 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKALIE: Fine-Tuning Vision-Language Models for Open-World Manipulation without Robot Data
Sep 21, 2024
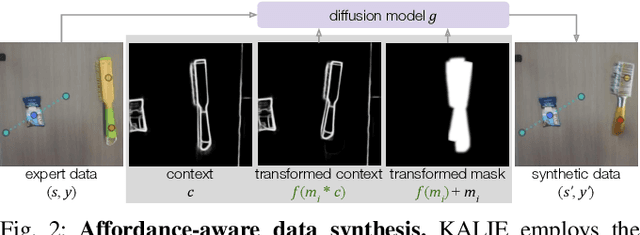


Building generalist robotic systems involves effectively endowing robots with the capabilities to handle novel objects in an open-world setting. Inspired by the advances of large pre-trained models, we propose Keypoint Affordance Learning from Imagined Environments (KALIE), which adapts pre-trained Vision Language Models (VLMs) for robotic control in a scalable manner. Instead of directly producing motor commands, KALIE controls the robot by predicting point-based affordance representations based on natural language instructions and visual observations of the scene. The VLM is trained on 2D images with affordances labeled by humans, bypassing the need for training data collected on robotic systems. Through an affordance-aware data synthesis pipeline, KALIE automatically creates massive high-quality training data based on limited example data manually collected by humans. We demonstrate that KALIE can learn to robustly solve new manipulation tasks with unseen objects given only 50 example data points. Compared to baselines using pre-trained VLMs, our approach consistently achieves superior performance.
Congolese Swahili Machine Translation for Humanitarian Response
Mar 19, 2021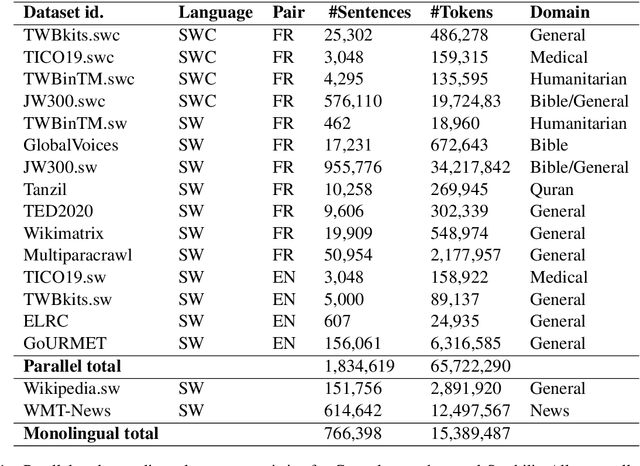
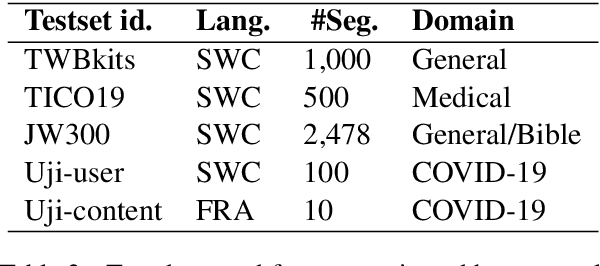
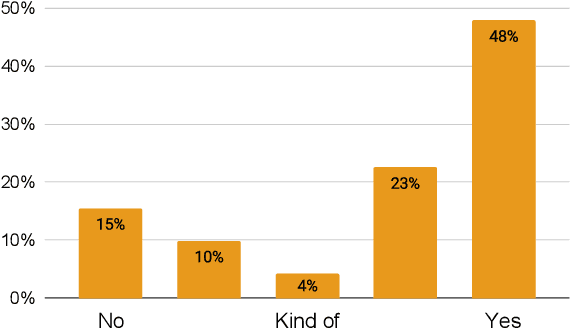
In this paper we describe our efforts to make a bidirectional Congolese Swahili (SWC) to French (FRA) neural machine translation system with the motivation of improving humanitarian translation workflows. For training, we created a 25,302-sentence general domain parallel corpus and combined it with publicly available data. Experimenting with low-resource methodologies like cross-dialect transfer and semi-supervised learning, we recorded improvements of up to 2.4 and 3.5 BLEU points in the SWC-FRA and FRA-SWC directions, respectively. We performed human evaluations to assess the usability of our models in a COVID-domain chatbot that operates in the Democratic Republic of Congo (DRC). Direct assessment in the SWC-FRA direction demonstrated an average quality ranking of 6.3 out of 10 with 75% of the target strings conveying the main message of the source text. For the FRA-SWC direction, our preliminary tests on post-editing assessment showed its potential usefulness for machine-assisted translation. We make our models, datasets containing up to 1 million sentences, our development pipeline, and a translator web-app available for public use.
