 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAwal -- Community-Powered Language Technology for Tamazight
Oct 31, 2025This paper presents Awal, a community-powered initiative for developing language technology resources for Tamazight. We provide a comprehensive review of the NLP landscape for Tamazight, examining recent progress in computational resources, and the emergence of community-driven approaches to address persistent data scarcity. Launched in 2024, awaldigital.org platform addresses the underrepresentation of Tamazight in digital spaces through a collaborative platform enabling speakers to contribute translation and voice data. We analyze 18 months of community engagement, revealing significant barriers to participation including limited confidence in written Tamazight and ongoing standardization challenges. Despite widespread positive reception, actual data contribution remained concentrated among linguists and activists. The modest scale of community contributions -- 6,421 translation pairs and 3 hours of speech data -- highlights the limitations of applying standard crowdsourcing approaches to languages with complex sociolinguistic contexts. We are working on improved open-source MT models using the collected data.
BibleTTS: a large, high-fidelity, multilingual, and uniquely African speech corpus
Jul 07, 2022
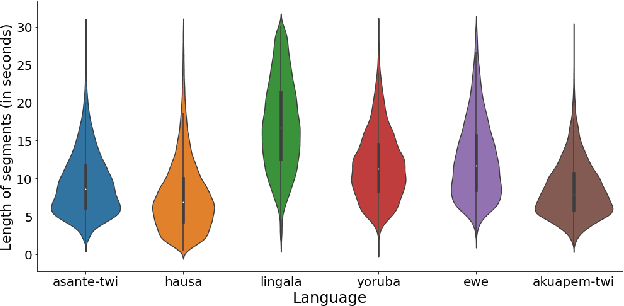

BibleTTS is a large, high-quality, open speech dataset for ten languages spoken in Sub-Saharan Africa. The corpus contains up to 86 hours of aligned, studio quality 48kHz single speaker recordings per language, enabling the development of high-quality text-to-speech models. The ten languages represented are: Akuapem Twi, Asante Twi, Chichewa, Ewe, Hausa, Kikuyu, Lingala, Luganda, Luo, and Yoruba. This corpus is a derivative work of Bible recordings made and released by the Open.Bible project from Biblica. We have aligned, cleaned, and filtered the original recordings, and additionally hand-checked a subset of the alignments for each language. We present results for text-to-speech models with Coqui TTS. The data is released under a commercial-friendly CC-BY-SA license.
Preparing an Endangered Language for the Digital Age: The Case of Judeo-Spanish
May 31, 2022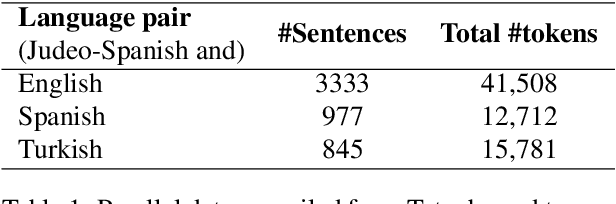

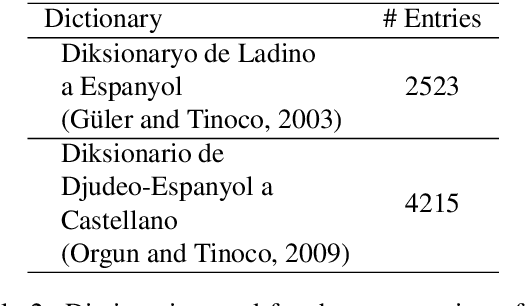

We develop machine translation and speech synthesis systems to complement the efforts of revitalizing Judeo-Spanish, the exiled language of Sephardic Jews, which survived for centuries, but now faces the threat of extinction in the digital age. Building on resources created by the Sephardic community of Turkey and elsewhere, we create corpora and tools that would help preserve this language for future generations. For machine translation, we first develop a Spanish to Judeo-Spanish rule-based machine translation system, in order to generate large volumes of synthetic parallel data in the relevant language pairs: Turkish, English and Spanish. Then, we train baseline neural machine translation engines using this synthetic data and authentic parallel data created from translations by the Sephardic community. For text-to-speech synthesis, we present a 3.5 hour single speaker speech corpus for building a neural speech synthesis engine. Resources, model weights and online inference engines are shared publicly.
