 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Lip-synchrony in Direct Audio-Visual Speech-to-Speech Translation
Dec 21, 2024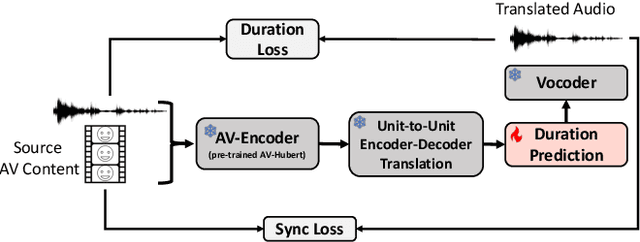



Audio-Visual Speech-to-Speech Translation typically prioritizes improving translation quality and naturalness. However, an equally critical aspect in audio-visual content is lip-synchrony-ensuring that the movements of the lips match the spoken content-essential for maintaining realism in dubbed videos. Despite its importance, the inclusion of lip-synchrony constraints in AVS2S models has been largely overlooked. This study addresses this gap by integrating a lip-synchrony loss into the training process of AVS2S models. Our proposed method significantly enhances lip-synchrony in direct audio-visual speech-to-speech translation, achieving an average LSE-D score of 10.67, representing a 9.2% reduction in LSE-D over a strong baseline across four language pairs. Additionally, it maintains the naturalness and high quality of the translated speech when overlaid onto the original video, without any degradation in translation quality.
PEAVS: Perceptual Evaluation of Audio-Visual Synchrony Grounded in Viewers' Opinion Scores
Apr 10, 2024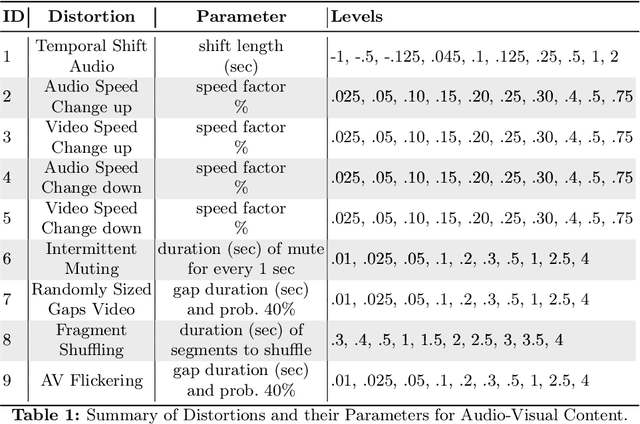
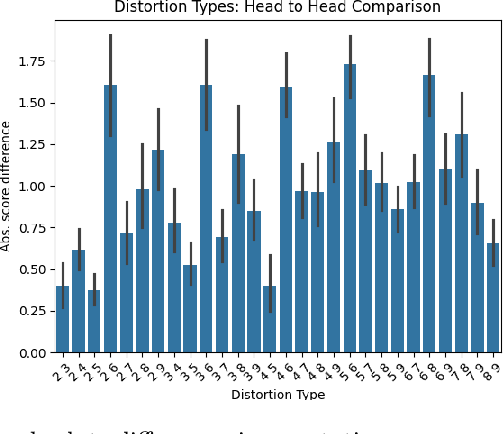
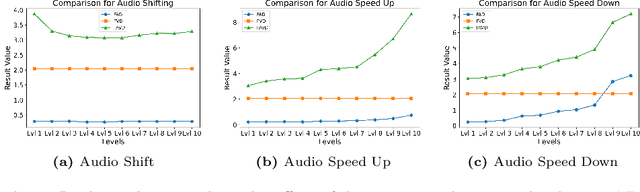
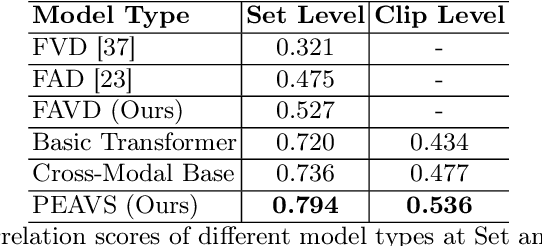
Recent advancements in audio-visual generative modeling have been propelled by progress in deep learning and the availability of data-rich benchmarks. However, the growth is not attributed solely to models and benchmarks. Universally accepted evaluation metrics also play an important role in advancing the field. While there are many metrics available to evaluate audio and visual content separately, there is a lack of metrics that offer a quantitative and interpretable measure of audio-visual synchronization for videos "in the wild". To address this gap, we first created a large scale human annotated dataset (100+ hrs) representing nine types of synchronization errors in audio-visual content and how human perceive them. We then developed a PEAVS (Perceptual Evaluation of Audio-Visual Synchrony) score, a novel automatic metric with a 5-point scale that evaluates the quality of audio-visual synchronization. We validate