 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFlow: Diverse Dialogue Flow Simulation with Large Language Models
Oct 18, 2024Developing language model-based dialogue agents requires effective data to train models that can follow specific task logic. However, most existing data augmentation methods focus on increasing diversity in language, topics, or dialogue acts at the utterance level, largely neglecting a critical aspect of task logic diversity at the dialogue level. This paper proposes a novel data augmentation method designed to enhance the diversity of synthetic dialogues by focusing on task execution logic. Our method uses LLMs to generate decision tree-structured task plans, which enables the derivation of diverse dialogue trajectories for a given task. Each trajectory, referred to as a "dialog flow", guides the generation of a multi-turn dialogue that follows a unique trajectory. We apply this method to generate a task-oriented dialogue dataset comprising 3,886 dialogue flows across 15 different domains. We validate the effectiveness of this dataset using the next action prediction task, where models fine-tuned on our dataset outperform strong baselines, including GPT-4. Upon acceptance of this paper, we plan to release the code and data publicly.
Structured List-Grounded Question Answering
Oct 04, 2024Document-grounded dialogue systems aim to answer user queries by leveraging external information. Previous studies have mainly focused on handling free-form documents, often overlooking structured data such as lists, which can represent a range of nuanced semantic relations. Motivated by the observation that even advanced language models like GPT-3.5 often miss semantic cues from lists, this paper aims to enhance question answering (QA) systems for better interpretation and use of structured lists. To this end, we introduce the LIST2QA dataset, a novel benchmark to evaluate the ability of QA systems to respond effectively using list information. This dataset is created from unlabeled customer service documents using language models and model-based filtering processes to enhance data quality, and can be used to fine-tune and evaluate QA models. Apart from directly generating responses through fine-tuned models, we further explore the explicit use of Intermediate Steps for Lists (ISL), aligning list items with user backgrounds to better reflect how humans interpret list items before generating responses. Our experimental results demonstrate that models trained on LIST2QA with our ISL approach outperform baselines across various metrics. Specifically, our fine-tuned Flan-T5-XL model shows increases of 3.1% in ROUGE-L, 4.6% in correctness, 4.5% in faithfulness, and 20.6% in completeness compared to models without applying filtering and the proposed ISL method.
TofuEval: Evaluating Hallucinations of LLMs on Topic-Focused Dialogue Summarization
Feb 20, 2024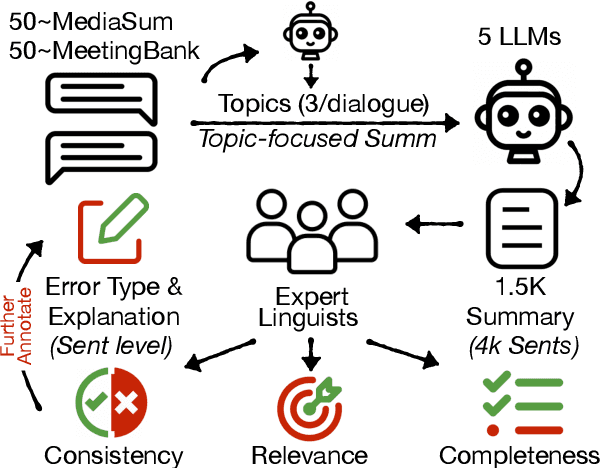


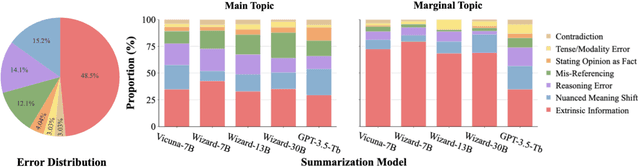
Single document news summarization has seen substantial progress on faithfulness in recent years, driven by research on the evaluation of factual consistency, or hallucinations. We ask whether these advances carry over to other text summarization domains. We propose a new evaluation benchmark on topic-focused dialogue summarization, generated by LLMs of varying sizes. We provide binary sentence-level human annotations of the factual consistency of these summaries along with detailed explanations of factually inconsistent sentences. Our analysis shows that existing LLMs hallucinate significant amounts of factual errors in the dialogue domain, regardless of the model's size. On the other hand, when LLMs, including GPT-4, serve as binary factual evaluators, they perform poorly and can be outperformed by prevailing state-of-the-art specialized factuality evaluation metrics. Finally, we conducted an analysis of hallucination types with a curated error taxonomy. We find that there are diverse errors and error distributions in model-generated summaries and that non-LLM based metrics can capture all error types better than LLM-based evaluators.
