 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Word Orders Facilitate Length Generalization in LMs? An Investigation with GCG-Based Artificial Languages
Oct 14, 2025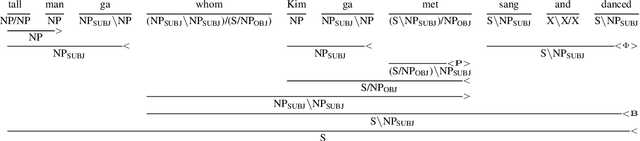


Whether language models (LMs) have inductive biases that favor typologically frequent grammatical properties over rare, implausible ones has been investigated, typically using artificial languages (ALs) (White and Cotterell, 2021; Kuribayashi et al., 2024). In this paper, we extend these works from two perspectives. First, we extend their context-free AL formalization by adopting Generalized Categorial Grammar (GCG) (Wood, 2014), which allows ALs to cover attested but previously overlooked constructions, such as unbounded dependency and mildly context-sensitive structures. Second, our evaluation focuses more on the generalization ability of LMs to process unseen longer test sentences. Thus, our ALs better capture features of natural languages and our experimental paradigm leads to clearer conclusions -- typologically plausible word orders tend to be easier for LMs to productively generalize.
ARWI: Arabic Write and Improve
Apr 16, 2025Although Arabic is spoken by over 400 million people, advanced Arabic writing assistance tools remain limited. To address this gap, we present ARWI, a new writing assistant that helps learners improve essay writing in Modern Standard Arabic. ARWI is the first publicly available Arabic writing assistant to include a prompt database for different proficiency levels, an Arabic text editor, state-of-the-art grammatical error detection and correction, and automated essay scoring aligned with the Common European Framework of Reference standards for language attainment. Moreover, ARWI can be used to gather a growing auto-annotated corpus, facilitating further research on Arabic grammar correction and essay scoring, as well as profiling patterns of errors made by native speakers and non-native learners. A preliminary user study shows that ARWI provides actionable feedback, helping learners identify grammatical gaps, assess language proficiency, and guide improvement.
PeerQA: A Scientific Question Answering Dataset from Peer Reviews
Feb 19, 2025We present PeerQA, a real-world, scientific, document-level Question Answering (QA) dataset. PeerQA questions have been sourced from peer reviews, which contain questions that reviewers raised while thoroughly examining the scientific article. Answers have been annotated by the original authors of each paper. The dataset contains 579 QA pairs from 208 academic articles, with a majority from ML and NLP, as well as a subset of other scientific communities like Geoscience and Public Health. PeerQA supports three critical tasks for developing practical QA systems: Evidence retrieval, unanswerable question classification, and answer generation. We provide a detailed analysis of the collected dataset and conduct experiments establishing baseline systems for all three tasks. Our experiments and analyses reveal the need for decontextualization in document-level retrieval, where we find that even simple decontextualization approaches consistently improve retrieval performance across architectures. On answer generation, PeerQA serves as a challenging benchmark for long-context modeling, as the papers have an average size of 12k tokens. Our code and data is available at https://github.com/UKPLab/peerqa.
RegNLP in Action: Facilitating Compliance Through Automated Information Retrieval and Answer Generation
Sep 09, 2024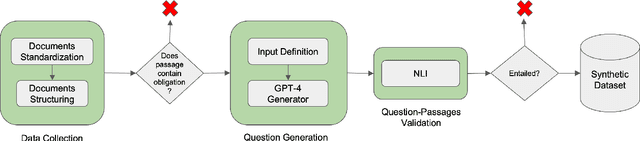
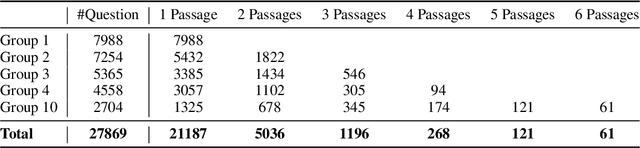


Regulatory documents, issued by governmental regulatory bodies, establish rules, guidelines, and standards that organizations must adhere to for legal compliance. These documents, characterized by their length, complexity and frequent updates, are challenging to interpret, requiring significant allocation of time and expertise on the part of organizations to ensure ongoing compliance.Regulatory Natural Language Processing (RegNLP) is a multidisciplinary subfield aimed at simplifying access to and interpretation of regulatory rules and obligations. We define an Automated Question-Passage Generation task for RegNLP, create the ObliQA dataset containing 27,869 questions derived from the Abu Dhabi Global Markets (ADGM) financial regulation document collection, design a baseline Regulatory Information Retrieval and Answer Generation system, and evaluate it with RePASs, a novel evaluation metric that tests whether generated answers accurately capture all relevant obligations and avoid contradictions.
Emergent Word Order Universals from Cognitively-Motivated Language Models
Feb 19, 2024



