 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the N-gram Approximation of Pre-trained Language Models
Jun 12, 2023



Large pre-trained language models (PLMs) have shown remarkable performance across various natural language understanding (NLU) tasks, particularly in low-resource settings. Nevertheless, their potential in Automatic Speech Recognition (ASR) remains largely unexplored. This study investigates the potential usage of PLMs for language modelling in ASR. We compare the application of large-scale text sampling and probability conversion for approximating GPT-2 into an n-gram model. Furthermore, we introduce a vocabulary-restricted decoding method for random sampling, and evaluate the effects of domain difficulty and data size on the usability of generated text. Our findings across eight domain-specific corpora support the use of sampling-based approximation and show that interpolating with a large sampled corpus improves test perplexity over a baseline trigram by 15%. Our vocabulary-restricted decoding method pushes this improvement further by 5% in domain-specific settings.
MasakhaPOS: Part-of-Speech Tagging for Typologically Diverse African Languages
May 23, 2023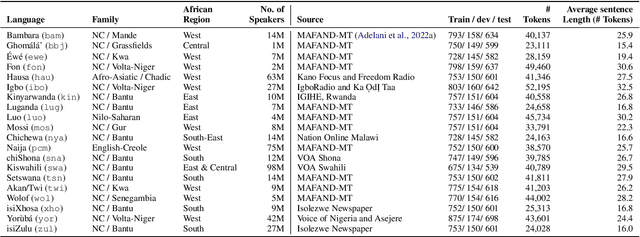
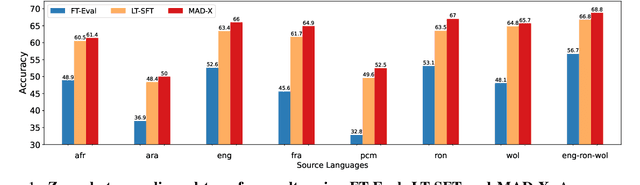
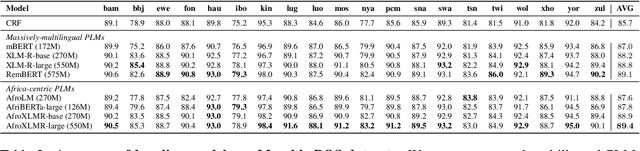
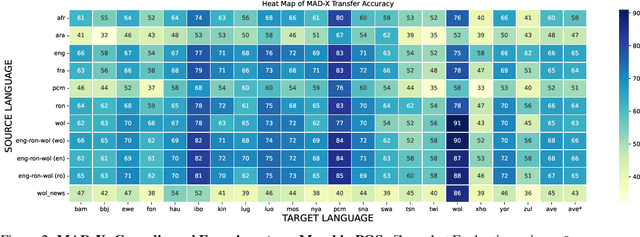
In this paper, we present MasakhaPOS, the largest part-of-speech (POS) dataset for 20 typologically diverse African languages. We discuss the challenges in annotating POS for these languages using the UD (universal dependencies) guidelines. We conducted extensive POS baseline experiments using conditional random field and several multilingual pre-trained language models. We applied various cross-lingual transfer models trained with data available in UD. Evaluating on the MasakhaPOS dataset, we show that choosing the best transfer language(s) in both single-source and multi-source setups greatly improves the POS tagging performance of the target languages, in particular when combined with cross-lingual parameter-efficient fine-tuning methods. Crucially, transferring knowledge from a language that matches the language family and morphosyntactic properties seems more effective for POS tagging in unseen languages.
$\varepsilon$ KÚ <MASK>: Integrating Yorùbá cultural greetings into machine translation
Apr 24, 2023This paper investigates the performance of massively multilingual neural machine translation (NMT) systems in translating Yor\`ub\'a greetings ($\varepsilon$ k\'u [MASK]), which are a big part of Yor\`ub\'a language and culture, into English. To evaluate these models, we present IkiniYor\`ub\'a, a Yor\`ub\'a-English translation dataset containing some Yor\`ub\'a greetings, and sample use cases. We analysed the performance of different multilingual NMT systems including Google and NLLB and show that these models struggle to accurately translate Yor\`ub\'a greetings into English. In addition, we trained a Yor\`ub\'a-English model by finetuning an existing NMT model on the training split of IkiniYor\`ub\'a and this achieved better performance when compared to the pre-trained multilingual NMT models, although they were trained on a large volume of data.