Congolese Swahili Machine Translation for Humanitarian Response
Mar 19, 2021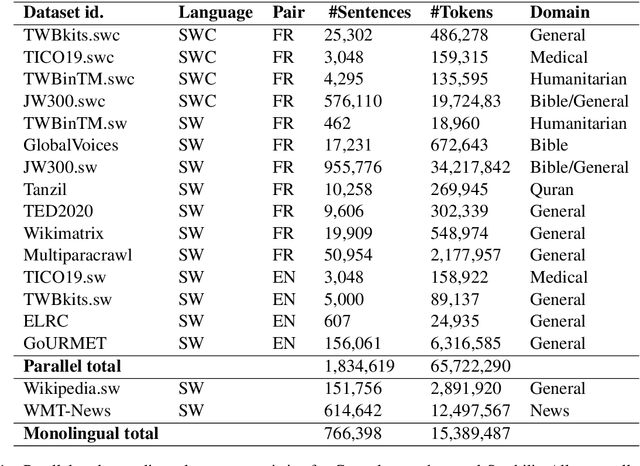
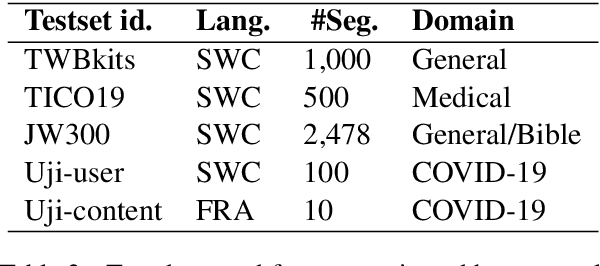
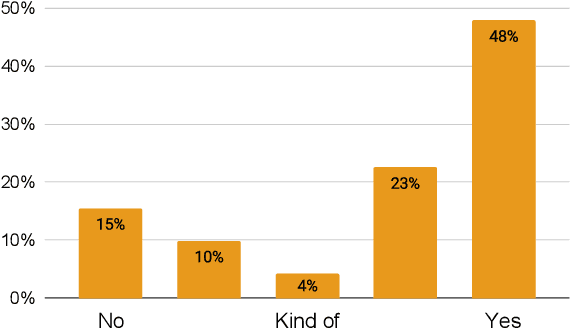
In this paper we describe our efforts to make a bidirectional Congolese Swahili (SWC) to French (FRA) neural machine translation system with the motivation of improving humanitarian translation workflows. For training, we created a 25,302-sentence general domain parallel corpus and combined it with publicly available data. Experimenting with low-resource methodologies like cross-dialect transfer and semi-supervised learning, we recorded improvements of up to 2.4 and 3.5 BLEU points in the SWC-FRA and FRA-SWC directions, respectively. We performed human evaluations to assess the usability of our models in a COVID-domain chatbot that operates in the Democratic Republic of Congo (DRC). Direct assessment in the SWC-FRA direction demonstrated an average quality ranking of 6.3 out of 10 with 75% of the target strings conveying the main message of the source text. For the FRA-SWC direction, our preliminary tests on post-editing assessment showed its potential usefulness for machine-assisted translation. We make our models, datasets containing up to 1 million sentences, our development pipeline, and a translator web-app available for public use.
