 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Characterization and Evaluation of Screw-Based Locomotion Across Aquatic, Granular, and Transitional Media
Nov 15, 2025Screw-based propulsion systems offer promising capabilities for amphibious mobility, yet face significant challenges in optimizing locomotion across water, granular materials, and transitional environments. This study presents a systematic investigation into the locomotion performance of various screw configurations in media such as dry sand, wet sand, saturated sand, and water. Through a principles-first approach to analyze screw performance, it was found that certain parameters are dominant in their impact on performance. Depending on the media, derived parameters inspired from optimizing heat sink design help categorize performance within the dominant design parameters. Our results provide specific insights into screw shell design and adaptive locomotion strategies to enhance the performance of screw-based propulsion systems for versatile amphibious applications.
CRANE: A Redundant, Multi-Degree-of-Freedom Computed Tomography Robot for Heightened Needle Dexterity within a Medical Imaging Bore
Feb 05, 2024Computed Tomography (CT) image guidance enables accurate and safe minimally invasive treatment of diseases, including cancer and chronic pain, with needle-like tools via a percutaneous approach. The physician incrementally inserts and adjusts the needle with intermediate images due to the accuracy limitation of free-hand adjustment and patient physiological motion. Scanning frequency is limited to minimize ionizing radiation exposure for the patient and physician. Robots can provide high positional accuracy and compensate for physiological motion with fewer scans. To accomplish this, the robots must operate within the confined imaging bore while retaining sufficient dexterity to insert and manipulate the needle. This paper presents CRANE: CT Robotic Arm and Needle Emplacer, a CT-compatible robot with a design focused on system dexterity that enables physicians to manipulate and insert needles within the scanner bore as naturally as they would be able to by hand. We define abstract and measurable clinically motivated metrics for in-bore dexterity applicable to general-purpose intra-bore image-guided needle placement robots, develop an automatic robot planning and control method for intra-bore needle manipulation and device setup, and demonstrate the redundant linkage design provides dexterity across various human morphology and meets the clinical requirements for target accuracy during an in-situ evaluation.
Symbolic Planning and Code Generation for Grounded Dialogue
Oct 26, 2023



Large language models (LLMs) excel at processing and generating both text and code. However, LLMs have had limited applicability in grounded task-oriented dialogue as they are difficult to steer toward task objectives and fail to handle novel grounding. We present a modular and interpretable grounded dialogue system that addresses these shortcomings by composing LLMs with a symbolic planner and grounded code execution. Our system consists of a reader and planner: the reader leverages an LLM to convert partner utterances into executable code, calling functions that perform grounding. The translated code's output is stored to track dialogue state, while a symbolic planner determines the next appropriate response. We evaluate our system's performance on the demanding OneCommon dialogue task, involving collaborative reference resolution on abstract images of scattered dots. Our system substantially outperforms the previous state-of-the-art, including improving task success in human evaluations from 56% to 69% in the most challenging setting.
Using Textual Interface to Align External Knowledge for End-to-End Task-Oriented Dialogue Systems
May 23, 2023



Traditional end-to-end task-oriented dialogue systems have been built with a modularized design. However, such design often causes misalignment between the agent response and external knowledge, due to inadequate representation of information. Furthermore, its evaluation metrics emphasize assessing the agent's pre-lexicalization response, neglecting the quality of the completed response. In this work, we propose a novel paradigm that uses a textual interface to align external knowledge and eliminate redundant processes. We demonstrate our paradigm in practice through MultiWOZ-Remake, including an interactive textual interface built for the MultiWOZ database and a correspondingly re-processed dataset. We train an end-to-end dialogue system to evaluate this new dataset. The experimental results show that our approach generates more natural final responses and achieves a greater task success rate compared to the previous models.
Mixture of Soft Prompts for Controllable Data Generation
Mar 02, 2023



Large language models (LLMs) effectively generate fluent text when the target output follows natural language patterns. However, structured prediction tasks confine the output format to a limited ontology, causing even very large models to struggle since they were never trained with such restrictions in mind. The difficulty of using LLMs for direct prediction is exacerbated in few-shot learning scenarios, which commonly arise due to domain shift and resource limitations. We flip the problem on its head by leveraging the LLM as a tool for data augmentation rather than direct prediction. Our proposed Mixture of Soft Prompts (MSP) serves as a parameter-efficient procedure for generating data in a controlled manner. Denoising mechanisms are further applied to improve the quality of synthesized data. Automatic metrics show our method is capable of producing diverse and natural text, while preserving label semantics. Moreover, MSP achieves state-of-the-art results on three benchmarks when compared against strong baselines. Our method offers an alternate data-centric approach for applying LLMs to complex prediction tasks.
Stabilized In-Context Learning with Pre-trained Language Models for Few Shot Dialogue State Tracking
Feb 12, 2023



