 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias Dynamics in BabyLMs: Towards a Compute-Efficient Sandbox for Democratising Pre-Training Debiasing
Jan 15, 2026Pre-trained language models (LMs) have, over the last few years, grown substantially in both societal adoption and training costs. This rapid growth in size has constrained progress in understanding and mitigating their biases. Since re-training LMs is prohibitively expensive, most debiasing work has focused on post-hoc or masking-based strategies, which often fail to address the underlying causes of bias. In this work, we seek to democratise pre-model debiasing research by using low-cost proxy models. Specifically, we investigate BabyLMs, compact BERT-like models trained on small and mutable corpora that can approximate bias acquisition and learning dynamics of larger models. We show that BabyLMs display closely aligned patterns of intrinsic bias formation and performance development compared to standard BERT models, despite their drastically reduced size. Furthermore, correlations between BabyLMs and BERT hold across multiple intra-model and post-model debiasing methods. Leveraging these similarities, we conduct pre-model debiasing experiments with BabyLMs, replicating prior findings and presenting new insights regarding the influence of gender imbalance and toxicity on bias formation. Our results demonstrate that BabyLMs can serve as an effective sandbox for large-scale LMs, reducing pre-training costs from over 500 GPU-hours to under 30 GPU-hours. This provides a way to democratise pre-model debiasing research and enables faster, more accessible exploration of methods for building fairer LMs.
Teacher Demonstrations in a BabyLM's Zone of Proximal Development for Contingent Multi-Turn Interaction
Oct 23, 2025Multi-turn dialogues between a child and a caregiver are characterized by a property called contingency - that is, prompt, direct, and meaningful exchanges between interlocutors. We introduce ContingentChat, a teacher-student framework that benchmarks and improves multi-turn contingency in a BabyLM trained on 100M words. Using a novel alignment dataset for post-training, BabyLM generates responses that are more grammatical and cohesive. Experiments with adaptive teacher decoding strategies show limited additional gains. ContingentChat demonstrates the benefits of targeted post-training for dialogue quality and indicates that contingency remains a challenging goal for BabyLMs.
Investigating ReLoRA: Effects on the Learning Dynamics of Small Language Models
Sep 16, 2025Parameter-efficient methods such as LoRA have revolutionised the fine-tuning of LLMs. Still, their extension to pretraining via ReLoRA is less well understood, especially for small language models (SLMs), which offer lower computational and environmental costs. This work is the first systematic study of ReLoRA in SLMs (11M-66M parameters), evaluating both performance and learning dynamics. Through ablation experiments, we find that ReLoRA generally performs worse than standard training on loss, Paloma perplexity and BLiMP, with the gap widening for the larger models. Further analysis of the learning dynamics of the models indicates that ReLoRA reinforces the rank deficiencies found in smaller models. These results indicate that low-rank update strategies may not transfer easily to SLM pretraining, highlighting the need for more research in the low-compute regime.
