 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automated Fact-Checking of Real-World Claims: Exploring Task Formulation and Assessment with LLMs
Feb 13, 2025



Fact-checking is necessary to address the increasing volume of misinformation. Traditional fact-checking relies on manual analysis to verify claims, but it is slow and resource-intensive. This study establishes baseline comparisons for Automated Fact-Checking (AFC) using Large Language Models (LLMs) across multiple labeling schemes (binary, three-class, five-class) and extends traditional claim verification by incorporating analysis, verdict classification, and explanation in a structured setup to provide comprehensive justifications for real-world claims. We evaluate Llama-3 models of varying sizes (3B, 8B, 70B) on 17,856 claims collected from PolitiFact (2007-2024) using evidence retrieved via restricted web searches. We utilize TIGERScore as a reference-free evaluation metric to score the justifications. Our results show that larger LLMs consistently outperform smaller LLMs in classification accuracy and justification quality without fine-tuning. We find that smaller LLMs in a one-shot scenario provide comparable task performance to fine-tuned Small Language Models (SLMs) with large context sizes, while larger LLMs consistently surpass them. Evidence integration improves performance across all models, with larger LLMs benefiting most. Distinguishing between nuanced labels remains challenging, emphasizing the need for further exploration of labeling schemes and alignment with evidences. Our findings demonstrate the potential of retrieval-augmented AFC with LLMs.
AFRIDOC-MT: Document-level MT Corpus for African Languages
Jan 10, 2025



This paper introduces AFRIDOC-MT, a document-level multi-parallel translation dataset covering English and five African languages: Amharic, Hausa, Swahili, Yor\`ub\'a, and Zulu. The dataset comprises 334 health and 271 information technology news documents, all human-translated from English to these languages. We conduct document-level translation benchmark experiments by evaluating neural machine translation (NMT) models and large language models (LLMs) for translations between English and these languages, at both the sentence and pseudo-document levels. These outputs are realigned to form complete documents for evaluation. Our results indicate that NLLB-200 achieved the best average performance among the standard NMT models, while GPT-4o outperformed general-purpose LLMs. Fine-tuning selected models led to substantial performance gains, but models trained on sentences struggled to generalize effectively to longer documents. Furthermore, our analysis reveals that some LLMs exhibit issues such as under-generation, repetition of words or phrases, and off-target translations, especially for African languages.
Target-Aware Contextual Political Bias Detection in News
Oct 02, 2023

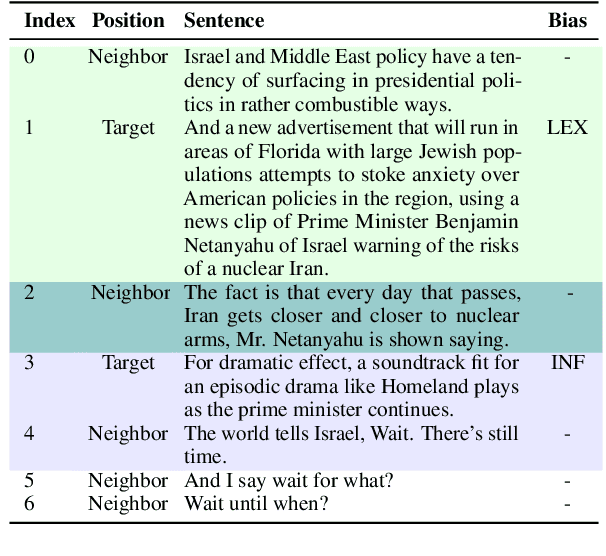

Media bias detection requires comprehensive integration of information derived from multiple news sources. Sentence-level political bias detection in news is no exception, and has proven to be a challenging task that requires an understanding of bias in consideration of the context. Inspired by the fact that humans exhibit varying degrees of writing styles, resulting in a diverse range of statements with different local and global contexts, previous work in media bias detection has proposed augmentation techniques to exploit this fact. Despite their success, we observe that these techniques introduce noise by over-generalizing bias context boundaries, which hinders performance. To alleviate this issue, we propose techniques to more carefully search for context using a bias-sensitive, target-aware approach for data augmentation. Comprehensive experiments on the well-known BASIL dataset show that when combined with pre-trained models such as BERT, our augmentation techniques lead to state-of-the-art results. Our approach outperforms previous methods significantly, obtaining an F1-score of 58.15 over state-of-the-art bias detection task.