Prompt-based methods with large pre-trained language models (PLMs) have shown impressive unaided performance across many NLP tasks. These models improve even further with the addition of a few labeled in-context exemplars to guide output generation. However, for more complex tasks such as dialogue state tracking (DST), designing prompts that reliably convey the desired intent is nontrivial, leading to unstable results. Furthermore, building in-context exemplars for dialogue tasks is difficult because conversational contexts are long while model input lengths are relatively short. To overcome these issues we first adapt a meta-learning scheme to the dialogue domain which stabilizes the ability of the model to perform well under various prompts. We additionally design a novel training method to improve upon vanilla retrieval mechanisms to find ideal in-context examples. Finally, we introduce a saliency model to limit dialogue text length, allowing us to include more exemplars per query. In effect, we are able to achieve highly competitive results for few-shot DST on MultiWOZ.
Sources of Noise in Dialogue and How to Deal with Them
Dec 06, 2022



Training dialogue systems often entails dealing with noisy training examples and unexpected user inputs. Despite their prevalence, there currently lacks an accurate survey of dialogue noise, nor is there a clear sense of the impact of each noise type on task performance. This paper addresses this gap by first constructing a taxonomy of noise encountered by dialogue systems. In addition, we run a series of experiments to show how different models behave when subjected to varying levels of noise and types of noise. Our results reveal that models are quite robust to label errors commonly tackled by existing denoising algorithms, but that performance suffers from dialogue-specific noise. Driven by these observations, we design a data cleaning algorithm specialized for conversational settings and apply it as a proof-of-concept for targeted dialogue denoising.
Data Augmentation for Intent Classification
Jun 12, 2022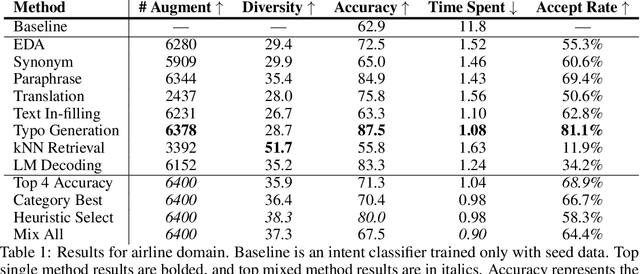
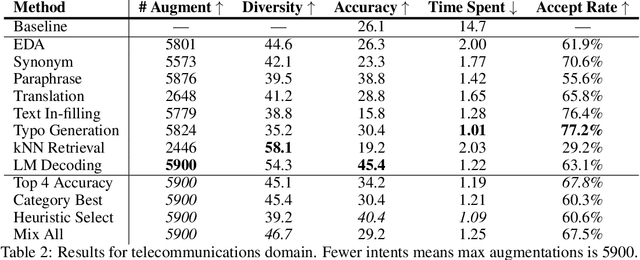
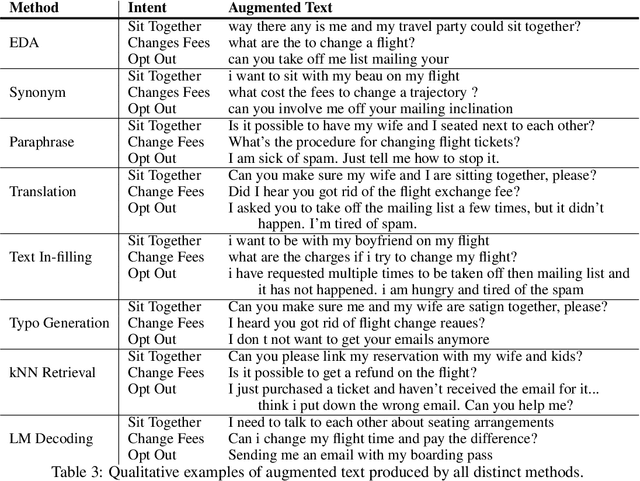
Training accurate intent classifiers requires labeled data, which can be costly to obtain. Data augmentation methods may ameliorate this issue, but the quality of the generated data varies significantly across techniques. We study the process of systematically producing pseudo-labeled data given a small seed set using a wide variety of data augmentation techniques, including mixing methods together. We find that while certain methods dramatically improve qualitative and quantitative performance, other methods have minimal or even negative impact. We also analyze key considerations when implementing data augmentation methods in production.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.