 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflect, Retry, Reward: Self-Improving LLMs via Reinforcement Learning
May 30, 2025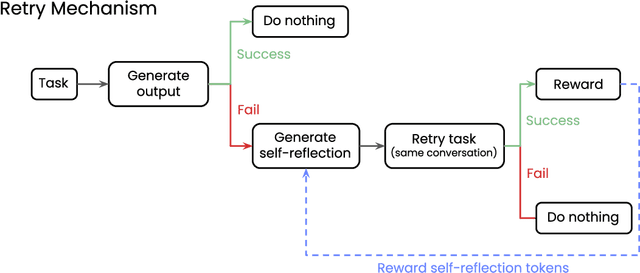
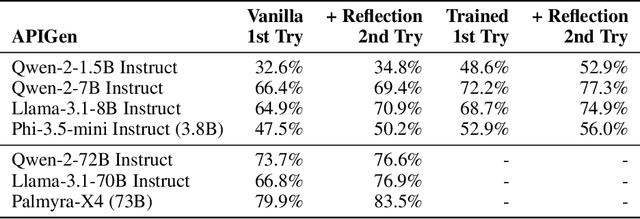
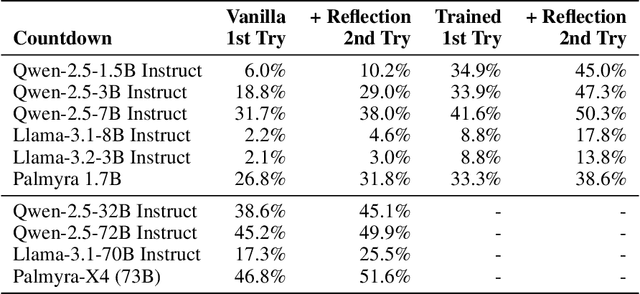
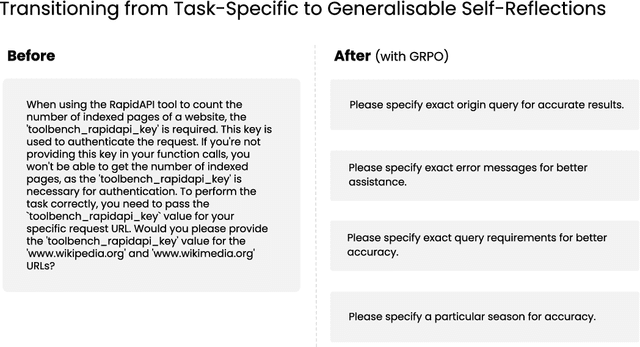
We explore a method for improving the performance of large language models through self-reflection and reinforcement learning. By incentivizing the model to generate better self-reflections when it answers incorrectly, we demonstrate that a model's ability to solve complex, verifiable tasks can be enhanced even when generating synthetic data is infeasible and only binary feedback is available. Our framework operates in two stages: first, upon failing a given task, the model generates a self-reflective commentary analyzing its previous attempt; second, the model is given another attempt at the task with the self-reflection in context. If the subsequent attempt succeeds, the tokens generated during the self-reflection phase are rewarded. Our experimental results show substantial performance gains across a variety of model architectures, as high as 34.7% improvement at math equation writing and 18.1% improvement at function calling. Notably, smaller fine-tuned models (1.5 billion to 7 billion parameters) outperform models in the same family that are 10 times larger. Our novel paradigm is thus an exciting pathway to more useful and reliable language models that can self-improve on challenging tasks with limited external feedback.
