025



This paper introduces the System 0/1/2/3 framework as an extension of dual-process theory, employing a quad-process model of cognition. Expanding upon System 1 (fast, intuitive thinking) and System 2 (slow, deliberative thinking), we incorporate System 0, which represents pre-cognitive embodied processes, and System 3, which encompasses collective intelligence and symbol emergence. We contextualize this model within Bergson's philosophy by adopting multi-scale time theory to unify the diverse temporal dynamics of cognition. System 0 emphasizes morphological computation and passive dynamics, illustrating how physical embodiment enables adaptive behavior without explicit neural processing. Systems 1 and 2 are explained from a constructive perspective, incorporating neurodynamical and AI viewpoints. In System 3, we introduce collective predictive coding to explain how societal-level adaptation and symbol emergence operate over extended timescales. This comprehensive framework ranges from rapid embodied reactions to slow-evolving collective intelligence, offering a unified perspective on cognition across multiple timescales, levels of abstraction, and forms of human intelligence. The System 0/1/2/3 model provides a novel theoretical foundation for understanding the interplay between adaptive and cognitive processes, thereby opening new avenues for research in cognitive science, AI, robotics, and collective intelligence.
Generative Emergent Communication: Large Language Model is a Collective World Model
Dec 31, 2024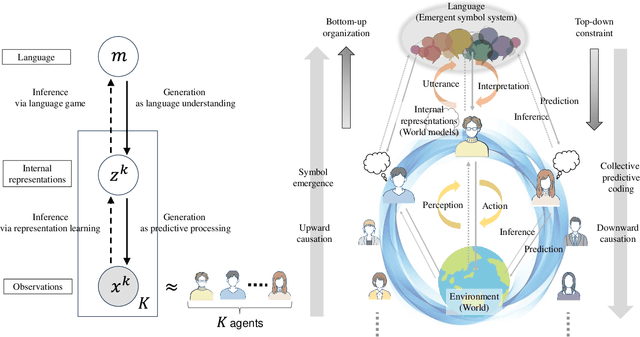


This study proposes a unifying theoretical framework called generative emergent communication (generative EmCom) that bridges emergent communication, world models, and large language models (LLMs) through the lens of collective predictive coding (CPC). The proposed framework formalizes the emergence of language and symbol systems through decentralized Bayesian inference across multiple agents, extending beyond conventional discriminative model-based approaches to emergent communication. This study makes the following two key contributions: First, we propose generative EmCom as a novel framework for understanding emergent communication, demonstrating how communication emergence in multi-agent reinforcement learning (MARL) can be derived from control as inference while clarifying its relationship to conventional discriminative approaches. Second, we propose a mathematical formulation showing the interpretation of LLMs as collective world models that integrate multiple agents' experiences through CPC. The framework provides a unified theoretical foundation for understanding how shared symbol systems emerge through collective predictive coding processes, bridging individual cognitive development and societal language evolution. Through mathematical formulations and discussion on prior works, we demonstrate how this framework explains fundamental aspects of language emergence and offers practical insights for understanding LLMs and developing sophisticated AI systems for improving human-AI interaction and multi-agent systems.