Rubrik's Cube: Testing a New Rubric for Evaluating Explanations on the CUBE dataset
Mar 31, 2025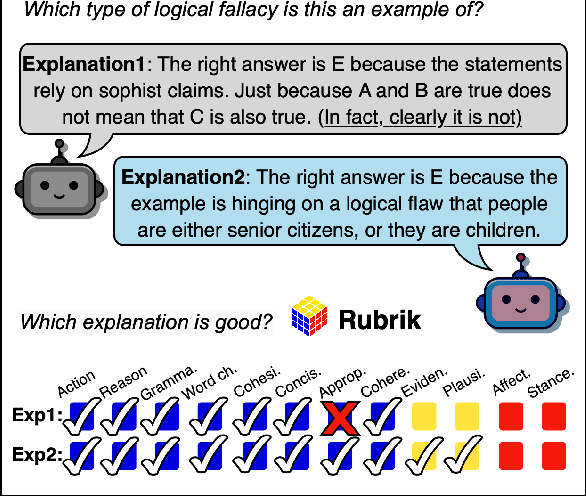

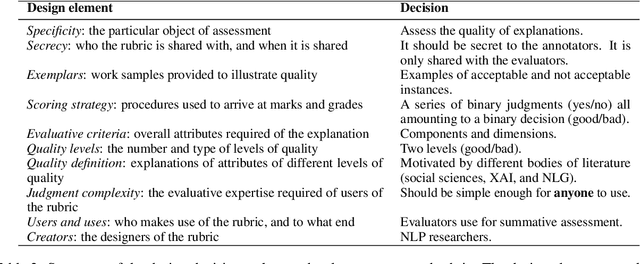
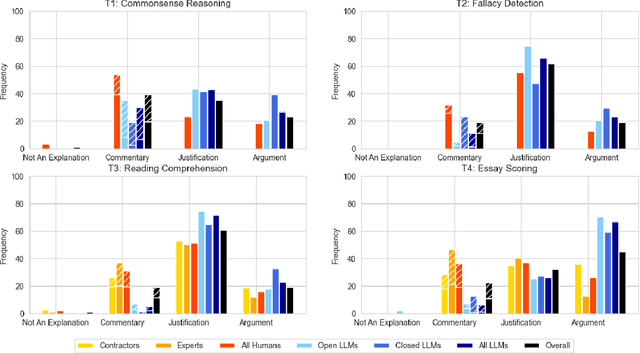
The performance and usability of Large-Language Models (LLMs) are driving their use in explanation generation tasks. However, despite their widespread adoption, LLM explanations have been found to be unreliable, making it difficult for users to distinguish good from bad explanations. To address this issue, we present Rubrik's CUBE, an education-inspired rubric and a dataset of 26k explanations, written and later quality-annotated using the rubric by both humans and six open- and closed-source LLMs. The CUBE dataset focuses on two reasoning and two language tasks, providing the necessary diversity for us to effectively test our proposed rubric. Using Rubrik, we find that explanations are influenced by both task and perceived difficulty. Low quality stems primarily from a lack of conciseness in LLM-generated explanations, rather than cohesion and word choice. The full dataset, rubric, and code will be made available upon acceptance.
From Babble to Words: Pre-Training Language Models on Continuous Streams of Phonemes
Oct 30, 2024



Language models are typically trained on large corpora of text in their default orthographic form. However, this is not the only option; representing data as streams of phonemes can offer unique advantages, from deeper insights into phonological language acquisition to improved performance on sound-based tasks. The challenge lies in evaluating the impact of phoneme-based training, as most benchmarks are also orthographic. To address this, we develop a pipeline to convert text datasets into a continuous stream of phonemes. We apply this pipeline to the 100-million-word pre-training dataset from the BabyLM challenge, as well as to standard language and grammatical benchmarks, enabling us to pre-train and evaluate a model using phonemic input representations. Our results show that while phoneme-based training slightly reduces performance on traditional language understanding tasks, it offers valuable analytical and practical benefits.
Less is More: Pre-Training Cross-Lingual Small-Scale Language Models with Cognitively-Plausible Curriculum Learning Strategies
Oct 30, 2024Curriculum Learning has been a popular strategy to improve the cognitive plausibility of Small-Scale Language Models (SSLMs) in the BabyLM Challenge. However, it has not led to considerable improvements over non-curriculum models. We assess whether theoretical linguistic acquisition theories can be used to specify more fine-grained curriculum learning strategies, creating age-ordered corpora of Child-Directed Speech for four typologically distant language families to implement SSLMs and acquisition-inspired curricula cross-lingually. Comparing the success of three objective curricula (Growing, Inwards and MMM) that precisely replicate the predictions of acquisition theories on a standard SSLM architecture, we find fine-grained acquisition-inspired curricula can outperform non-curriculum baselines and performance benefits of curricula strategies in SSLMs can be derived by specifying fine-grained language-specific curricula that precisely replicate language acquisition theories.
