 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Lip-synchrony in Direct Audio-Visual Speech-to-Speech Translation
Dec 21, 2024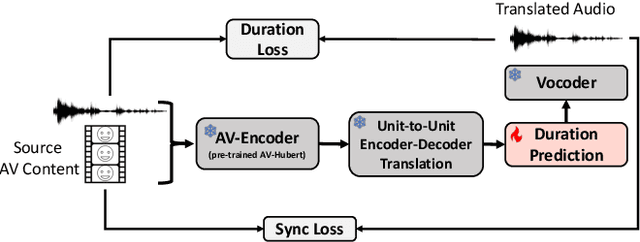



Audio-Visual Speech-to-Speech Translation typically prioritizes improving translation quality and naturalness. However, an equally critical aspect in audio-visual content is lip-synchrony-ensuring that the movements of the lips match the spoken content-essential for maintaining realism in dubbed videos. Despite its importance, the inclusion of lip-synchrony constraints in AVS2S models has been largely overlooked. This study addresses this gap by integrating a lip-synchrony loss into the training process of AVS2S models. Our proposed method significantly enhances lip-synchrony in direct audio-visual speech-to-speech translation, achieving an average LSE-D score of 10.67, representing a 9.2% reduction in LSE-D over a strong baseline across four language pairs. Additionally, it maintains the naturalness and high quality of the translated speech when overlaid onto the original video, without any degradation in translation quality.
DFlow: Diverse Dialogue Flow Simulation with Large Language Models
Oct 18, 2024Developing language model-based dialogue agents requires effective data to train models that can follow specific task logic. However, most existing data augmentation methods focus on increasing diversity in language, topics, or dialogue acts at the utterance level, largely neglecting a critical aspect of task logic diversity at the dialogue level. This paper proposes a novel data augmentation method designed to enhance the diversity of synthetic dialogues by focusing on task execution logic. Our method uses LLMs to generate decision tree-structured task plans, which enables the derivation of diverse dialogue trajectories for a given task. Each trajectory, referred to as a "dialog flow", guides the generation of a multi-turn dialogue that follows a unique trajectory. We apply this method to generate a task-oriented dialogue dataset comprising 3,886 dialogue flows across 15 different domains. We validate the effectiveness of this dataset using the next action prediction task, where models fine-tuned on our dataset outperform strong baselines, including GPT-4. Upon acceptance of this paper, we plan to release the code and data publicly.
TofuEval: Evaluating Hallucinations of LLMs on Topic-Focused Dialogue Summarization
Feb 20, 2024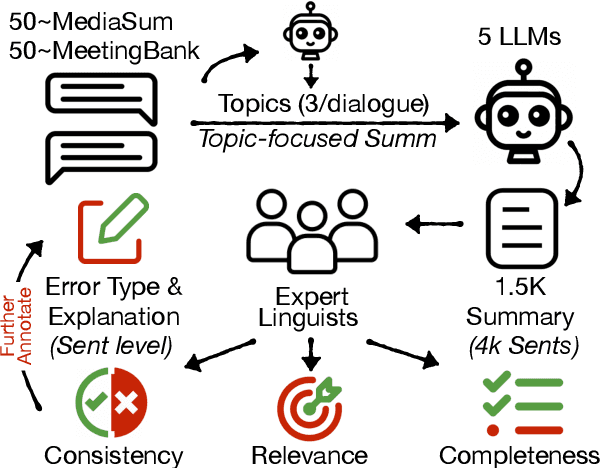


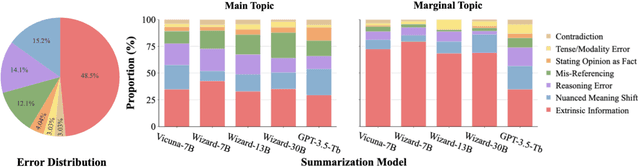
Single document news summarization has seen substantial progress on faithfulness in recent years, driven by research on the evaluation of factual consistency, or hallucinations. We ask whether these advances carry over to other text summarization domains. We propose a new evaluation benchmark on topic-focused dialogue summarization, generated by LLMs of varying sizes. We provide binary sentence-level human annotations of the factual consistency of these summaries along with detailed explanations of factually inconsistent sentences. Our analysis shows that existing LLMs hallucinate significant amounts of factual errors in the dialogue domain, regardless of the model's size. On the other hand, when LLMs, including GPT-4, serve as binary factual evaluators, they perform poorly and can be outperformed by prevailing state-of-the-art specialized factuality evaluation metrics. Finally, we conducted an analysis of hallucination types with a curated error taxonomy. We find that there are diverse errors and error distributions in model-generated summaries and that non-LLM based metrics can capture all error types better than LLM-based evaluators.