Masakhane-Afrisenti at SemEval-2023 Task 12: Sentiment Analysis using Afro-centric Language Models and Adapters for Low-resource African Languages
Apr 13, 2023



AfriSenti-SemEval Shared Task 12 of SemEval-2023. The task aims to perform monolingual sentiment classification (sub-task A) for 12 African languages, multilingual sentiment classification (sub-task B), and zero-shot sentiment classification (task C). For sub-task A, we conducted experiments using classical machine learning classifiers, Afro-centric language models, and language-specific models. For task B, we fine-tuned multilingual pre-trained language models that support many of the languages in the task. For task C, we used we make use of a parameter-efficient Adapter approach that leverages monolingual texts in the target language for effective zero-shot transfer. Our findings suggest that using pre-trained Afro-centric language models improves performance for low-resource African languages. We also ran experiments using adapters for zero-shot tasks, and the results suggest that we can obtain promising results by using adapters with a limited amount of resources.
BibleTTS: a large, high-fidelity, multilingual, and uniquely African speech corpus
Jul 07, 2022
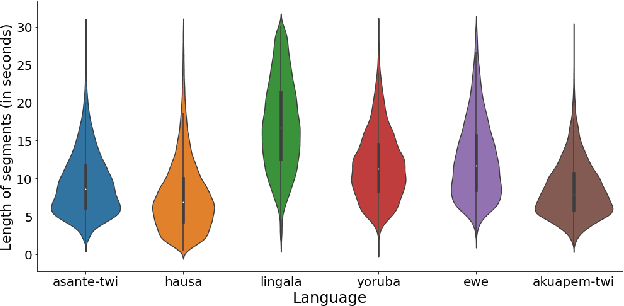

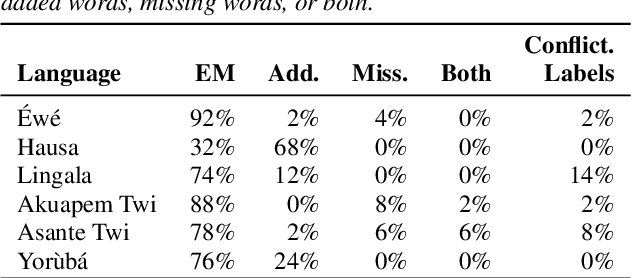
BibleTTS is a large, high-quality, open speech dataset for ten languages spoken in Sub-Saharan Africa. The corpus contains up to 86 hours of aligned, studio quality 48kHz single speaker recordings per language, enabling the development of high-quality text-to-speech models. The ten languages represented are: Akuapem Twi, Asante Twi, Chichewa, Ewe, Hausa, Kikuyu, Lingala, Luganda, Luo, and Yoruba. This corpus is a derivative work of Bible recordings made and released by the Open.Bible project from Biblica. We have aligned, cleaned, and filtered the original recordings, and additionally hand-checked a subset of the alignments for each language. We present results for text-to-speech models with Coqui TTS. The data is released under a commercial-friendly CC-BY-SA license.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
EdinSaar@WMT21: North-Germanic Low-Resource Multilingual NMT
Sep 29, 2021
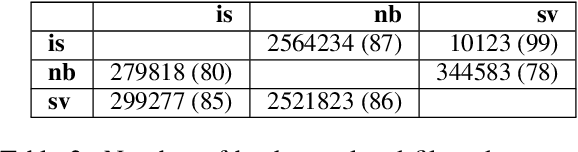
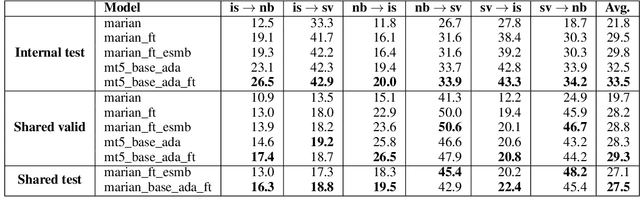
We describe the EdinSaar submission to the shared task of Multilingual Low-Resource Translation for North Germanic Languages at the Sixth Conference on Machine Translation (WMT2021). We submit multilingual translation models for translations to/from Icelandic (is), Norwegian-Bokmal (nb), and Swedish (sv). We employ various experimental approaches, including multilingual pre-training, back-translation, fine-tuning, and ensembling. In most translation directions, our models outperform other submitted systems.