Writing in the Margins: Better Inference Pattern for Long Context Retrieval
Aug 27, 2024



In this paper, we introduce Writing in the Margins (WiM), a new inference pattern for Large Language Models designed to optimize the handling of long input sequences in retrieval-oriented tasks. This approach leverages the chunked prefill of the key-value cache to perform segment-wise inference, which enables efficient processing of extensive contexts along with the generation and classification of intermediate information ("margins") that guide the model towards specific tasks. This method increases computational overhead marginally while significantly enhancing the performance of off-the-shelf models without the need for fine-tuning. Specifically, we observe that WiM provides an average enhancement of 7.5% in accuracy for reasoning skills (HotpotQA, MultiHop-RAG) and more than a 30.0% increase in the F1-score for aggregation tasks (CWE). Additionally, we show how the proposed pattern fits into an interactive retrieval design that provides end-users with ongoing updates about the progress of context processing, and pinpoints the integration of relevant information into the final response. We release our implementation of WiM using Hugging Face Transformers library at https://github.com/writer/writing-in-the-margins.
Grammatical Error Correction for Code-Switched Sentences by Learners of English
Apr 18, 2024Code-switching (CSW) is a common phenomenon among multilingual speakers where multiple languages are used in a single discourse or utterance. Mixed language utterances may still contain grammatical errors however, yet most existing Grammar Error Correction (GEC) systems have been trained on monolingual data and not developed with CSW in mind. In this work, we conduct the first exploration into the use of GEC systems on CSW text. Through this exploration, we propose a novel method of generating synthetic CSW GEC datasets by translating different spans of text within existing GEC corpora. We then investigate different methods of selecting these spans based on CSW ratio, switch-point factor and linguistic constraints, and identify how they affect the performance of GEC systems on CSW text. Our best model achieves an average increase of 1.57 $F_{0.5}$ across 3 CSW test sets (English-Chinese, English-Korean and English-Japanese) without affecting the model's performance on a monolingual dataset. We furthermore discovered that models trained on one CSW language generalise relatively well to other typologically similar CSW languages.
Prompting open-source and commercial language models for grammatical error correction of English learner text
Jan 15, 2024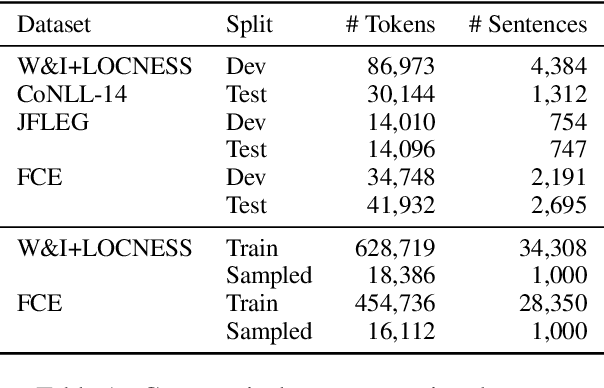
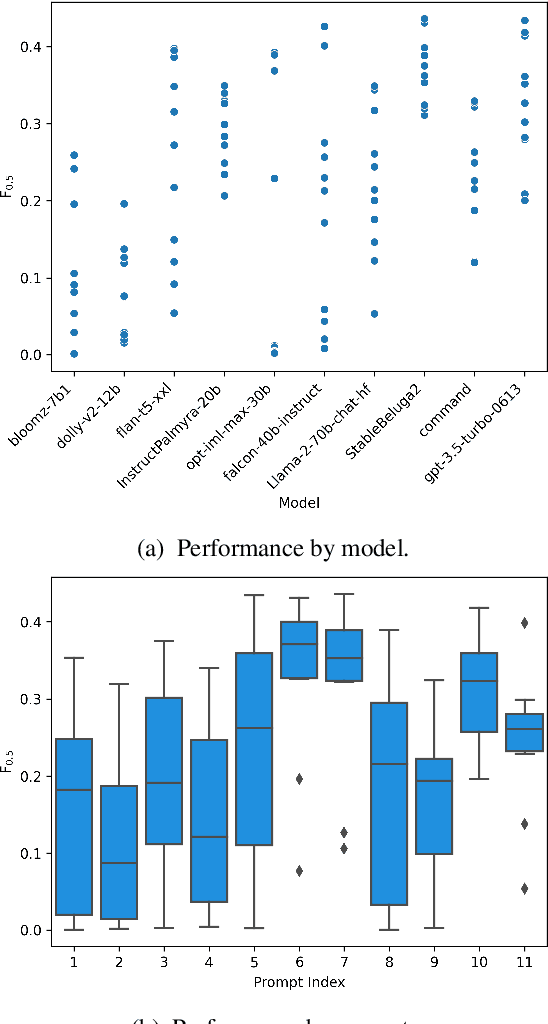

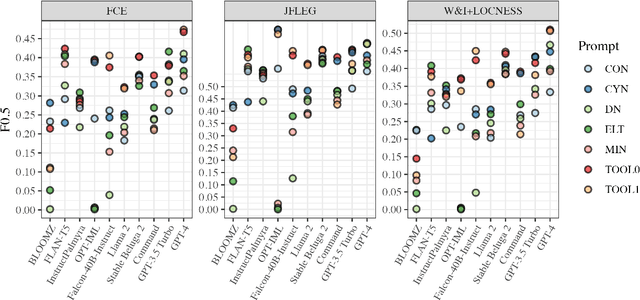
