 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetropolis-Hastings Captioning Game: Knowledge Fusion of Vision Language Models via Decentralized Bayesian Inference
Apr 13, 2025We propose the Metropolis-Hastings Captioning Game (MHCG), a method to fuse knowledge of multiple vision-language models (VLMs) by learning from each other. Although existing methods that combine multiple models suffer from inference costs and architectural constraints, MHCG avoids these problems by performing decentralized Bayesian inference through a process resembling a language game. The knowledge fusion process establishes communication between two VLM agents alternately captioning images and learning from each other. We conduct two image-captioning experiments with two VLMs, each pre-trained on a different dataset. The first experiment demonstrates that MHCG achieves consistent improvement in reference-free evaluation metrics. The second experiment investigates how MHCG contributes to sharing VLMs' category-level vocabulary by observing the occurrence of the vocabulary in the generated captions.
Syntactic Learnability of Echo State Neural Language Models at Scale
Mar 03, 2025What is a neural model with minimum architectural complexity that exhibits reasonable language learning capability? To explore such a simple but sufficient neural language model, we revisit a basic reservoir computing (RC) model, Echo State Network (ESN), a restricted class of simple Recurrent Neural Networks. Our experiments showed that ESN with a large hidden state is comparable or superior to Transformer in grammaticality judgment tasks when trained with about 100M words, suggesting that architectures as complex as that of Transformer may not always be necessary for syntactic learning.
Neuro-Symbolic Contrastive Learning for Cross-domain Inference
Feb 13, 2025Pre-trained language models (PLMs) have made significant advances in natural language inference (NLI) tasks, however their sensitivity to textual perturbations and dependence on large datasets indicate an over-reliance on shallow heuristics. In contrast, inductive logic programming (ILP) excels at inferring logical relationships across diverse, sparse and limited datasets, but its discrete nature requires the inputs to be precisely specified, which limits their application. This paper proposes a bridge between the two approaches: neuro-symbolic contrastive learning. This allows for smooth and differentiable optimisation that improves logical accuracy across an otherwise discrete, noisy, and sparse topological space of logical functions. We show that abstract logical relationships can be effectively embedded within a neuro-symbolic paradigm, by representing data as logic programs and sets of logic rules. The embedding space captures highly varied textual information with similar semantic logical relations, but can also separate similar textual relations that have dissimilar logical relations. Experimental results demonstrate that our approach significantly improves the inference capabilities of the models in terms of generalisation and reasoning.
* In Proceedings ICLP 2024, arXiv:2502.08453
Generative Emergent Communication: Large Language Model is a Collective World Model
Dec 31, 2024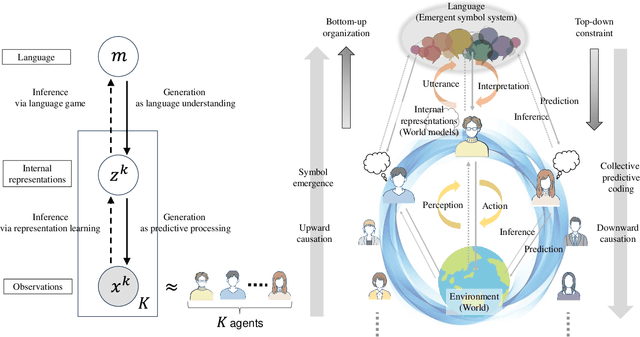

