 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias Dynamics in BabyLMs: Towards a Compute-Efficient Sandbox for Democratising Pre-Training Debiasing
Jan 15, 2026Pre-trained language models (LMs) have, over the last few years, grown substantially in both societal adoption and training costs. This rapid growth in size has constrained progress in understanding and mitigating their biases. Since re-training LMs is prohibitively expensive, most debiasing work has focused on post-hoc or masking-based strategies, which often fail to address the underlying causes of bias. In this work, we seek to democratise pre-model debiasing research by using low-cost proxy models. Specifically, we investigate BabyLMs, compact BERT-like models trained on small and mutable corpora that can approximate bias acquisition and learning dynamics of larger models. We show that BabyLMs display closely aligned patterns of intrinsic bias formation and performance development compared to standard BERT models, despite their drastically reduced size. Furthermore, correlations between BabyLMs and BERT hold across multiple intra-model and post-model debiasing methods. Leveraging these similarities, we conduct pre-model debiasing experiments with BabyLMs, replicating prior findings and presenting new insights regarding the influence of gender imbalance and toxicity on bias formation. Our results demonstrate that BabyLMs can serve as an effective sandbox for large-scale LMs, reducing pre-training costs from over 500 GPU-hours to under 30 GPU-hours. This provides a way to democratise pre-model debiasing research and enables faster, more accessible exploration of methods for building fairer LMs.
Teacher Demonstrations in a BabyLM's Zone of Proximal Development for Contingent Multi-Turn Interaction
Oct 23, 2025Multi-turn dialogues between a child and a caregiver are characterized by a property called contingency - that is, prompt, direct, and meaningful exchanges between interlocutors. We introduce ContingentChat, a teacher-student framework that benchmarks and improves multi-turn contingency in a BabyLM trained on 100M words. Using a novel alignment dataset for post-training, BabyLM generates responses that are more grammatical and cohesive. Experiments with adaptive teacher decoding strategies show limited additional gains. ContingentChat demonstrates the benefits of targeted post-training for dialogue quality and indicates that contingency remains a challenging goal for BabyLMs.
DACTYL: Diverse Adversarial Corpus of Texts Yielded from Large Language Models
Aug 01, 2025Existing AIG (AI-generated) text detectors struggle in real-world settings despite succeeding in internal testing, suggesting that they may not be robust enough. We rigorously examine the machine-learning procedure to build these detectors to address this. Most current AIG text detection datasets focus on zero-shot generations, but little work has been done on few-shot or one-shot generations, where LLMs are given human texts as an example. In response, we introduce the Diverse Adversarial Corpus of Texts Yielded from Language models (DACTYL), a challenging AIG text detection dataset focusing on one-shot/few-shot generations. We also include texts from domain-specific continued-pre-trained (CPT) language models, where we fully train all parameters using a memory-efficient optimization approach. Many existing AIG text detectors struggle significantly on our dataset, indicating a potential vulnerability to one-shot/few-shot and CPT-generated texts. We also train our own classifiers using two approaches: standard binary cross-entropy (BCE) optimization and a more recent approach, deep X-risk optimization (DXO). While BCE-trained classifiers marginally outperform DXO classifiers on the DACTYL test set, the latter excels on out-of-distribution (OOD) texts. In our mock deployment scenario in student essay detection with an OOD student essay dataset, the best DXO classifier outscored the best BCE-trained classifier by 50.56 macro-F1 score points at the lowest false positive rates for both. Our results indicate that DXO classifiers generalize better without overfitting to the test set. Our experiments highlight several areas of improvement for AIG text detectors.
AFRIDOC-MT: Document-level MT Corpus for African Languages
Jan 10, 2025



This paper introduces AFRIDOC-MT, a document-level multi-parallel translation dataset covering English and five African languages: Amharic, Hausa, Swahili, Yor\`ub\'a, and Zulu. The dataset comprises 334 health and 271 information technology news documents, all human-translated from English to these languages. We conduct document-level translation benchmark experiments by evaluating neural machine translation (NMT) models and large language models (LLMs) for translations between English and these languages, at both the sentence and pseudo-document levels. These outputs are realigned to form complete documents for evaluation. Our results indicate that NLLB-200 achieved the best average performance among the standard NMT models, while GPT-4o outperformed general-purpose LLMs. Fine-tuning selected models led to substantial performance gains, but models trained on sentences struggled to generalize effectively to longer documents. Furthermore, our analysis reveals that some LLMs exhibit issues such as under-generation, repetition of words or phrases, and off-target translations, especially for African languages.
From Babble to Words: Pre-Training Language Models on Continuous Streams of Phonemes
Oct 30, 2024