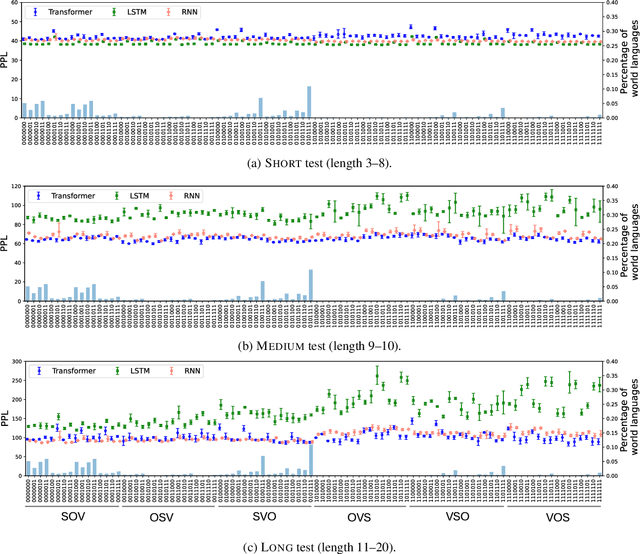
The world's languages exhibit certain so-called typological or implicational universals; for example, Subject-Object-Verb (SOV) word order typically employs postpositions. Explaining the source of such biases is a key goal in linguistics. We study the word-order universals through a computational simulation with language models (LMs). Our experiments show that typologically typical word orders tend to have lower perplexity estimated by LMs with cognitively plausible biases: syntactic biases, specific parsing strategies, and memory limitations. This suggests that the interplay of these cognitive biases and predictability (perplexity) can explain many aspects of word-order universals. This also showcases the advantage of cognitively-motivated LMs, which are typically employed in cognitive modeling, in the computational simulation of language universals.
Grammatical Error Correction: A Survey of the State of the Art
Nov 16, 2022Grammatical Error Correction (GEC) is the task of automatically detecting and correcting errors in text. The task not only includes the correction of grammatical errors, such as missing prepositions and mismatched subject-verb agreement, but also orthographic and semantic errors, such as misspellings and word choice errors respectively. The field has seen significant progress in the last decade, motivated in part by a series of five shared tasks, which drove the development of rule-based methods, statistical classifiers, statistical machine translation, and finally neural machine translation systems which represent the current dominant state of the art. In this survey paper, we condense the field into a single article and first outline some of the linguistic challenges of the task, introduce the most popular datasets that are available to researchers (for both English and other languages), and summarise the various methods and techniques that have been developed with a particular focus on artificial error generation. We next describe the many different approaches to evaluation as well as concerns surrounding metric reliability, especially in relation to subjective human judgements, before concluding with an overview of recent progress and suggestions for future work and remaining challenges. We hope that this survey will serve as comprehensive resource for researchers who are new to the field or who want to be kept apprised of recent developments.
Analyzing Neural Discourse Coherence Models
Nov 12, 2020



In this work, we systematically investigate how well current models of coherence can capture aspects of text implicated in discourse organisation. We devise two datasets of various linguistic alterations that undermine coherence and test model sensitivity to changes in syntax and semantics. We furthermore probe discourse embedding space and examine the knowledge that is encoded in representations of coherence. We hope this study shall provide further insight into how to frame the task and improve models of coherence assessment further. Finally, we make our datasets publicly available as a resource for researchers to use to test discourse coherence models.
Text Readability Assessment for Second Language Learners
Jun 18, 2019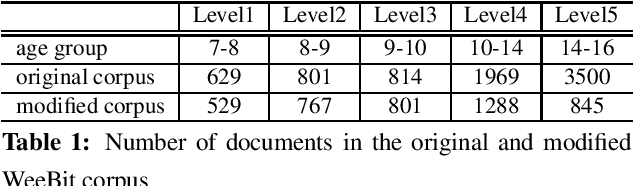

