 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Models Know More Than They Say: Probing Analogical Reasoning in LLMs
Apr 04, 2026Analogical reasoning is a core cognitive faculty essential for narrative understanding. While LLMs perform well when surface and structural cues align, they struggle in cases where an analogy is not apparent on the surface but requires latent information, suggesting limitations in abstraction and generalisation. In this paper we compare a model's probed representations with its prompted performance at detecting narrative analogies, revealing an asymmetry: for rhetorical analogies, probing significantly outperforms prompting in open-source models, while for narrative analogies, they achieve a similar (low) performance. This suggests that the relationship between internal representations and prompted behavior is task-dependent and may reflect limitations in how prompting accesses available information.
Voxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Computational Discovery of Chiasmus in Ancient Religious Text
Jan 18, 2025
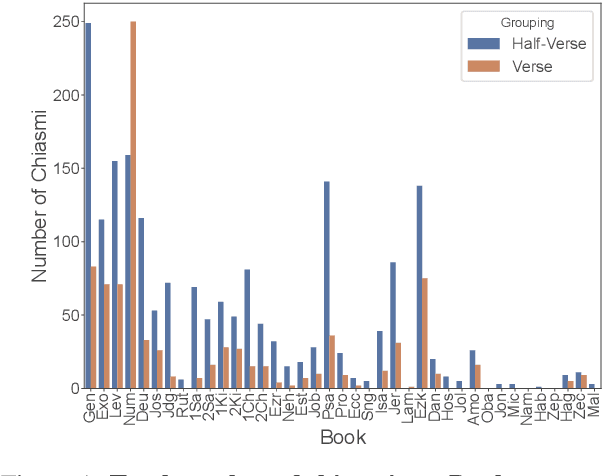
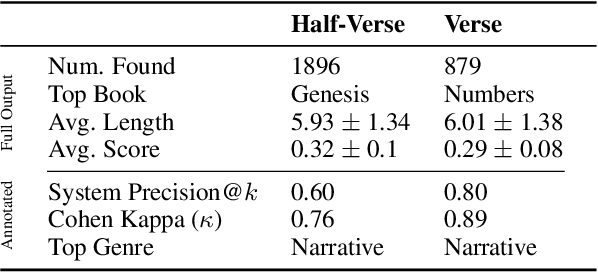

Chiasmus, a debated literary device in Biblical texts, has captivated mystics while sparking ongoing scholarly discussion. In this paper, we introduce the first computational approach to systematically detect chiasmus within Biblical passages. Our method leverages neural embeddings to capture lexical and semantic patterns associated with chiasmus, applied at multiple levels of textual granularity (half-verses, verses). We also involve expert annotators to review a subset of the detected patterns. Despite its computational efficiency, our method achieves robust results, with high inter-annotator agreement and system precision@k of 0.80 at the verse level and 0.60 at the half-verse level. We further provide a qualitative analysis of the distribution of detected chiasmi, along with selected examples that highlight the effectiveness of our approach.
Characterizing the Effects of Translation on Intertextuality using Multilingual Embedding Spaces
Jan 18, 2025

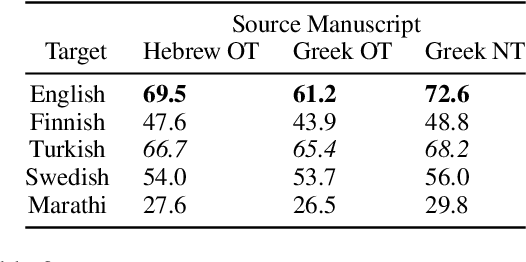
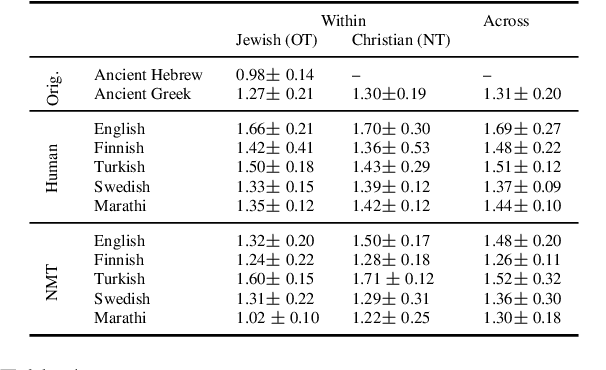
Rhetorical devices are difficult to translate, but they are crucial to the translation of literary documents. We investigate the use of multilingual embedding spaces to characterize the preservation of intertextuality, one common rhetorical device, across human and machine translation. To do so, we use Biblical texts, which are both full of intertextual references and are highly translated works. We provide a metric to characterize intertextuality at the corpus level and provide a quantitative analysis of the preservation of this rhetorical device across extant human translations and machine-generated counterparts. We go on to provide qualitative analysis of cases wherein human translations over- or underemphasize the intertextuality present in the text, whereas machine translations provide a neutral baseline. This provides support for established scholarship proposing that human translators have a propensity to amplify certain literary characteristics of the original manuscripts.
Your Large Language Models Are Leaving Fingerprints
May 22, 2024It has been shown that finetuned transformers and other supervised detectors effectively distinguish between human and machine-generated text in some situations arXiv:2305.13242, but we find that even simple classifiers on top of n-gram and part-of-speech features can achieve very robust performance on both in- and out-of-domain data. To understand how this is possible, we analyze machine-generated output text in five datasets, finding that LLMs possess unique fingerprints that manifest as slight differences in the frequency of certain lexical and morphosyntactic features. We show how to visualize such fingerprints, describe how they can be used to detect machine-generated text and find that they are even robust across textual domains. We find that fingerprints are often persistent across models in the same model family (e.g. llama-13b vs. llama-65b) and that models fine-tuned for chat are easier to detect than standard language models, indicating that LLM fingerprints may be directly induced by the training data.
CLIMB: Curriculum Learning for Infant-inspired Model Building
Nov 15, 2023