Thanks to recent advances in generative AI, we are able to prompt large language models (LLMs) to produce texts which are fluent and grammatical. In addition, it has been shown that we can elicit attempts at grammatical error correction (GEC) from LLMs when prompted with ungrammatical input sentences. We evaluate how well LLMs can perform at GEC by measuring their performance on established benchmark datasets. We go beyond previous studies, which only examined GPT* models on a selection of English GEC datasets, by evaluating seven open-source and three commercial LLMs on four established GEC benchmarks. We investigate model performance and report results against individual error types. Our results indicate that LLMs do not always outperform supervised English GEC models except in specific contexts -- namely commercial LLMs on benchmarks annotated with fluency corrections as opposed to minimal edits. We find that several open-source models outperform commercial ones on minimal edit benchmarks, and that in some settings zero-shot prompting is just as competitive as few-shot prompting.
On the application of Large Language Models for language teaching and assessment technology
Jul 17, 2023The recent release of very large language models such as PaLM and GPT-4 has made an unprecedented impact in the popular media and public consciousness, giving rise to a mixture of excitement and fear as to their capabilities and potential uses, and shining a light on natural language processing research which had not previously received so much attention. The developments offer great promise for education technology, and in this paper we look specifically at the potential for incorporating large language models in AI-driven language teaching and assessment systems. We consider several research areas and also discuss the risks and ethical considerations surrounding generative AI in education technology for language learners. Overall we find that larger language models offer improvements over previous models in text generation, opening up routes toward content generation which had not previously been plausible. For text generation they must be prompted carefully and their outputs may need to be reshaped before they are ready for use. For automated grading and grammatical error correction, tasks whose progress is checked on well-known benchmarks, early investigations indicate that large language models on their own do not improve on state-of-the-art results according to standard evaluation metrics. For grading it appears that linguistic features established in the literature should still be used for best performance, and for error correction it may be that the models can offer alternative feedback styles which are not measured sensitively with existing methods. In all cases, there is work to be done to experiment with the inclusion of large language models in education technology for language learners, in order to properly understand and report on their capacities and limitations, and to ensure that foreseeable risks such as misinformation and harmful bias are mitigated.
An Extended Sequence Tagging Vocabulary for Grammatical Error Correction
Feb 12, 2023We extend a current sequence-tagging approach to Grammatical Error Correction (GEC) by introducing specialised tags for spelling correction and morphological inflection using the SymSpell and LemmInflect algorithms. Our approach improves generalisation: the proposed new tagset allows a smaller number of tags to correct a larger range of errors. Our results show a performance improvement both overall and in the targeted error categories. We further show that ensembles trained with our new tagset outperform those trained with the baseline tagset on the public BEA benchmark.
