 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Self-Taught Faithfulness Evaluators
Jul 28, 2025The growing use of large language models (LLMs) has increased the need for automatic evaluation systems, particularly to address the challenge of information hallucination. Although existing faithfulness evaluation approaches have shown promise, they are predominantly English-focused and often require expensive human-labeled training data for fine-tuning specialized models. As LLMs see increased adoption in multilingual contexts, there is a need for accurate faithfulness evaluators that can operate across languages without extensive labeled data. This paper presents Self-Taught Evaluators for Multilingual Faithfulness, a framework that learns exclusively from synthetic multilingual summarization data while leveraging cross-lingual transfer learning. Through experiments comparing language-specific and mixed-language fine-tuning approaches, we demonstrate a consistent relationship between an LLM's general language capabilities and its performance in language-specific evaluation tasks. Our framework shows improvements over existing baselines, including state-of-the-art English evaluators and machine translation-based approaches.
MEMERAG: A Multilingual End-to-End Meta-Evaluation Benchmark for Retrieval Augmented Generation
Feb 25, 2025Automatic evaluation of retrieval augmented generation (RAG) systems relies on fine-grained dimensions like faithfulness and relevance, as judged by expert human annotators. Meta-evaluation benchmarks support the development of automatic evaluators that correlate well with human judgement. However, existing benchmarks predominantly focus on English or use translated data, which fails to capture cultural nuances. A native approach provides a better representation of the end user experience. In this work, we develop a Multilingual End-to-end Meta-Evaluation RAG benchmark (MEMERAG). Our benchmark builds on the popular MIRACL dataset, using native-language questions and generating responses with diverse large language models (LLMs), which are then assessed by expert annotators for faithfulness and relevance. We describe our annotation process and show that it achieves high inter-annotator agreement. We then analyse the performance of the answer-generating LLMs across languages as per the human evaluators. Finally we apply the dataset to our main use-case which is to benchmark multilingual automatic evaluators (LLM-as-a-judge). We show that our benchmark can reliably identify improvements offered by advanced prompting techniques and LLMs. We will release our benchmark to support the community developing accurate evaluation methods for multilingual RAG systems.
Findings of the IWSLT 2024 Evaluation Campaign
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
PEAVS: Perceptual Evaluation of Audio-Visual Synchrony Grounded in Viewers' Opinion Scores
Apr 10, 2024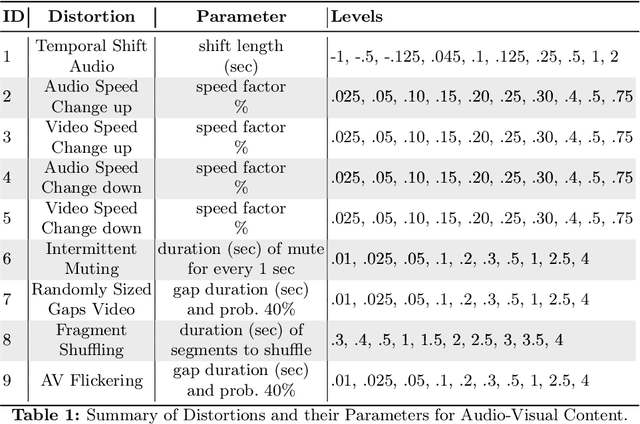
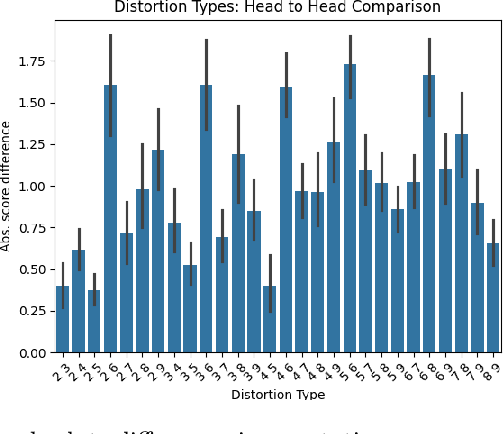
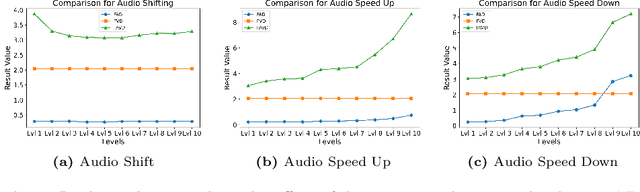
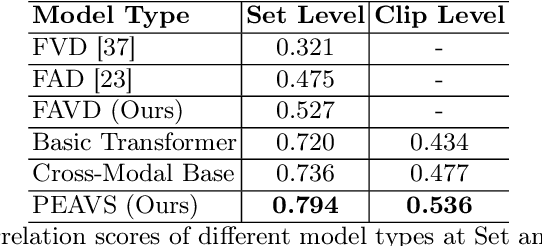
Recent advancements in audio-visual generative modeling have been propelled by progress in deep learning and the availability of data-rich benchmarks. However, the growth is not attributed solely to models and benchmarks. Universally accepted evaluation metrics also play an important role in advancing the field. While there are many metrics available to evaluate audio and visual content separately, there is a lack of metrics that offer a quantitative and interpretable measure of audio-visual synchronization for videos "in the wild". To address this gap, we first created a large scale human annotated dataset (100+ hrs) representing nine types of synchronization errors in audio-visual content and how human perceive them. We then developed a PEAVS (Perceptual Evaluation of Audio-Visual Synchrony) score, a novel automatic metric with a 5-point scale that evaluates the quality of audio-visual synchronization. We validate PEAVS using a newly generated dataset, achieving a Pearson correlation of 0.79 at the set level and 0.54 at the clip level when compared to human labels. In our experiments, we observe a relative gain 50% over a natural extension of Fr\'echet based metrics for Audio-Visual synchrony, confirming PEAVS efficacy in objectively modeling subjective perceptions of audio-visual synchronization for videos "in the wild".
A Shocking Amount of the Web is Machine Translated: Insights from Multi-Way Parallelism
Jan 11, 2024
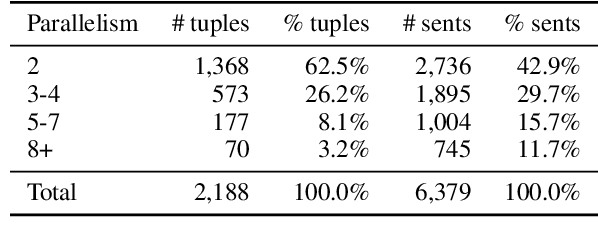
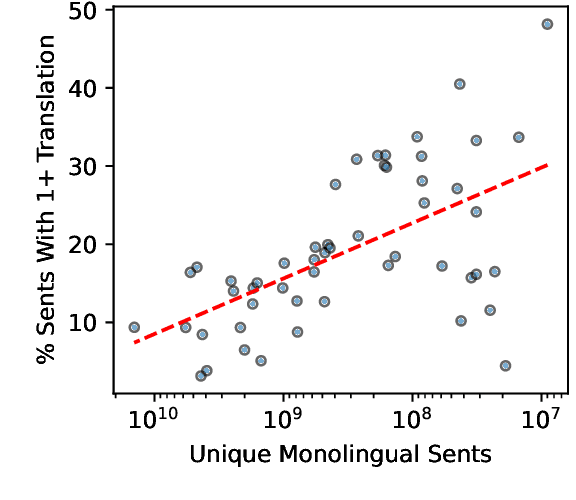