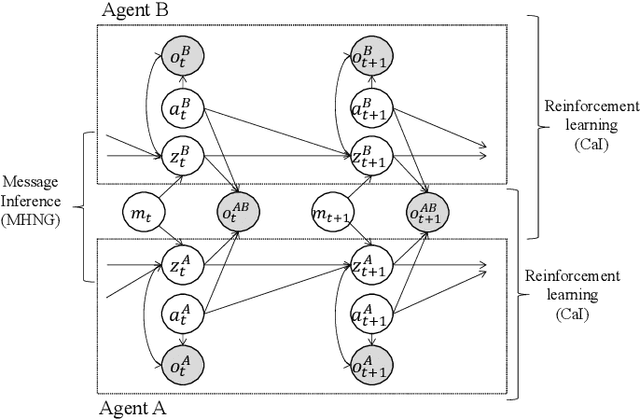

This study proposes a unifying theoretical framework called generative emergent communication (generative EmCom) that bridges emergent communication, world models, and large language models (LLMs) through the lens of collective predictive coding (CPC). The proposed framework formalizes the emergence of language and symbol systems through decentralized Bayesian inference across multiple agents, extending beyond conventional discriminative model-based approaches to emergent communication. This study makes the following two key contributions: First, we propose generative EmCom as a novel framework for understanding emergent communication, demonstrating how communication emergence in multi-agent reinforcement learning (MARL) can be derived from control as inference while clarifying its relationship to conventional discriminative approaches. Second, we propose a mathematical formulation showing the interpretation of LLMs as collective world models that integrate multiple agents' experiences through CPC. The framework provides a unified theoretical foundation for understanding how shared symbol systems emerge through collective predictive coding processes, bridging individual cognitive development and societal language evolution. Through mathematical formulations and discussion on prior works, we demonstrate how this framework explains fundamental aspects of language emergence and offers practical insights for understanding LLMs and developing sophisticated AI systems for improving human-AI interaction and multi-agent systems.
Emergent Word Order Universals from Cognitively-Motivated Language Models
Feb 19, 2024



The world's languages exhibit certain so-called typological or implicational universals; for example, Subject-Object-Verb (SOV) word order typically employs postpositions. Explaining the source of such biases is a key goal in linguistics. We study the word-order universals through a computational simulation with language models (LMs). Our experiments show that typologically typical word orders tend to have lower perplexity estimated by LMs with cognitively plausible biases: syntactic biases, specific parsing strategies, and memory limitations. This suggests that the interplay of these cognitive biases and predictability (perplexity) can explain many aspects of word-order universals. This also showcases the advantage of cognitively-motivated LMs, which are typically employed in cognitive modeling, in the computational simulation of language universals.
Lewis's Signaling Game as beta-VAE For Natural Word Lengths and Segments
Nov 08, 2023



As a sub-discipline of evolutionary and computational linguistics, emergent communication (EC) studies communication protocols, called emergent languages, arising in simulations where agents communicate. A key goal of EC is to give rise to languages that share statistical properties with natural languages. In this paper, we reinterpret Lewis's signaling game, a frequently used setting in EC, as beta-VAE and reformulate its objective function as ELBO. Consequently, we clarify the existence of prior distributions of emergent languages and show that the choice of the priors can influence their statistical properties. Specifically, we address the properties of word lengths and segmentation, known as Zipf's law of abbreviation (ZLA) and Harris's articulation scheme (HAS), respectively. It has been reported that the emergent languages do not follow them when using the conventional objective. We experimentally demonstrate that by selecting an appropriate prior distribution, more natural segments emerge, while suggesting that the conventional one prevents the languages from following ZLA and HAS.
Emergent Communication with Attention
May 18, 2023



To develop computational agents that better communicate using their own emergent language, we endow the agents with an ability to focus their attention on particular concepts in the environment. Humans often understand an object or scene as a composite of concepts and those concepts are further mapped onto words. We implement this intuition as cross-modal attention mechanisms in Speaker and Listener agents in a referential game and show attention leads to more compositional and interpretable emergent language. We also demonstrate how attention aids in understanding the learned communication protocol by investigating the attention weights associated with each message symbol and the alignment of attention weights between Speaker and Listener agents. Overall, our results suggest that attention is a promising mechanism for developing more human-like emergent language.
Empirical Analysis of the Inductive Bias of Recurrent Neural Networks by Discrete Fourier Transform of Output Sequences
May 16, 2023A unique feature of Recurrent Neural Networks (RNNs) is that it incrementally processes input sequences. In this research, we aim to uncover the inherent generalization properties, i.e., inductive bias, of RNNs with respect to how frequently RNNs switch the outputs through time steps in the sequence classification task, which we call output sequence frequency. Previous work analyzed inductive bias by training models with a few synthetic data and comparing the model's generalization with candidate generalization patterns. However, when examining the output sequence frequency, previous methods cannot be directly applied since enumerating candidate patterns is computationally difficult for longer sequences. To this end, we propose to directly calculate the output sequence frequency for each model by regarding the outputs of the model as discrete-time signals and applying frequency domain analysis. Experimental results showed that Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) have an inductive bias towards lower-frequency patterns, while Elman RNN tends to learn patterns in which the output changes at high frequencies. We also found that the inductive bias of LSTM and GRU varies with the number of layers and the size of hidden layers.