 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfriSUD: A Dependency Treebank Collection for Evaluating Models on African Languages
Jun 10, 2026Despite their linguistic diversity and global significance, African languages remain underrepresented in research and resources to support NLP. We aim to bridge this gap by introducing AfriSUD, the first large-scale collection of syntactically annotated treebanks for nine diverse African languages spanning major language families and regions across Sub-Saharan Africa. Using the Surface-Syntactic Universal Dependencies (SUD) framework, our community-led effort provides high-quality, native-speaker verified data that capture typological key features such as agglutination and tone. We evaluate a range of models on AfriSUD for part-of-speech tagging and dependency parsing including non-transformer baselines, multilingual pretrained encoders, and LLMs. Our results reveal a significant syntax gap, where models still show clear limitations across the nine languages, suggesting that existing architectures may not fully capture the structural diversity of African-language syntax.
AFRIDOC-MT: Document-level MT Corpus for African Languages
Jan 10, 2025



This paper introduces AFRIDOC-MT, a document-level multi-parallel translation dataset covering English and five African languages: Amharic, Hausa, Swahili, Yor\`ub\'a, and Zulu. The dataset comprises 334 health and 271 information technology news documents, all human-translated from English to these languages. We conduct document-level translation benchmark experiments by evaluating neural machine translation (NMT) models and large language models (LLMs) for translations between English and these languages, at both the sentence and pseudo-document levels. These outputs are realigned to form complete documents for evaluation. Our results indicate that NLLB-200 achieved the best average performance among the standard NMT models, while GPT-4o outperformed general-purpose LLMs. Fine-tuning selected models led to substantial performance gains, but models trained on sentences struggled to generalize effectively to longer documents. Furthermore, our analysis reveals that some LLMs exhibit issues such as under-generation, repetition of words or phrases, and off-target translations, especially for African languages.
MasakhaPOS: Part-of-Speech Tagging for Typologically Diverse African Languages
May 23, 2023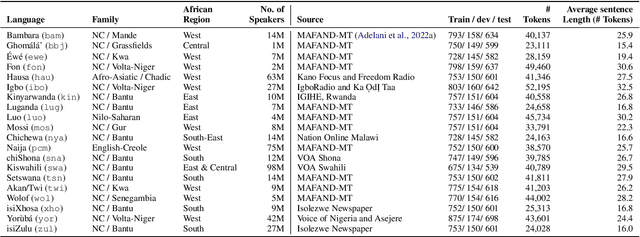
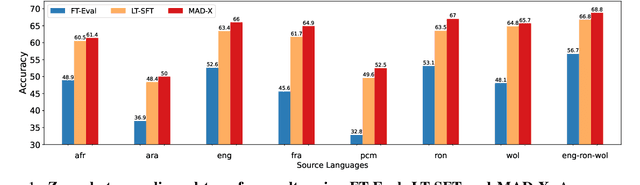
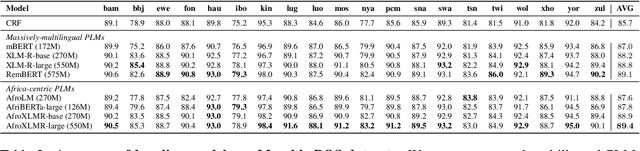
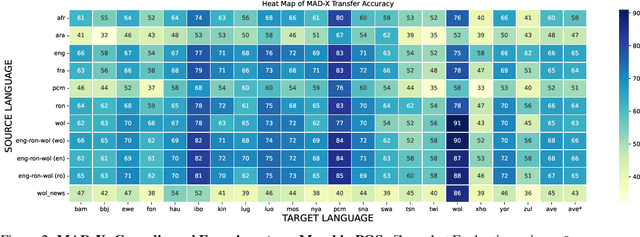
In this paper, we present MasakhaPOS, the largest part-of-speech (POS) dataset for 20 typologically diverse African languages. We discuss the challenges in annotating POS for these languages using the UD (universal dependencies) guidelines. We conducted extensive POS baseline experiments using conditional random field and several multilingual pre-trained language models. We applied various cross-lingual transfer models trained with data available in UD. Evaluating on the MasakhaPOS dataset, we show that choosing the best transfer language(s) in both single-source and multi-source setups greatly improves the POS tagging performance of the target languages, in particular when combined with cross-lingual parameter-efficient fine-tuning methods. Crucially, transferring knowledge from a language that matches the language family and morphosyntactic properties seems more effective for POS tagging in unseen languages.
$\varepsilon$ KÚ <MASK>: Integrating Yorùbá cultural greetings into machine translation
Apr 24, 2023This paper investigates the performance of massively multilingual neural machine translation (NMT) systems in translating Yor\`ub\'a greetings ($\varepsilon$ k\'u [MASK]), which are a big part of Yor\`ub\'a language and culture, into English. To evaluate these models, we present IkiniYor\`ub\'a, a Yor\`ub\'a-English translation dataset containing some Yor\`ub\'a greetings, and sample use cases. We analysed the performance of different multilingual NMT systems including Google and NLLB and show that these models struggle to accurately translate Yor\`ub\'a greetings into English. In addition, we trained a Yor\`ub\'a-English model by finetuning an existing NMT model on the training split of IkiniYor\`ub\'a and this achieved better performance when compared to the pre-trained multilingual NMT models, although they were trained on a large volume of data.