UNIQORN: Unified Question Answering over RDF Knowledge Graphs and Natural Language Text
Aug 19, 2021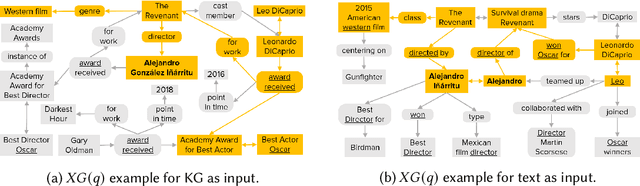
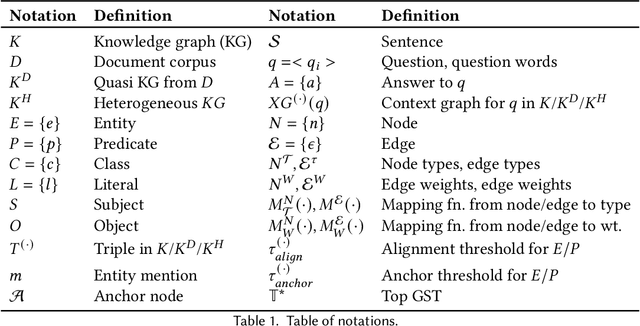
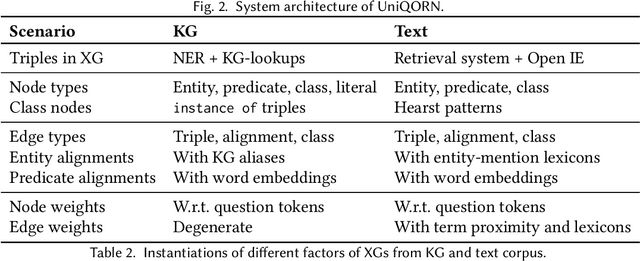
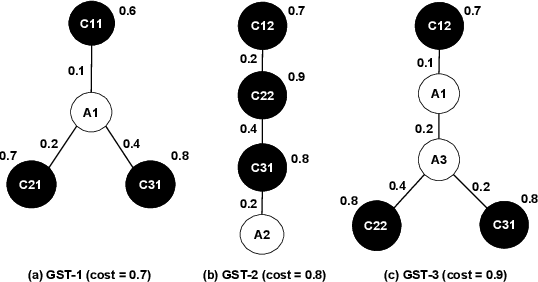
Question answering over knowledge graphs and other RDF data has been greatly advanced, with a number of good systems providing crisp answers for natural language questions or telegraphic queries. Some of these systems incorporate textual sources as additional evidence for the answering process, but cannot compute answers that are present in text alone. Conversely, systems from the IR and NLP communities have addressed QA over text, but barely utilize semantic data and knowledge. This paper presents the first QA system that can seamlessly operate over RDF datasets and text corpora, or both together, in a unified framework. Our method, called UNIQORN, builds a context graph on the fly, by retrieving question-relevant triples from the RDF data and/or the text corpus, where the latter case is handled by automatic information extraction. The resulting graph is typically rich but highly noisy. UNIQORN copes with this input by advanced graph algorithms for Group Steiner Trees, that identify the best answer candidates in the context graph. Experimental results on several benchmarks of complex questions with multiple entities and relations, show that UNIQORN, an unsupervised method with only five parameters, produces results comparable to the state-of-the-art on KGs, text corpora, and heterogeneous sources. The graph-based methodology provides user-interpretable evidence for the complete answering process.
MasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021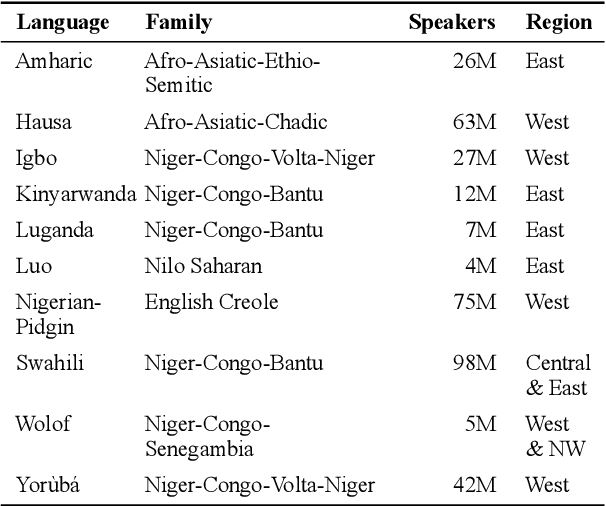

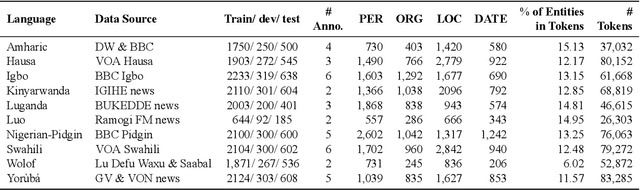
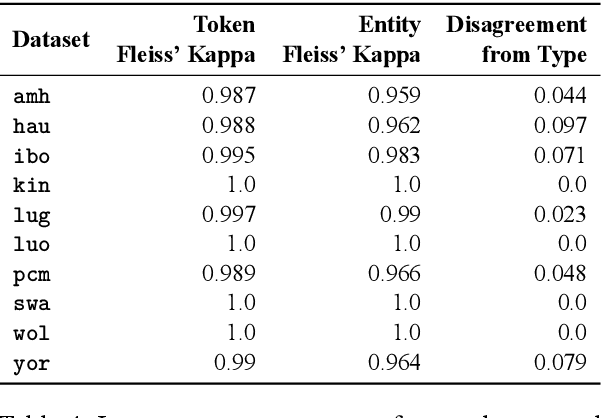
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.
Transfer Learning and Distant Supervision for Multilingual Transformer Models: A Study on African Languages
Oct 07, 2020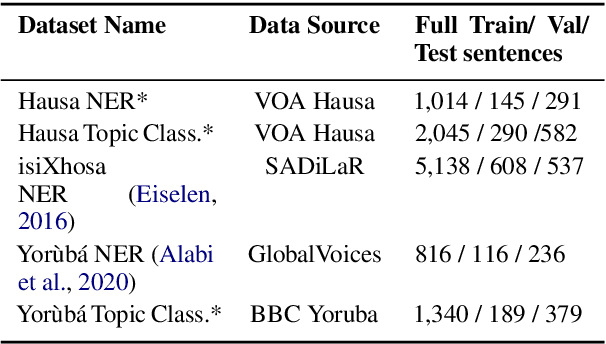
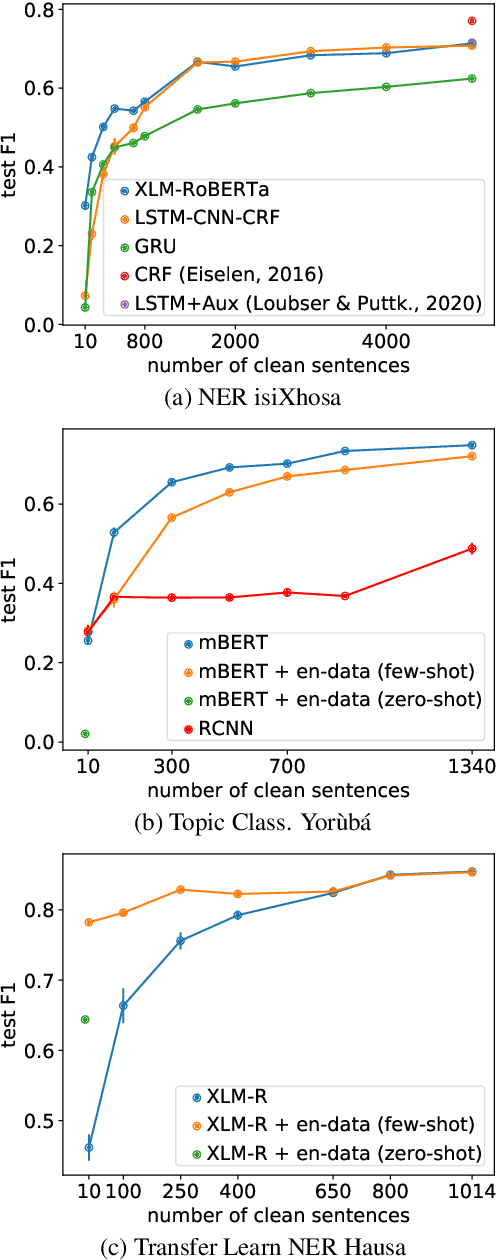
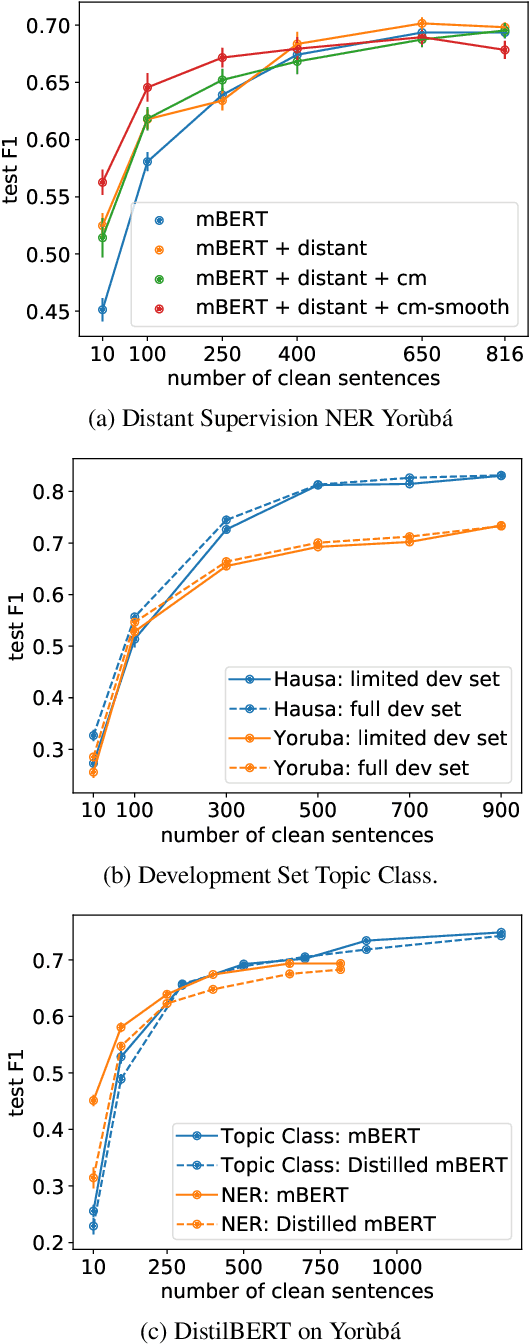
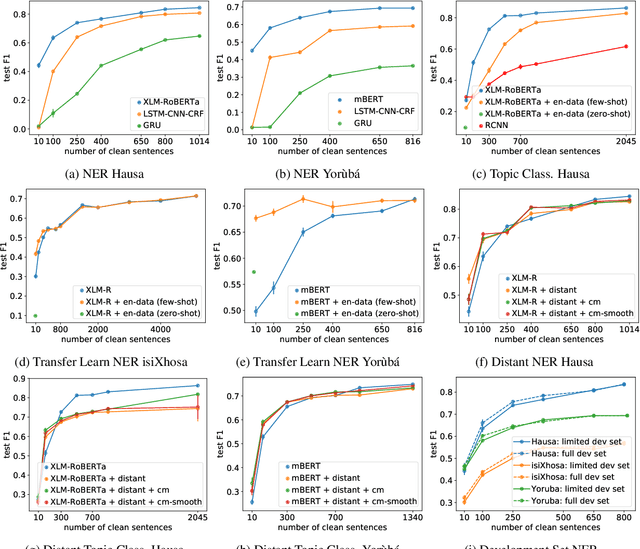
Multilingual transformer models like mBERT and XLM-RoBERTa have obtained great improvements for many NLP tasks on a variety of languages. However, recent works also showed that results from high-resource languages could not be easily transferred to realistic, low-resource scenarios. In this work, we study trends in performance for different amounts of available resources for the three African languages Hausa, isiXhosa and Yor\`ub\'a on both NER and topic classification. We show that in combination with transfer learning or distant supervision, these models can achieve with as little as 10 or 100 labeled sentences the same performance as baselines with much more supervised training data. However, we also find settings where this does not hold. Our discussions and additional experiments on assumptions such as time and hardware restrictions highlight challenges and opportunities in low-resource learning.