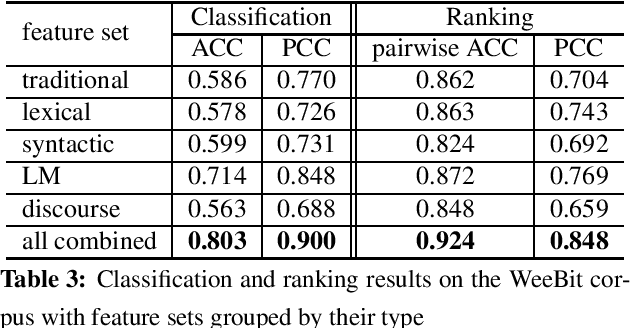
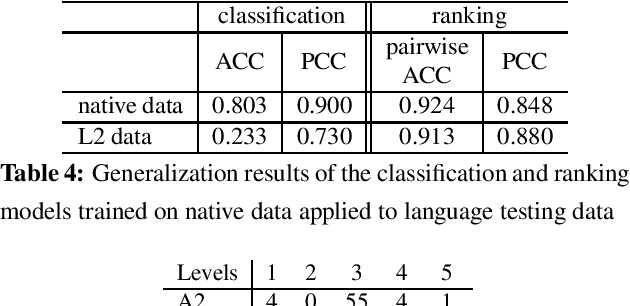
This paper addresses the task of readability assessment for the texts aimed at second language (L2) learners. One of the major challenges in this task is the lack of significantly sized level-annotated data. For the present work, we collected a dataset of CEFR-graded texts tailored for learners of English as an L2 and investigated text readability assessment for both native and L2 learners. We applied a generalization method to adapt models trained on larger native corpora to estimate text readability for learners, and explored domain adaptation and self-learning techniques to make use of the native data to improve system performance on the limited L2 data. In our experiments, the best performing model for readability on learner texts achieves an accuracy of 0.797 and PCC of $0.938$.
Automatic learner summary assessment for reading comprehension
Jun 18, 2019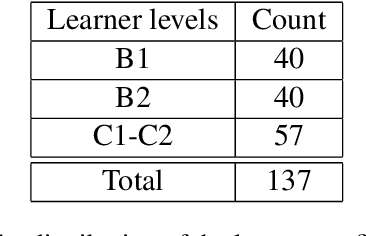
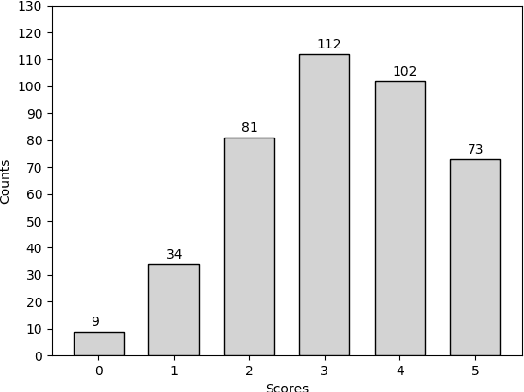
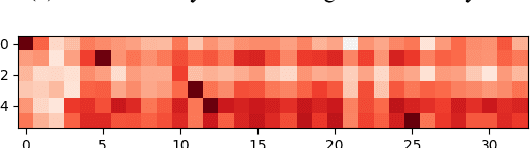
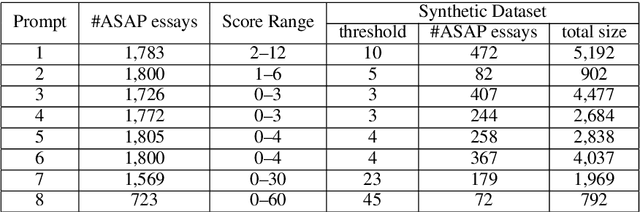
Automating the assessment of learner summaries provides a useful tool for assessing learner reading comprehension. We present a summarization task for evaluating non-native reading comprehension and propose three novel approaches to automatically assess the learner summaries. We evaluate our models on two datasets we created and show that our models outperform traditional approaches that rely on exact word match on this task. Our best model produces quality assessments close to professional examiners.
Neural Automated Essay Scoring and Coherence Modeling for Adversarially Crafted Input
Apr 23, 2018

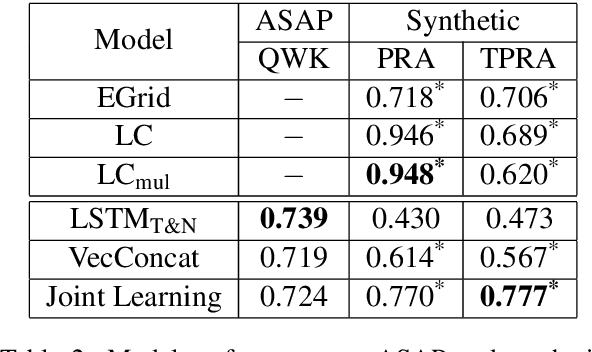
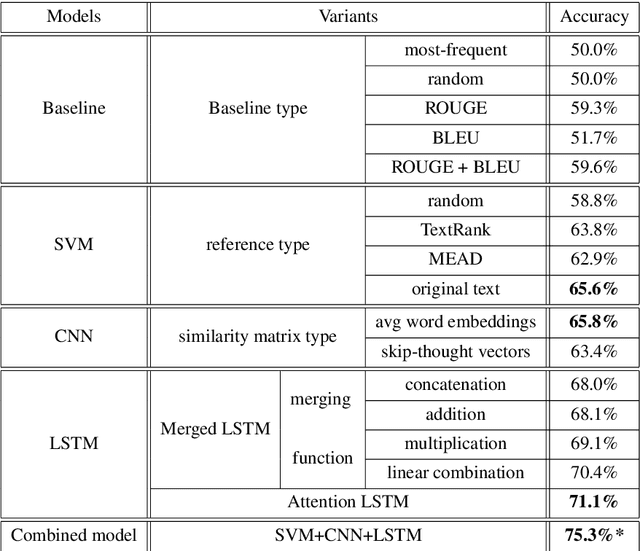
We demonstrate that current state-of-the-art approaches to Automated Essay Scoring (AES) are not well-suited to capturing adversarially crafted input of grammatical but incoherent sequences of sentences. We develop a neural model of local coherence that can effectively learn connectedness features between sentences, and propose a framework for integrating and jointly training the local coherence model with a state-of-the-art AES model. We evaluate our approach against a number of baselines and experimentally demonstrate its effectiveness on both the AES task and the task of flagging adversarial input, further contributing to the development of an approach that strengthens the validity of neural essay scoring models.