We show that content on the web is often translated into many languages, and the low quality of these multi-way translations indicates they were likely created using Machine Translation (MT). Multi-way parallel, machine generated content not only dominates the translations in lower resource languages; it also constitutes a large fraction of the total web content in those languages. We also find evidence of a selection bias in the type of content which is translated into many languages, consistent with low quality English content being translated en masse into many lower resource languages, via MT. Our work raises serious concerns about training models such as multilingual large language models on both monolingual and bilingual data scraped from the web.
End-to-End Single-Channel Speaker-Turn Aware Conversational Speech Translation
Nov 01, 2023



Conventional speech-to-text translation (ST) systems are trained on single-speaker utterances, and they may not generalize to real-life scenarios where the audio contains conversations by multiple speakers. In this paper, we tackle single-channel multi-speaker conversational ST with an end-to-end and multi-task training model, named Speaker-Turn Aware Conversational Speech Translation, that combines automatic speech recognition, speech translation and speaker turn detection using special tokens in a serialized labeling format. We run experiments on the Fisher-CALLHOME corpus, which we adapted by merging the two single-speaker channels into one multi-speaker channel, thus representing the more realistic and challenging scenario with multi-speaker turns and cross-talk. Experimental results across single- and multi-speaker conditions and against conventional ST systems, show that our model outperforms the reference systems on the multi-speaker condition, while attaining comparable performance on the single-speaker condition. We release scripts for data processing and model training.
Speaker Diarization of Scripted Audiovisual Content
Aug 04, 2023