DFEE: Interactive DataFlow Execution and Evaluation Kit
Dec 04, 2022DataFlow has been emerging as a new paradigm for building task-oriented chatbots due to its expressive semantic representations of the dialogue tasks. Despite the availability of a large dataset SMCalFlow and a simplified syntax, the development and evaluation of DataFlow-based chatbots remain challenging due to the system complexity and the lack of downstream toolchains. In this demonstration, we present DFEE, an interactive DataFlow Execution and Evaluation toolkit that supports execution, visualization and benchmarking of semantic parsers given dialogue input and backend database. We demonstrate the system via a complex dialog task: event scheduling that involves temporal reasoning. It also supports diagnosing the parsing results via a friendly interface that allows developers to examine dynamic DataFlow and the corresponding execution results. To illustrate how to benchmark SoTA models, we propose a novel benchmark that covers more sophisticated event scheduling scenarios and a new metric on task success evaluation. The codes of DFEE have been released on https://github.com/amazonscience/dataflow-evaluation-toolkit.
DG2: Data Augmentation Through Document Grounded Dialogue Generation
Dec 15, 2021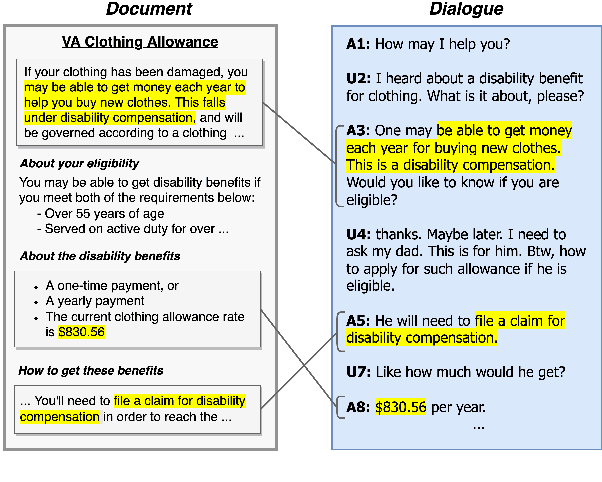
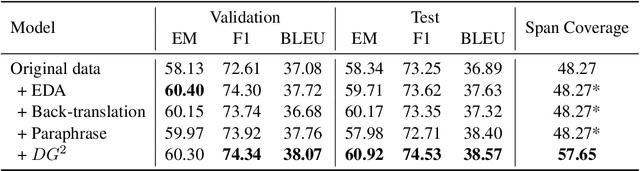
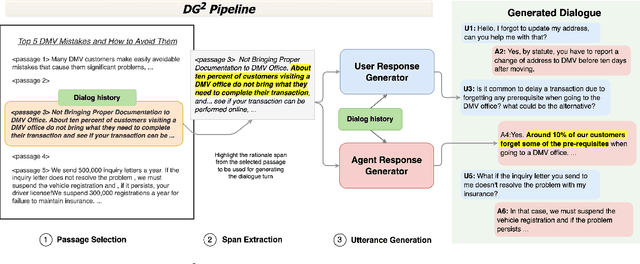
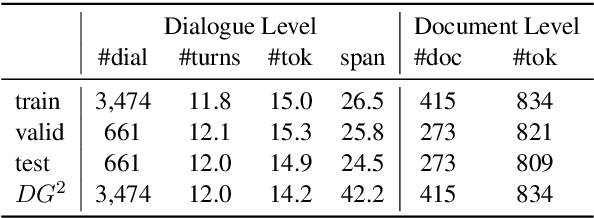
Collecting data for training dialog systems can be extremely expensive due to the involvement of human participants and need for extensive annotation. Especially in document-grounded dialog systems, human experts need to carefully read the unstructured documents to answer the users' questions. As a result, existing document-grounded dialog datasets are relatively small-scale and obstruct the effective training of dialogue systems. In this paper, we propose an automatic data augmentation technique grounded on documents through a generative dialogue model. The dialogue model consists of a user bot and agent bot that can synthesize diverse dialogues given an input document, which are then used to train a downstream model. When supplementing the original dataset, our method achieves significant improvement over traditional data augmentation methods. We also achieve great performance in the low-resource setting.