Grammatical Error Correction: A Survey of the State of the Art
Nov 16, 2022Grammatical Error Correction (GEC) is the task of automatically detecting and correcting errors in text. The task not only includes the correction of grammatical errors, such as missing prepositions and mismatched subject-verb agreement, but also orthographic and semantic errors, such as misspellings and word choice errors respectively. The field has seen significant progress in the last decade, motivated in part by a series of five shared tasks, which drove the development of rule-based methods, statistical classifiers, statistical machine translation, and finally neural machine translation systems which represent the current dominant state of the art. In this survey paper, we condense the field into a single article and first outline some of the linguistic challenges of the task, introduce the most popular datasets that are available to researchers (for both English and other languages), and summarise the various methods and techniques that have been developed with a particular focus on artificial error generation. We next describe the many different approaches to evaluation as well as concerns surrounding metric reliability, especially in relation to subjective human judgements, before concluding with an overview of recent progress and suggestions for future work and remaining challenges. We hope that this survey will serve as comprehensive resource for researchers who are new to the field or who want to be kept apprised of recent developments.
Probing for targeted syntactic knowledge through grammatical error detection
Oct 28, 2022



Targeted studies testing knowledge of subject-verb agreement (SVA) indicate that pre-trained language models encode syntactic information. We assert that if models robustly encode subject-verb agreement, they should be able to identify when agreement is correct and when it is incorrect. To that end, we propose grammatical error detection as a diagnostic probe to evaluate token-level contextual representations for their knowledge of SVA. We evaluate contextual representations at each layer from five pre-trained English language models: BERT, XLNet, GPT-2, RoBERTa, and ELECTRA. We leverage public annotated training data from both English second language learners and Wikipedia edits, and report results on manually crafted stimuli for subject-verb agreement. We find that masked language models linearly encode information relevant to the detection of SVA errors, while the autoregressive models perform on par with our baseline. However, we also observe a divergence in performance when probes are trained on different training sets, and when they are evaluated on different syntactic constructions, suggesting the information pertaining to SVA error detection is not robustly encoded.
Contextual Sentence Classification: Detecting Sustainability Initiatives in Company Reports
Oct 07, 2021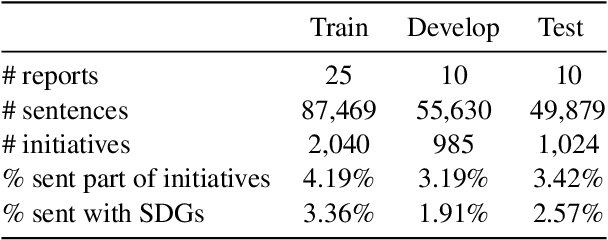
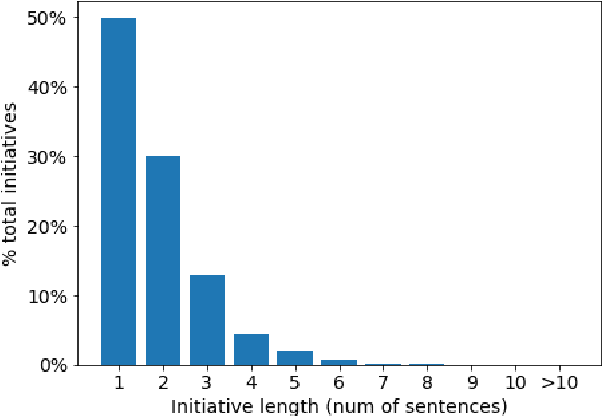
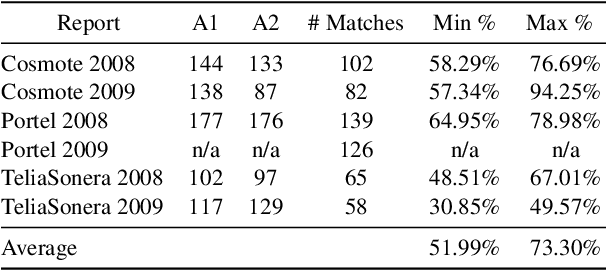
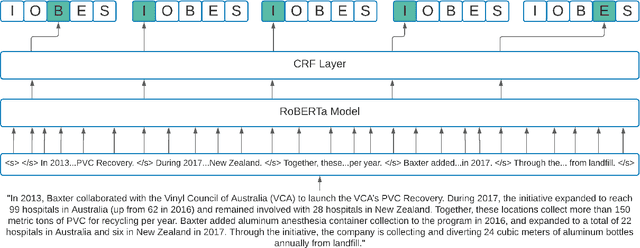
We introduce the novel task of detecting sustainability initiatives in company reports. Given a full report, the aim is to automatically identify mentions of practical activities that a company has performed in order to tackle specific societal issues. As a single initiative can often be described over multiples sentences, new methods for identifying continuous sentence spans needs to be developed. We release a new dataset of company reports in which the text has been manually annotated with sustainability initiatives. We also evaluate different models for initiative detection, introducing a novel aggregation and evaluation methodology. Our proposed architecture uses sequences of five consecutive sentences to account for contextual information when making classification decisions at the individual sentence level.