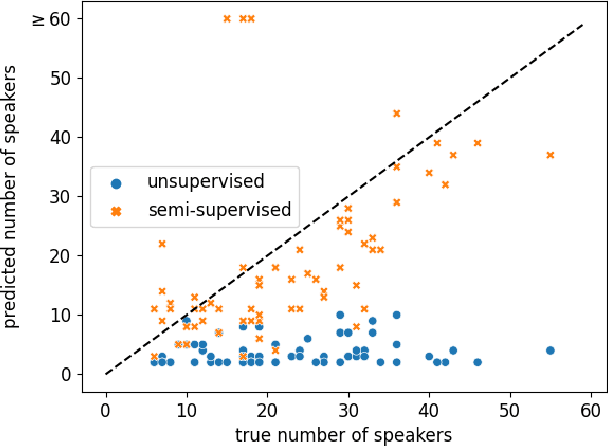
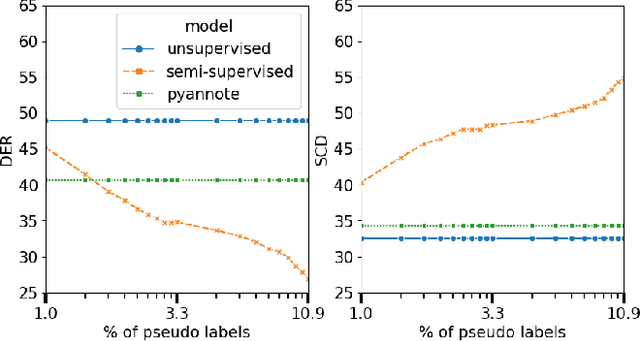
The media localization industry usually requires a verbatim script of the final film or TV production in order to create subtitles or dubbing scripts in a foreign language. In particular, the verbatim script (i.e. as-broadcast script) must be structured into a sequence of dialogue lines each including time codes, speaker name and transcript. Current speech recognition technology alleviates the transcription step. However, state-of-the-art speaker diarization models still fall short on TV shows for two main reasons: (i) their inability to track a large number of speakers, (ii) their low accuracy in detecting frequent speaker changes. To mitigate this problem, we present a novel approach to leverage production scripts used during the shooting process, to extract pseudo-labeled data for the speaker diarization task. We propose a novel semi-supervised approach and demonstrate improvements of 51.7% relative to two unsupervised baseline models on our metrics on a 66 show test set.
Improving Isochronous Machine Translation with Target Factors and Auxiliary Counters
May 22, 2023



To translate speech for automatic dubbing, machine translation needs to be isochronous, i.e. translated speech needs to be aligned with the source in terms of speech durations. We introduce target factors in a transformer model to predict durations jointly with target language phoneme sequences. We also introduce auxiliary counters to help the decoder to keep track of the timing information while generating target phonemes. We show that our model improves translation quality and isochrony compared to previous work where the translation model is instead trained to predict interleaved sequences of phonemes and durations.
Jointly Optimizing Translations and Speech Timing to Improve Isochrony in Automatic Dubbing
Feb 25, 2023



Automatic dubbing (AD) is the task of translating the original speech in a video into target language speech. The new target language speech should satisfy isochrony; that is, the new speech should be time aligned with the original video, including mouth movements, pauses, hand gestures, etc. In this paper, we propose training a model that directly optimizes both the translation as well as the speech duration of the generated translations. We show that this system generates speech that better matches the timing of the original speech, compared to prior work, while simplifying the system architecture.
Improving Robustness of Retrieval Augmented Translation via Shuffling of Suggestions
Oct 11, 2022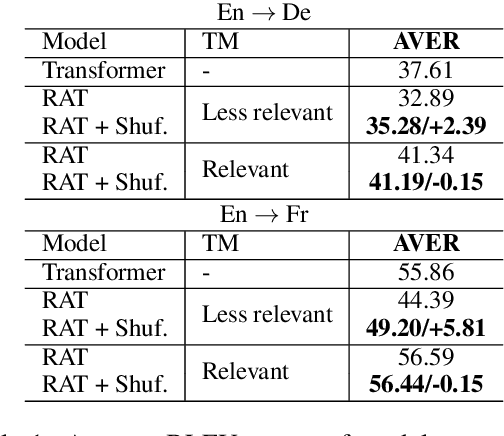
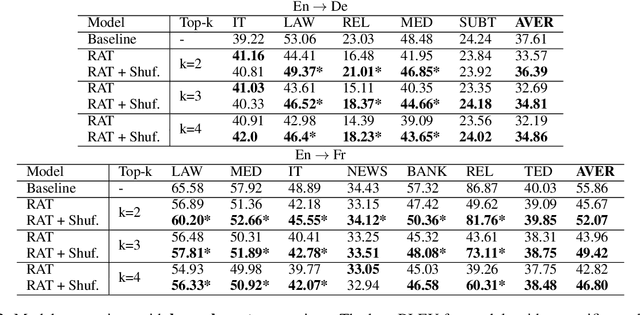
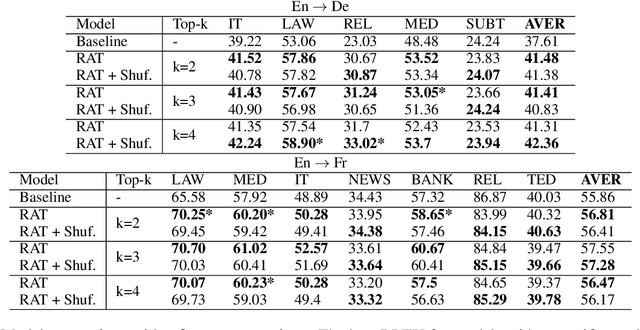

Several recent studies have reported dramatic performance improvements in neural machine translation (NMT) by augmenting translation at inference time with fuzzy-matches retrieved from a translation memory (TM). However, these studies all operate under the assumption that the TMs available at test time are highly relevant to the testset. We demonstrate that for existing retrieval augmented translation methods, using a TM with a domain mismatch to the test set can result in substantially worse performance compared to not using a TM at all. We propose a simple method to expose fuzzy-match NMT systems during training and show that it results in a system that is much more tolerant (regaining up to 5.8 BLEU) to inference with TMs with domain mismatch. Also, the model is still competitive to the baseline when fed with suggestions from relevant TMs.