We describe our team's contribution to the STRICT-SMALL track of the BabyLM Challenge. The challenge requires training a language model from scratch using only a relatively small training dataset of ten million words. We experiment with three variants of cognitively-motivated curriculum learning and analyze their effect on the performance of the model on linguistic evaluation tasks. In the vocabulary curriculum, we analyze methods for constraining the vocabulary in the early stages of training to simulate cognitively more plausible learning curves. In the data curriculum experiments, we vary the order of the training instances based on i) infant-inspired expectations and ii) the learning behavior of the model. In the objective curriculum, we explore different variations of combining the conventional masked language modeling task with a more coarse-grained word class prediction task to reinforce linguistic generalization capabilities. Our results did not yield consistent improvements over our own non-curriculum learning baseline across a range of linguistic benchmarks; however, we do find marginal gains on select tasks. Our analysis highlights key takeaways for specific combinations of tasks and settings which benefit from our proposed curricula. We moreover determine that careful selection of model architecture, and training hyper-parameters yield substantial improvements over the default baselines provided by the BabyLM challenge.
A Source-Criticism Debiasing Method for GloVe Embeddings
Jun 25, 2021
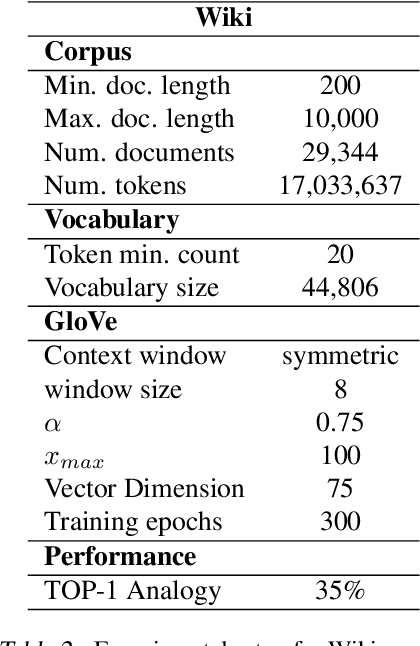
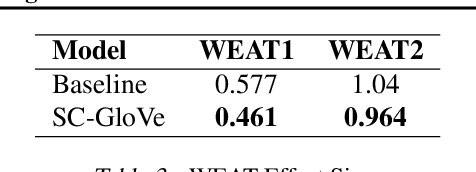
It is well-documented that word embeddings trained on large public corpora consistently exhibit known human social biases. Although many methods for debiasing exist, almost all fixate on completely eliminating biased information from the embeddings and often diminish training set size in the process. In this paper, we present a simple yet effective method for debiasing GloVe word embeddings (Pennington et al., 2014) which works by incorporating explicit information about training set bias rather than removing biased data outright. Our method runs quickly and efficiently with the help of a fast bias gradient approximation method from Brunet et al. (2019). As our approach is akin to the notion of 'source criticism' in the humanities, we term our method Source-Critical GloVe (SC-GloVe). We show that SC-GloVe reduces the effect size on Word Embedding Association Test (WEAT) sets without sacrificing training data or TOP-1 performance.