Mitigating Frequency Bias and Anisotropy in Language Model Pre-Training with Syntactic Smoothing
Oct 15, 2024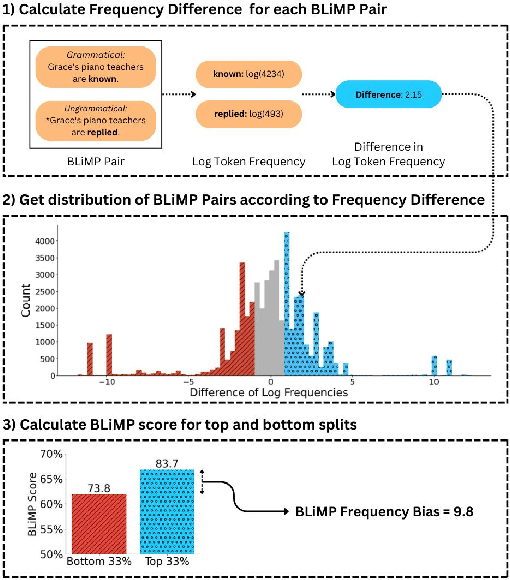



Language models strongly rely on frequency information because they maximize the likelihood of tokens during pre-training. As a consequence, language models tend to not generalize well to tokens that are seldom seen during training. Moreover, maximum likelihood training has been discovered to give rise to anisotropy: representations of tokens in a model tend to cluster tightly in a high-dimensional cone, rather than spreading out over their representational capacity. Our work introduces a method for quantifying the frequency bias of a language model by assessing sentence-level perplexity with respect to token-level frequency. We then present a method for reducing the frequency bias of a language model by inducing a syntactic prior over token representations during pre-training. Our Syntactic Smoothing method adjusts the maximum likelihood objective function to distribute the learning signal to syntactically similar tokens. This approach results in better performance on infrequent English tokens and a decrease in anisotropy. We empirically show that the degree of anisotropy in a model correlates with its frequency bias.
Tending Towards Stability: Convergence Challenges in Small Language Models
Oct 15, 2024Increasing the number of parameters in language models is a common strategy to enhance their performance. However, smaller language models remain valuable due to their lower operational costs. Despite their advantages, smaller models frequently underperform compared to their larger counterparts, even when provided with equivalent data and computational resources. Specifically, their performance tends to degrade in the late pretraining phase. This is anecdotally attributed to their reduced representational capacity. Yet, the exact causes of this performance degradation remain unclear. We use the Pythia model suite to analyse the training dynamics that underlie this phenomenon. Across different model sizes, we investigate the convergence of the Attention and MLP activations to their final state and examine how the effective rank of their parameters influences this process. We find that nearly all layers in larger models stabilise early in training - within the first 20% - whereas layers in smaller models exhibit slower and less stable convergence, especially when their parameters have lower effective rank. By linking the convergence of layers' activations to their parameters' effective rank, our analyses can guide future work to address inefficiencies in the learning dynamics of small models.
Prompting open-source and commercial language models for grammatical error correction of English learner text