PEAVS using a newly generated dataset, achieving a Pearson correlation of 0.79 at the set level and 0.54 at the clip level when compared to human labels. In our experiments, we observe a relative gain 50% over a natural extension of Fr\'echet based metrics for Audio-Visual synchrony, confirming PEAVS efficacy in objectively modeling subjective perceptions of audio-visual synchronization for videos "in the wild".
Deep Submodular Networks for Extractive Data Summarization
Oct 16, 2020
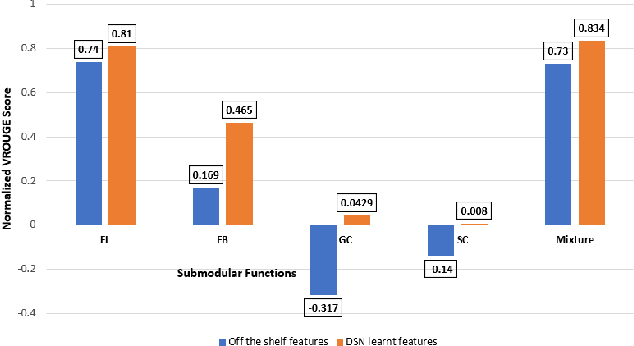
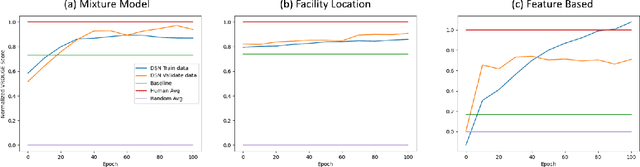
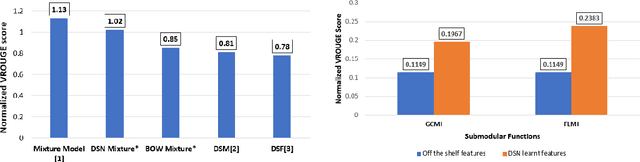
Deep Models are increasingly becoming prevalent in summarization problems (e.g. document, video and images) due to their ability to learn complex feature interactions and representations. However, they do not model characteristics such as diversity, representation, and coverage, which are also very important for summarization tasks. On the other hand, submodular functions naturally model these characteristics because of their diminishing returns property. Most approaches for modelling and learning submodular functions rely on very simple models, such as weighted mixtures of submodular functions. Unfortunately, these models only learn the relative importance of the different submodular functions (such as diversity, representation or importance), but cannot learn more complex feature representations, which are often required for state-of-the-art performance. We propose Deep Submodular Networks (DSN), an end-to-end learning framework that facilitates the learning of more complex features and richer functions, crafted for better modelling of all aspects of summarization. The DSN framework can be used to learn features appropriate for summarization from scratch. We demonstrate the utility of DSNs on both generic and query focused image-collection summarization, and show significant improvement over the state-of-the-art. In particular, we show that DSNs outperform simple mixture models using off the shelf features. Secondly, we also show that just using four submodular functions in a DSN with end-to-end learning performs comparably to the state-of-the-art mixture model with a hand-crafted set of 594 components and outperforms other methods for image collection summarization.