MultiDoc2Dial: Modeling Dialogues Grounded in Multiple Documents
Sep 26, 2021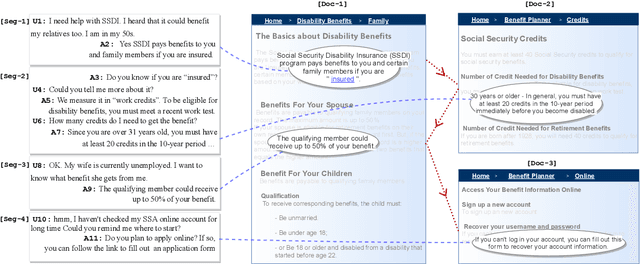
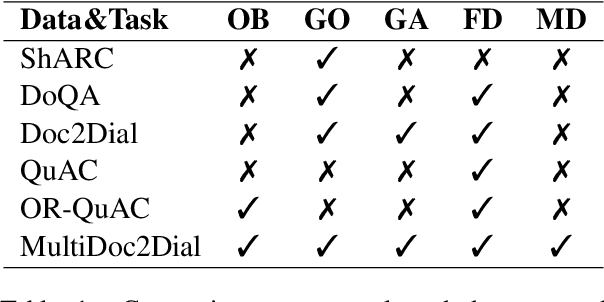
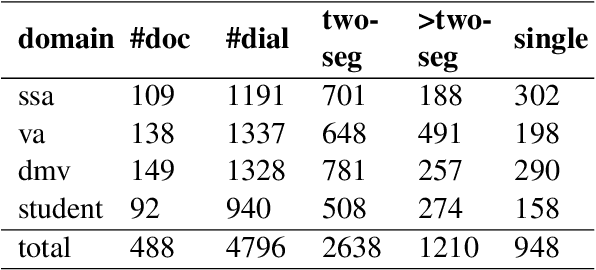
We propose MultiDoc2Dial, a new task and dataset on modeling goal-oriented dialogues grounded in multiple documents. Most previous works treat document-grounded dialogue modeling as a machine reading comprehension task based on a single given document or passage. In this work, we aim to address more realistic scenarios where a goal-oriented information-seeking conversation involves multiple topics, and hence is grounded on different documents. To facilitate such a task, we introduce a new dataset that contains dialogues grounded in multiple documents from four different domains. We also explore modeling the dialogue-based and document-based context in the dataset. We present strong baseline approaches and various experimental results, aiming to support further research efforts on such a task.
Explaining Neural Network Predictions on Sentence Pairs via Learning Word-Group Masks
Apr 13, 2021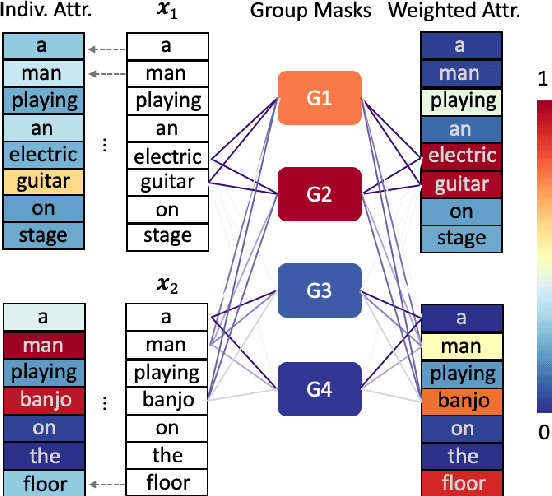
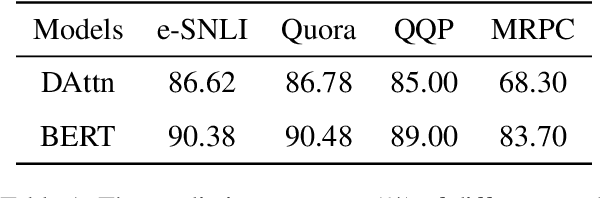
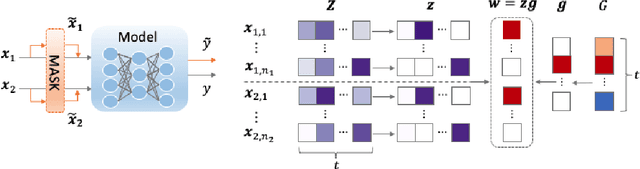
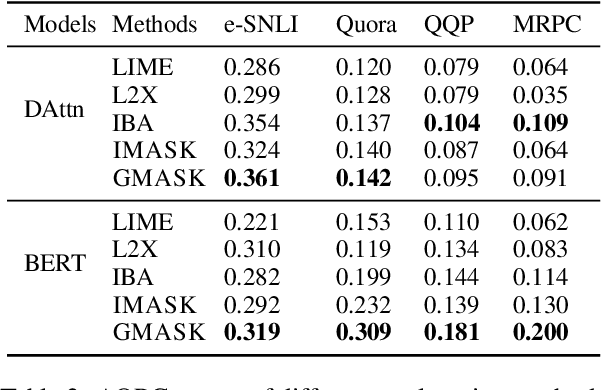
Explaining neural network models is important for increasing their trustworthiness in real-world applications. Most existing methods generate post-hoc explanations for neural network models by identifying individual feature attributions or detecting interactions between adjacent features. However, for models with text pairs as inputs (e.g., paraphrase identification), existing methods are not sufficient to capture feature interactions between two texts and their