Participatory Research for Low-resourced Machine Translation: A Case Study in African Languages
Oct 05, 2020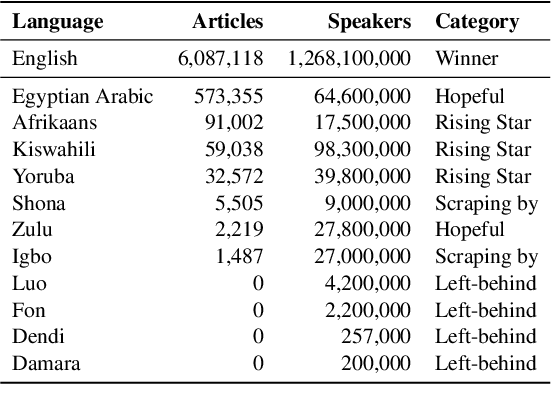
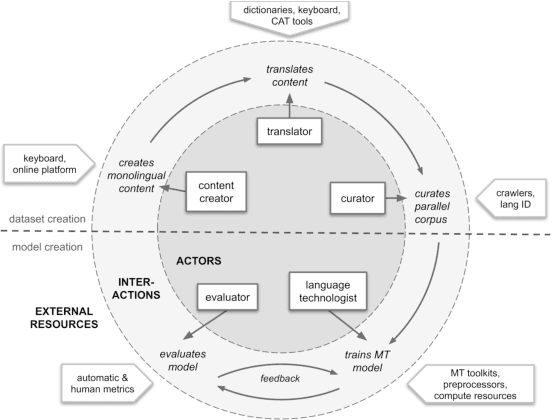
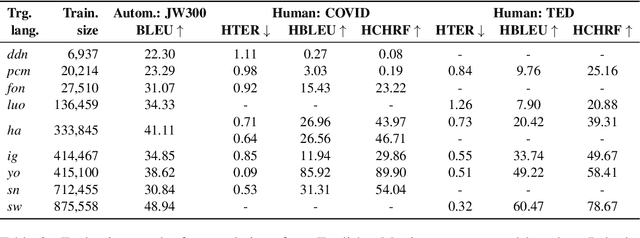
Research in NLP lacks geographic diversity, and the question of how NLP can be scaled to low-resourced languages has not yet been adequately solved. "Low-resourced"-ness is a complex problem going beyond data availability and reflects systemic problems in society. In this paper, we focus on the task of Machine Translation (MT), that plays a crucial role for information accessibility and communication worldwide. Despite immense improvements in MT over the past decade, MT is centered around a few high-resourced languages. As MT researchers cannot solve the problem of low-resourcedness alone, we propose participatory research as a means to involve all necessary agents required in the MT development process. We demonstrate the feasibility and scalability of participatory research with a case study on MT for African languages. Its implementation leads to a collection of novel translation datasets, MT benchmarks for over 30 languages, with human evaluations for a third of them, and enables participants without formal training to make a unique scientific contribution. Benchmarks, models, data, code, and evaluation results are released under https://github.com/masakhane-io/masakhane-mt.