Language models are typically trained on large corpora of text in their default orthographic form. However, this is not the only option; representing data as streams of phonemes can offer unique advantages, from deeper insights into phonological language acquisition to improved performance on sound-based tasks. The challenge lies in evaluating the impact of phoneme-based training, as most benchmarks are also orthographic. To address this, we develop a pipeline to convert text datasets into a continuous stream of phonemes. We apply this pipeline to the 100-million-word pre-training dataset from the BabyLM challenge, as well as to standard language and grammatical benchmarks, enabling us to pre-train and evaluate a model using phonemic input representations. Our results show that while phoneme-based training slightly reduces performance on traditional language understanding tasks, it offers valuable analytical and practical benefits.
Mitigating Frequency Bias and Anisotropy in Language Model Pre-Training with Syntactic Smoothing
Oct 15, 2024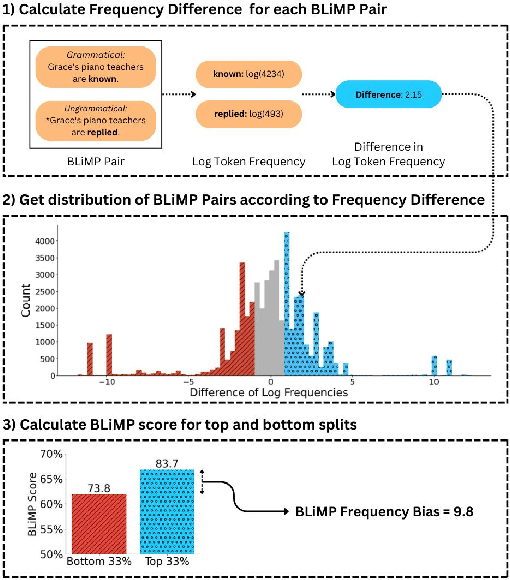



Language models strongly rely on frequency information because they maximize the likelihood of tokens during pre-training. As a consequence, language models tend to not generalize well to tokens that are seldom seen during training. Moreover, maximum likelihood training has been discovered to give rise to anisotropy: representations of tokens in a model tend to cluster tightly in a high-dimensional cone, rather than spreading out over their representational capacity. Our work introduces a method for quantifying the frequency bias of a language model by assessing sentence-level perplexity with respect to token-level frequency. We then present a method for reducing the frequency bias of a language model by inducing a syntactic prior over token representations during pre-training. Our Syntactic Smoothing method adjusts the maximum likelihood objective function to distribute the learning signal to syntactically similar tokens. This approach results in better performance on infrequent English tokens and a decrease in anisotropy. We empirically show that the degree of anisotropy in a model correlates with its frequency bias.
Grammatical Error Correction for Code-Switched Sentences by Learners of English
Apr 18, 2024Code-switching (CSW) is a common phenomenon among multilingual speakers where multiple languages are used in a single discourse or utterance. Mixed language utterances may still contain grammatical errors however, yet most existing Grammar Error Correction (GEC) systems have been trained on monolingual data and not developed with CSW in mind. In this work, we conduct the first exploration into the use of GEC systems on CSW text. Through this exploration, we propose a novel method of generating synthetic CSW GEC datasets by translating different spans of text within existing GEC corpora. We then investigate different methods of selecting these spans based on CSW ratio, switch-point factor and linguistic constraints, and identify how they affect the performance of GEC systems on CSW text. Our best model achieves an average increase of 1.57 $F_{0.5}$ across 3 CSW test sets (English-Chinese, English-Korean and English-Japanese) without affecting the model's performance on a monolingual dataset. We furthermore discovered that models trained on one CSW language generalise relatively well to other typologically similar CSW languages.
Prompting open-source and commercial language models for grammatical error correction of English learner text
Jan 15, 2024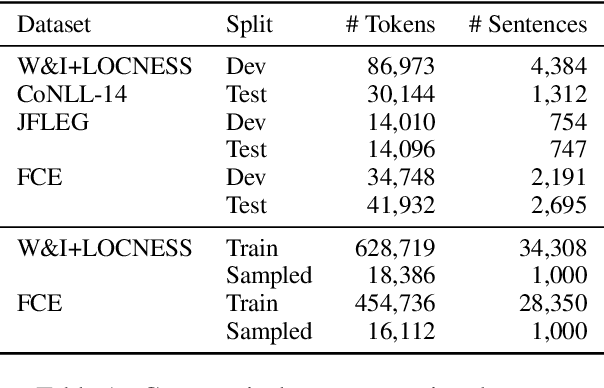
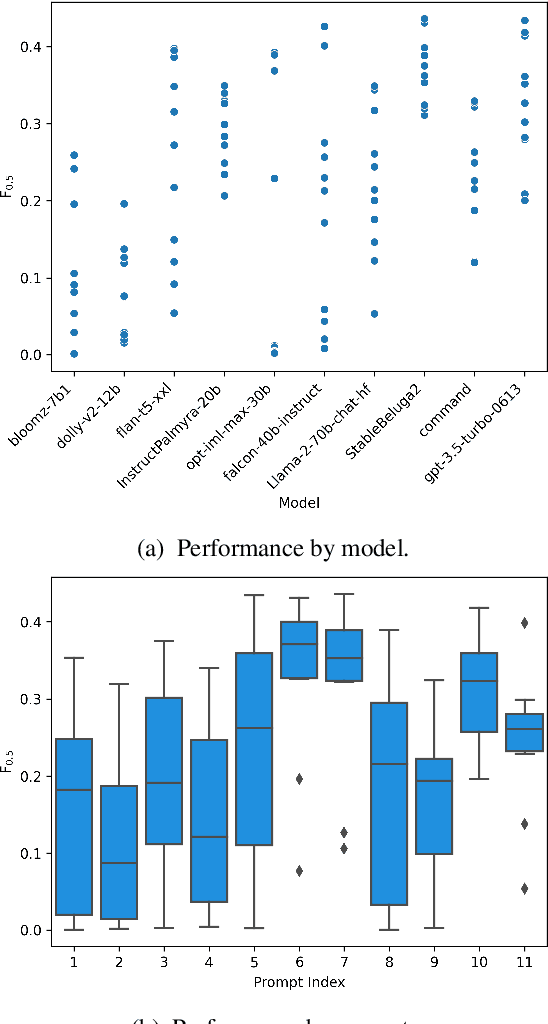