simple extension of computing all word-pair interactions between two texts is computationally inefficient. In this work, we propose the Group Mask (GMASK) method to implicitly detect word correlations by grouping correlated words from the input text pair together and measure their contribution to the corresponding NLP tasks as a whole. The proposed method is evaluated with two different model architectures (decomposable attention model and BERT) across four datasets, including natural language inference and paraphrase identification tasks. Experiments show the effectiveness of GMASK in providing faithful explanations to these models.
doc2dial: A Goal-Oriented Document-Grounded Dialogue Dataset
Nov 18, 2020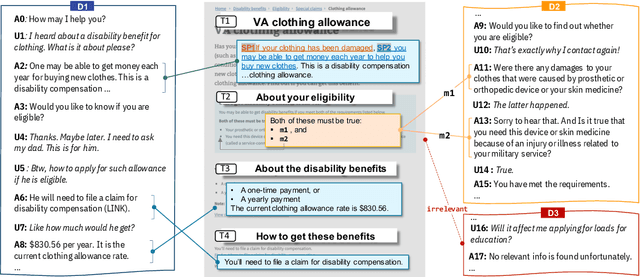
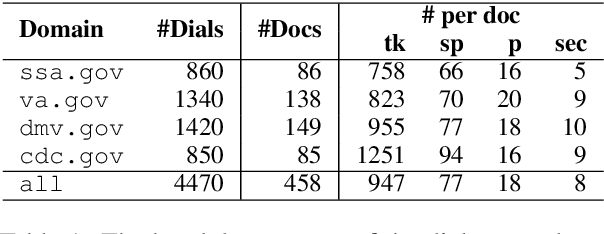
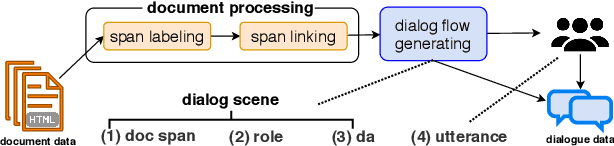
We introduce doc2dial, a new dataset of goal-oriented dialogues that are grounded in the associated documents. Inspired by how the authors compose documents for guiding end users, we first construct dialogue flows based on the content elements that corresponds to higher-level relations across text sections as well as lower-level relations between discourse units within a section. Then we present these dialogue flows to crowd contributors to create conversational utterances. The dataset includes about 4800 annotated conversations with an average of 14 turns that are grounded in over 480 documents from four domains. Compared to the prior document-grounded dialogue datasets, this dataset covers a variety of dialogue scenes in information-seeking conversations. For evaluating the versatility of the dataset, we introduce multiple dialogue modeling tasks and present baseline approaches.