TICO-19: the Translation Initiative for Covid-19
Jul 06, 2020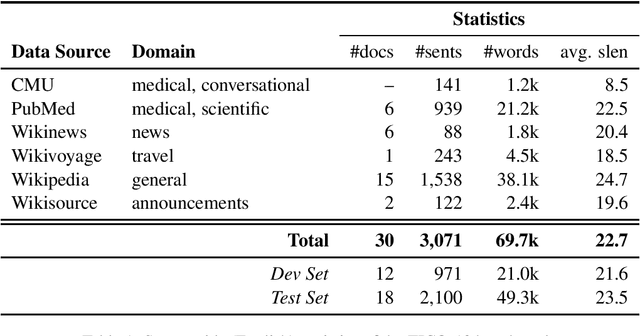
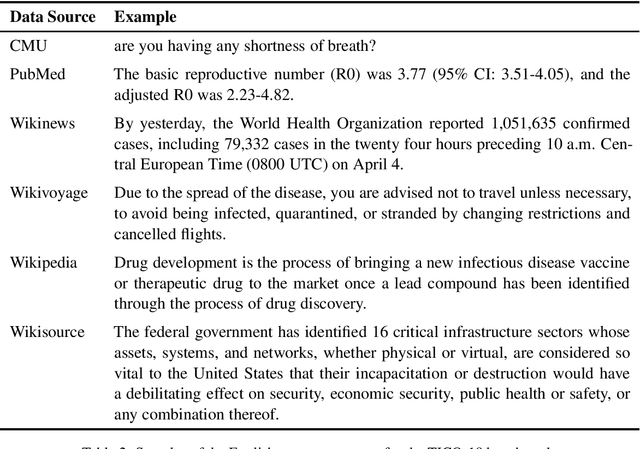
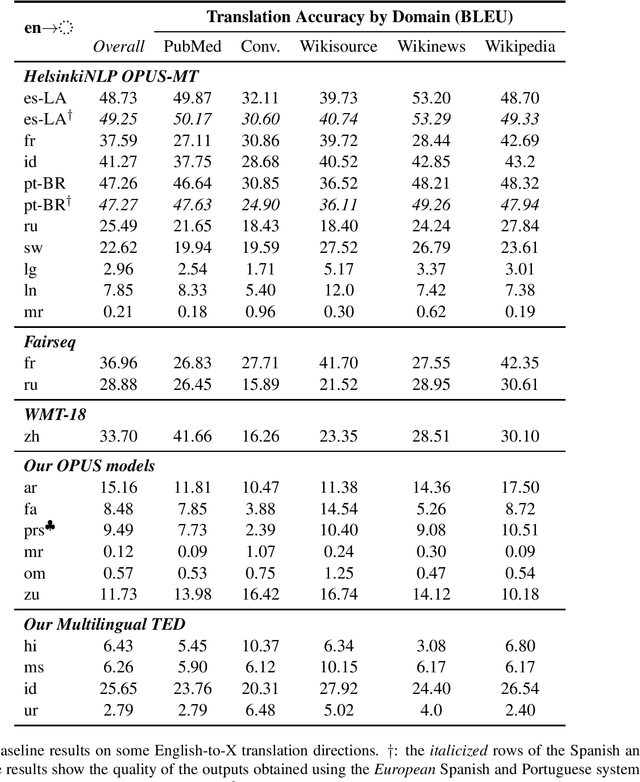
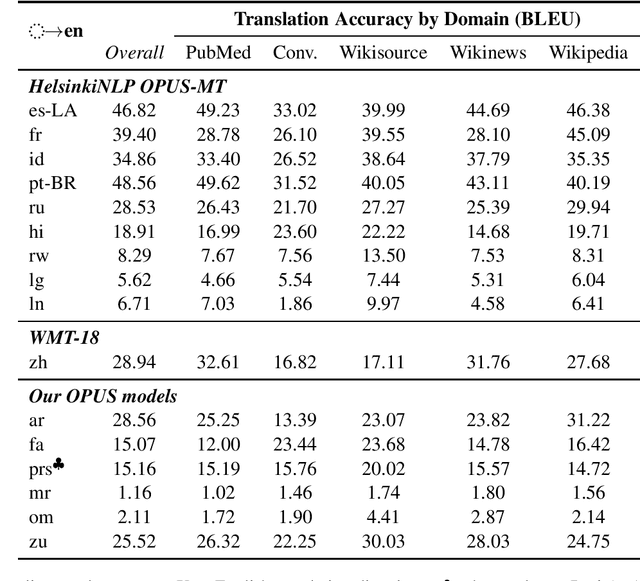
The COVID-19 pandemic is the worst pandemic to strike the world in over a century. Crucial to stemming the tide of the SARS-CoV-2 virus is communicating to vulnerable populations the means by which they can protect themselves. To this end, the collaborators forming the Translation Initiative for COvid-19 (TICO-19) have made test and development data available to AI and MT researchers in 35 different languages in order to foster the development of tools and resources for improving access to information about COVID-19 in these languages. In addition to 9 high-resourced, "pivot" languages, the team is targeting 26 lesser resourced languages, in particular languages of Africa, South Asia and South-East Asia, whose populations may be the most vulnerable to the spread of the virus. The same data is translated into all of the languages represented, meaning that testing or development can be done for any pairing of languages in the set. Further, the team is converting the test and development data into translation memories (TMXs) that can be used by localizers from and to any of the languages.