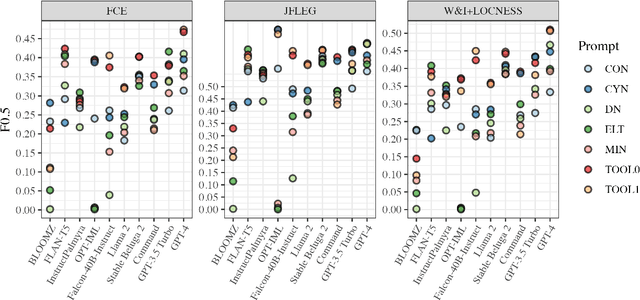
Thanks to recent advances in generative AI, we are able to prompt large language models (LLMs) to produce texts which are fluent and grammatical. In addition, it has been shown that we can elicit attempts at grammatical error correction (GEC) from LLMs when prompted with ungrammatical input sentences. We evaluate how well LLMs can perform at GEC by measuring their performance on established benchmark datasets. We go beyond previous studies, which only examined GPT* models on a selection of English GEC datasets, by evaluating seven open-source and three commercial LLMs on four established GEC benchmarks. We investigate model performance and report results against individual error types. Our results indicate that LLMs do not always outperform supervised English GEC models except in specific contexts -- namely commercial LLMs on benchmarks annotated with fluency corrections as opposed to minimal edits. We find that several open-source models outperform commercial ones on minimal edit benchmarks, and that in some settings zero-shot prompting is just as competitive as few-shot prompting.
CLIMB: Curriculum Learning for Infant-inspired Model Building
Nov 15, 2023



We describe our team's contribution to the STRICT-SMALL track of the BabyLM Challenge. The challenge requires training a language model from scratch using only a relatively small training dataset of ten million words. We experiment with three variants of cognitively-motivated curriculum learning and analyze their effect on the performance of the model on linguistic evaluation tasks. In the vocabulary curriculum, we analyze methods for constraining the vocabulary in the early stages of training to simulate cognitively more plausible learning curves. In the data curriculum experiments, we vary the order of the training instances based on i) infant-inspired expectations and ii) the learning behavior of the model. In the objective curriculum, we explore different variations of combining the conventional masked language modeling task with a more coarse-grained word class prediction task to reinforce linguistic generalization capabilities. Our results did not yield consistent improvements over our own non-curriculum learning baseline across a range of linguistic benchmarks; however, we do find marginal gains on select tasks. Our analysis highlights key takeaways for specific combinations of tasks and settings which benefit from our proposed curricula. We moreover determine that careful selection of model architecture, and training hyper-parameters yield substantial improvements over the default baselines provided by the BabyLM challenge.
On the application of Large Language Models for language teaching and assessment technology
Jul 17, 2023The recent release of very large language models such as PaLM and GPT-4 has made an unprecedented impact in the popular media and public consciousness, giving rise to a mixture of excitement and fear as to their capabilities and potential uses, and shining a light on natural language processing research which had not previously received so much attention. The developments offer great promise for education technology, and in this paper we look specifically at the potential for incorporating large language models in AI-driven language teaching and assessment systems. We consider several research areas and also discuss the risks and ethical considerations surrounding generative AI in education technology for language learners. Overall we find that larger language models offer improvements over previous models in text generation, opening up routes toward content generation which had not previously been plausible. For text generation they must be prompted carefully and their outputs may need to be reshaped before they are ready for use. For automated grading and grammatical error correction, tasks whose progress is checked on well-known benchmarks, early investigations indicate that large language models on their own do not improve on state-of-the-art results according to standard evaluation metrics. For grading it appears that linguistic features established in the literature should still be used for best performance, and for error correction it may be that the models can offer alternative feedback styles which are not measured sensitively with existing methods. In all cases, there is work to be done to experiment with the inclusion of large language models in education technology for language learners, in order to properly understand and report on their capacities and limitations, and to ensure that foreseeable risks such as misinformation and harmful bias are mitigated.