Learning Lane Graph Representations for Motion Forecasting
Jul 27, 2020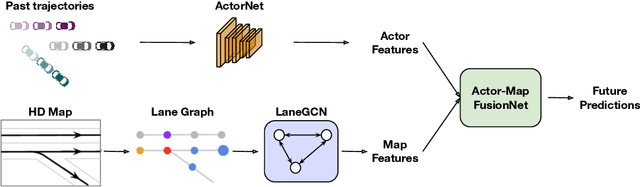


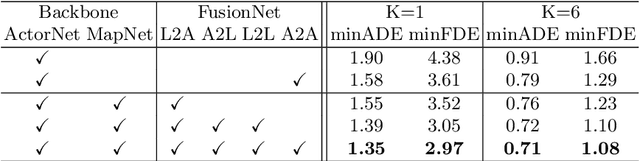
We propose a motion forecasting model that exploits a novel structured map representation as well as actor-map interactions. Instead of encoding vectorized maps as raster images, we construct a lane graph from raw map data to explicitly preserve the map structure. To capture the complex topology and long range dependencies of the lane graph, we propose LaneGCN which extends graph convolutions with multiple adjacency matrices and along-lane dilation. To capture the complex interactions between actors and maps, we exploit a fusion network consisting of four types of interactions, actor-to-lane, lane-to-lane, lane-to-actor and actor-to-actor. Powered by LaneGCN and actor-map interactions, our model is able to predict accurate and realistic multi-modal trajectories. Our approach significantly outperforms the state-of-the-art on the large scale Argoverse motion forecasting benchmark.
MultiXNet: Multiclass Multistage Multimodal Motion Prediction
Jun 10, 2020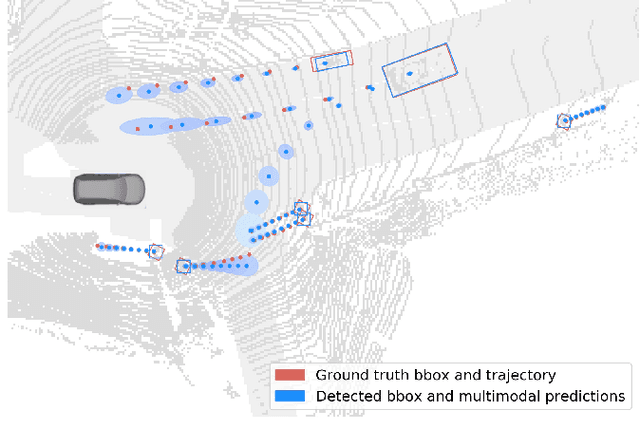
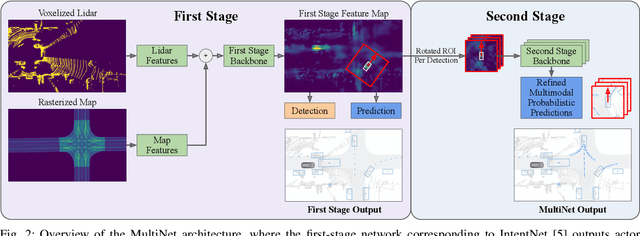
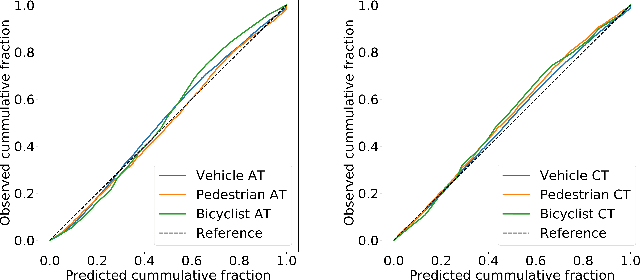
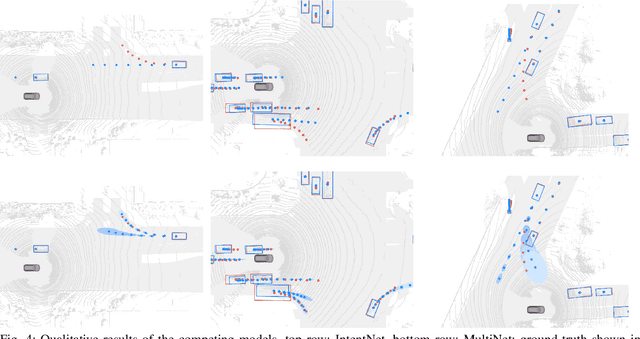
One of the critical pieces of the self-driving puzzle is understanding the surroundings of the self-driving vehicle (SDV) and predicting how these surroundings will change in the near future. To address this task we propose MultiXNet, an end-to-end approach for detection and motion prediction based directly on lidar sensor data. This approach builds on prior work by handling multiple classes of traffic actors, adding a jointly trained second-stage trajectory refinement step, and producing a multimodal probability distribution over future actor motion that includes both multiple discrete traffic behaviors and calibrated continuous uncertainties. The method was evaluated on a large-scale, real-world data set collected by a fleet of SDVs in several cities, with the results indicating that it outperforms existing state-of-the-art approaches.