Masakhane -- Machine Translation For Africa
Mar 13, 2020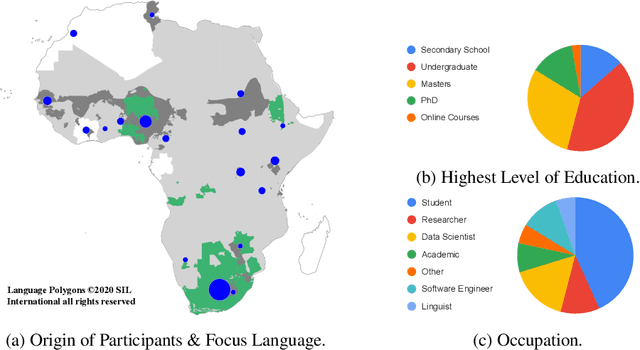
Africa has over 2000 languages. Despite this, African languages account for a small portion of available resources and publications in Natural Language Processing (NLP). This is due to multiple factors, including: a lack of focus from government and funding, discoverability, a lack of community, sheer language complexity, difficulty in reproducing papers and no benchmarks to compare techniques. To begin to address the identified problems, MASAKHANE, an open-source, continent-wide, distributed, online research effort for machine translation for African languages, was founded. In this paper, we discuss our methodology for building the community and spurring research from the African continent, as well as outline the success of the community in terms of addressing the identified problems affecting African NLP.
Tigrinya Neural Machine Translation with Transfer Learning for Humanitarian Response
Mar 09, 2020
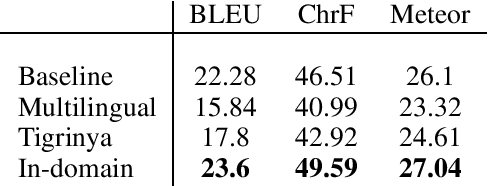
We report our experiments in building a domain-specific Tigrinya-to-English neural machine translation system. We use transfer learning from other Ge'ez script languages and report an improvement of 1.3 BLEU points over a classic neural baseline. We publish our development pipeline as an open-source library and also provide a demonstration application.
Prosodic Phrase Alignment for Machine Dubbing
Aug 20, 2019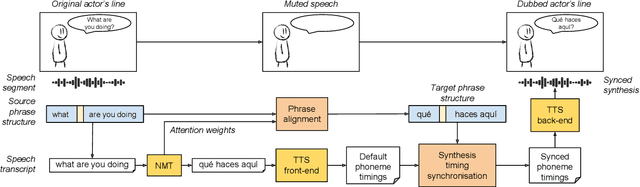

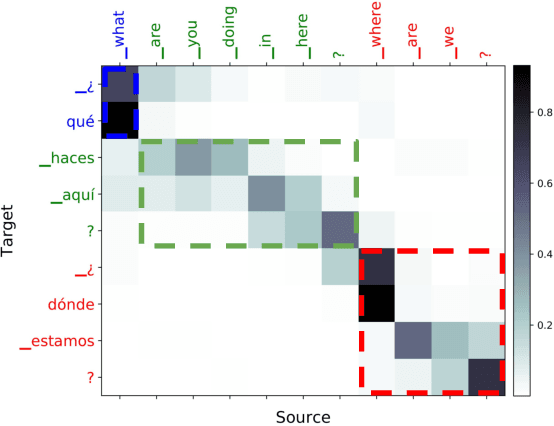
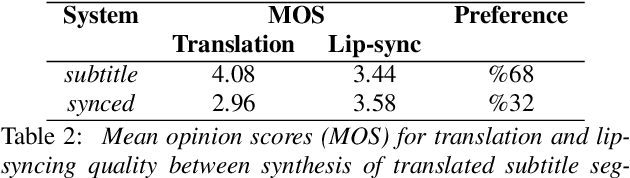
Dubbing is a type of audiovisual translation where dialogues are translated and enacted so that they give the impression that the media is in the target language. It requires a careful alignment of dubbed recordings with the lip movements of performers in order to achieve visual coherence. In this paper, we deal with the specific problem of prosodic phrase synchronization within the framework of machine dubbing. Our methodology exploits the attention mechanism output in neural machine translation to find plausible phrasing for the translated dialogue lines and then uses them to condition their synthesis. Our initial work in this field records comparable speech rate ratio to professional dubbing translation, and improvement in terms of lip-syncing of long dialogue lines.