Jan 15, 2024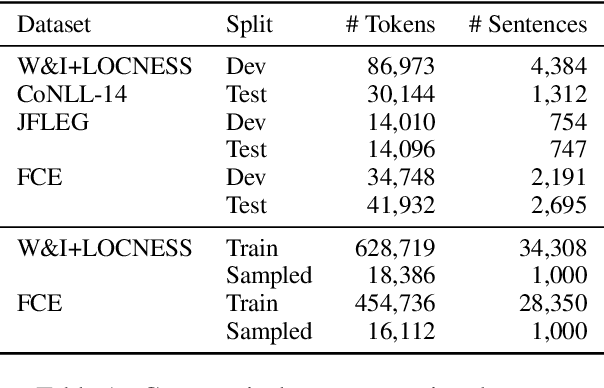
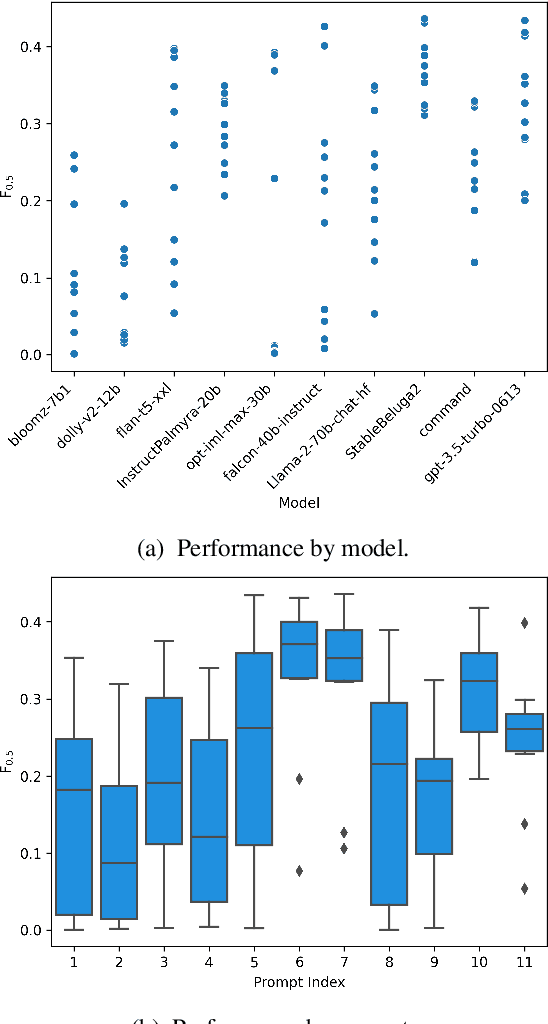

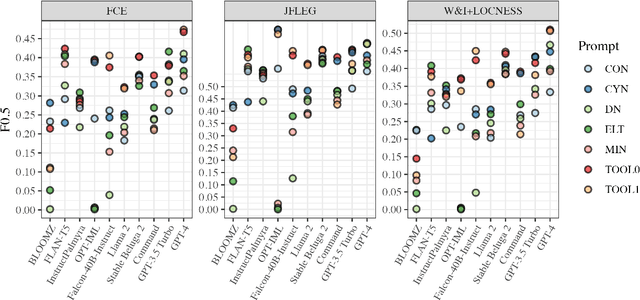
Thanks to recent advances in generative AI, we are able to prompt large language models (LLMs) to produce texts which are fluent and grammatical. In addition, it has been shown that we can elicit attempts at grammatical error correction (GEC) from LLMs when prompted with ungrammatical input sentences. We evaluate how well LLMs can perform at GEC by measuring their performance on established benchmark datasets. We go beyond previous studies, which only examined GPT* models on a selection of English GEC datasets, by evaluating seven open-source and three commercial LLMs on four established GEC benchmarks. We investigate model performance and report results against individual error types. Our results indicate that LLMs do not always outperform supervised English GEC models except in specific contexts -- namely commercial LLMs on benchmarks annotated with fluency corrections as opposed to minimal edits. We find that several open-source models outperform commercial ones on minimal edit benchmarks, and that in some settings zero-shot prompting is just as competitive as few-shot prompting.
CLIMB: Curriculum Learning for Infant-inspired Model Building
Nov 15, 2023We describe our team's contribution to the STRICT-SMALL track of the BabyLM Challenge. The challenge requires training a language model from scratch using only a relatively small training dataset of ten million words. We experiment with three variants of cognitively-motivated curriculum learning and analyze their effect on the performance of the model on linguistic evaluation tasks. In the vocabulary curriculum, we analyze methods for constraining the vocabulary in the early stages of training to simulate cognitively more plausible learning curves. In the data curriculum experiments, we vary the order of the training instances based on i) infant-inspired expectations and ii) the learning behavior of the model. In the objective curriculum, we explore different variations of combining the conventional masked language modeling task with a more coarse-grained word class prediction task to reinforce linguistic generalization capabilities. Our results did not yield consistent improvements over our own non-curriculum learning baseline across a range of linguistic benchmarks; however, we do find marginal gains on select tasks. Our analysis highlights key takeaways for specific combinations of tasks and settings which benefit from our proposed curricula. We moreover determine that careful selection of model architecture, and training hyper-parameters yield substantial improvements over the default baselines provided by the BabyLM challenge.