Neural Grammatical Error Correction with Finite State Transducers
Apr 05, 2019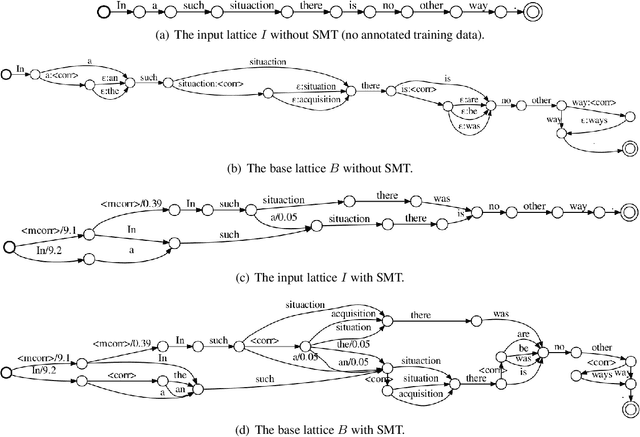

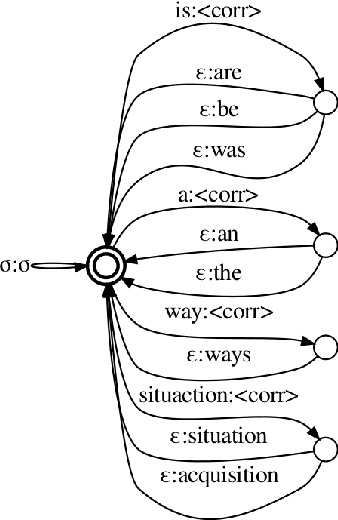
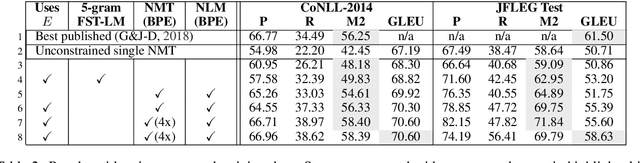
Grammatical error correction (GEC) is one of the areas in natural language processing in which purely neural models have not yet superseded more traditional symbolic models. Hybrid systems combining phrase-based statistical machine translation (SMT) and neural sequence models are currently among the most effective approaches to GEC. However, both SMT and neural sequence-to-sequence models require large amounts of annotated data. Language model based GEC (LM-GEC) is a promising alternative which does not rely on annotated training data. We show how to improve LM-GEC by applying modelling techniques based on finite state transducers. We report further gains by rescoring with neural language models. We show that our methods developed for LM-GEC can also be used with SMT systems if annotated training data is available. Our best system outperforms the best published result on the CoNLL-2014 test set, and achieves far better relative improvements over the SMT baselines than previous hybrid systems.