TICO-19: the Translation Initiative for Covid-19
Jul 06, 2020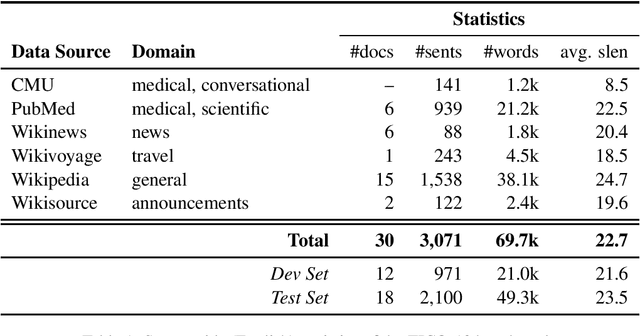
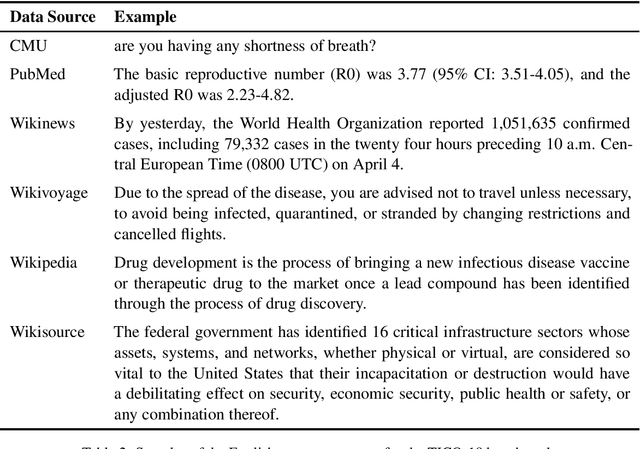
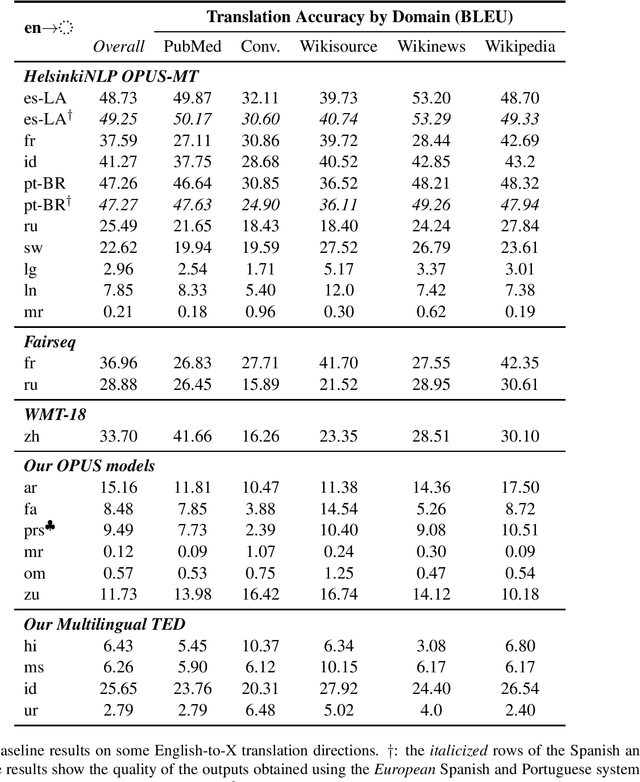
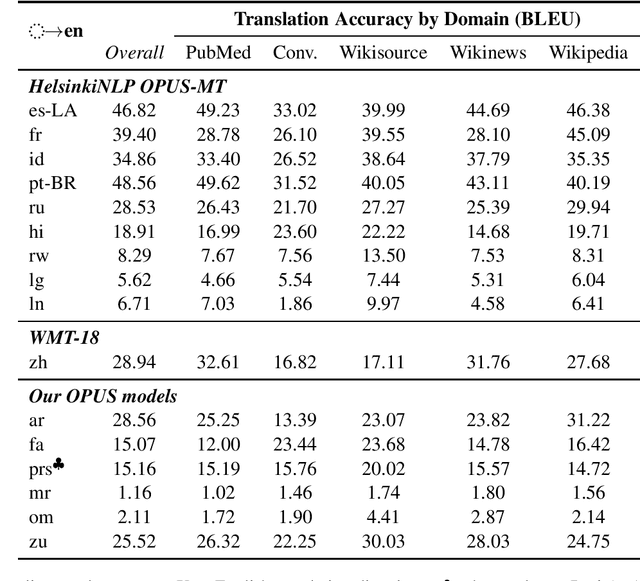
The COVID-19 pandemic is the worst pandemic to strike the world in over a century. Crucial to stemming the tide of the SARS-CoV-2 virus is communicating to vulnerable populations the means by which they can protect themselves. To this end, the collaborators forming the Translation Initiative for COvid-19 (TICO-19) have made test and development data available to AI and MT researchers in 35 different languages in order to foster the development of tools and resources for improving access to information about COVID-19 in these languages. In addition to 9 high-resourced, "pivot" languages, the team is targeting 26 lesser resourced languages, in particular languages of Africa, South Asia and South-East Asia, whose populations may be the most vulnerable to the spread of the virus. The same data is translated into all of the languages represented, meaning that testing or development can be done for any pairing of languages in the set. Further, the team is converting the test and development data into translation memories (TMXs) that can be used by localizers from and to any of the languages.
Tigrinya Neural Machine Translation with Transfer Learning for Humanitarian Response
Mar 09, 2020
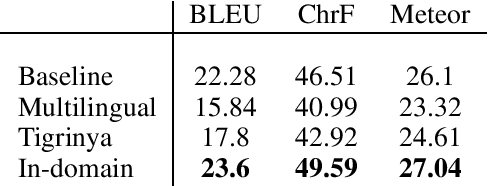
We report our experiments in building a domain-specific Tigrinya-to-English neural machine translation system. We use transfer learning from other Ge'ez script languages and report an improvement of 1.3 BLEU points over a classic neural baseline. We publish our development pipeline as an open-source library and also provide a demonstration application.